 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Meta-Features with Knowledge Graph Embeddings for Meta-Learning
Mar 20, 2026The vast collection of machine learning records available on the web presents a significant opportunity for meta-learning, where past experiments are leveraged to improve performance. Two crucial meta-learning tasks are pipeline performance estimation (PPE), which predicts pipeline performance on target datasets, and dataset performance-based similarity estimation (DPSE), which identifies datasets with similar performance patterns. Existing approaches primarily rely on dataset meta-features (e.g., number of instances, class entropy, etc.) to represent datasets numerically and approximate these meta-learning tasks. However, these approaches often overlook the wealth of past experimental results and pipeline metadata available. This limits their ability to capture dataset - pipeline interactions that reveal performance similarity patterns. In this work, we propose KGmetaSP, a knowledge-graph-embeddings approach that leverages existing experiment data to capture these interactions and improve both PPE and DPSE. We represent datasets and pipelines within a unified knowledge graph (KG) and derive embeddings that support pipeline-agnostic meta-models for PPE and distance-based retrieval for DPSE. To validate our approach, we construct a large-scale benchmark comprising 144,177 OpenML experiments, enabling a rich cross-dataset evaluation. KGmetaSP enables accurate PPE using a single pipeline-agnostic meta-model and improves DPSE over baselines. The proposed KGmetaSP, KG, and benchmark are released, establishing a new reference point for meta-learning and demonstrating how consolidating open experiment data into a unified KG advances the field.
Bio-KGvec2go: Serving up-to-date Dynamic Biomedical Knowledge Graph Embeddings
Sep 09, 2025Knowledge graphs and ontologies represent entities and their relationships in a structured way, having gained significance in the development of modern AI applications. Integrating these semantic resources with machine learning models often relies on knowledge graph embedding models to transform graph data into numerical representations. Therefore, pre-trained models for popular knowledge graphs and ontologies are increasingly valuable, as they spare the need to retrain models for different tasks using the same data, thereby helping to democratize AI development and enabling sustainable computing. In this paper, we present Bio-KGvec2go, an extension of the KGvec2go Web API, designed to generate and serve knowledge graph embeddings for widely used biomedical ontologies. Given the dynamic nature of these ontologies, Bio-KGvec2go also supports regular updates aligned with ontology version releases. By offering up-to-date embeddings with minimal computational effort required from users, Bio-KGvec2go facilitates efficient and timely biomedical research.
Walk&Retrieve: Simple Yet Effective Zero-shot Retrieval-Augmented Generation via Knowledge Graph Walks
May 22, 2025Large Language Models (LLMs) have showcased impressive reasoning abilities, but often suffer from hallucinations or outdated knowledge. Knowledge Graph (KG)-based Retrieval-Augmented Generation (RAG) remedies these shortcomings by grounding LLM responses in structured external information from a knowledge base. However, many KG-based RAG approaches struggle with (i) aligning KG and textual representations, (ii) balancing retrieval accuracy and efficiency, and (iii) adapting to dynamically updated KGs. In this work, we introduce Walk&Retrieve, a simple yet effective KG-based framework that leverages walk-based graph traversal and knowledge verbalization for corpus generation for zero-shot RAG. Built around efficient KG walks, our method does not require fine-tuning on domain-specific data, enabling seamless adaptation to KG updates, reducing computational overhead, and allowing integration with any off-the-shelf backbone LLM. Despite its simplicity, Walk&Retrieve performs competitively, often outperforming existing RAG systems in response accuracy and hallucination reduction. Moreover, it demonstrates lower query latency and robust scalability to large KGs, highlighting the potential of lightweight retrieval strategies as strong baselines for future RAG research.
GeoRDF2Vec Learning Location-Aware Entity Representations in Knowledge Graphs
Apr 23, 2025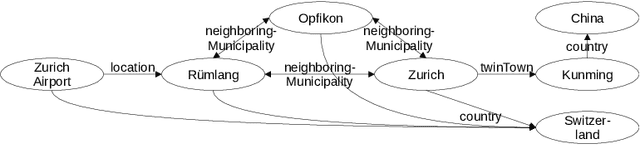



Many knowledge graphs contain a substantial number of spatial entities, such as cities, buildings, and natural landmarks. For many of these entities, exact geometries are stored within the knowledge graphs. However, most existing approaches for learning entity representations do not take these geometries into account. In this paper, we introduce a variant of RDF2Vec that incorporates geometric information to learn location-aware embeddings of entities. Our approach expands different nodes by flooding the graph from geographic nodes, ensuring that each reachable node is considered. Based on the resulting flooded graph, we apply a modified version of RDF2Vec that biases graph walks using spatial weights. Through evaluations on multiple benchmark datasets, we demonstrate that our approach outperforms both non-location-aware RDF2Vec and GeoTransE.
ReaLitE: Enrichment of Relation Embeddings in Knowledge Graphs using Numeric Literals
Apr 01, 2025



Most knowledge graph embedding (KGE) methods tailored for link prediction focus on the entities and relations in the graph, giving little attention to other literal values, which might encode important information. Therefore, some literal-aware KGE models attempt to either integrate numerical values into the embeddings of the entities or convert these numerics into entities during preprocessing, leading to information loss. Other methods concerned with creating relation-specific numerical features assume completeness of numerical data, which does not apply to real-world graphs. In this work, we propose ReaLitE, a novel relation-centric KGE model that dynamically aggregates and merges entities' numerical attributes with the embeddings of the connecting relations. ReaLitE is designed to complement existing conventional KGE methods while supporting multiple variations for numerical aggregations, including a learnable method. We comprehensively evaluated the proposed relation-centric embedding using several benchmarks for link prediction and node classification tasks. The results showed the superiority of ReaLitE over the state of the art in both tasks.
Multi-dataset and Transfer Learning Using Gene Expression Knowledge Graphs
Mar 26, 2025



Gene expression datasets offer insights into gene regulation mechanisms, biochemical pathways, and cellular functions. Additionally, comparing gene expression profiles between disease and control patients can deepen the understanding of disease pathology. Therefore, machine learning has been used to process gene expression data, with patient diagnosis emerging as one of the most popular applications. Although gene expression data can provide valuable insights, challenges arise because the number of patients in expression datasets is usually limited, and the data from different datasets with different gene expressions cannot be easily combined. This work proposes a novel methodology to address these challenges by integrating multiple gene expression datasets and domain-specific knowledge using knowledge graphs, a unique tool for biomedical data integration. Then, vector representations are produced using knowledge graph embedding techniques, which are used as inputs for a graph neural network and a multi-layer perceptron. We evaluate the efficacy of our methodology in three settings: single-dataset learning, multi-dataset learning, and transfer learning. The experimental results show that combining gene expression datasets and domain-specific knowledge improves patient diagnosis in all three settings.
Peeling Back the Layers: An In-Depth Evaluation of Encoder Architectures in Neural News Recommenders
Oct 02, 2024
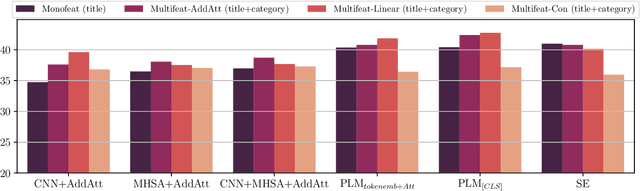
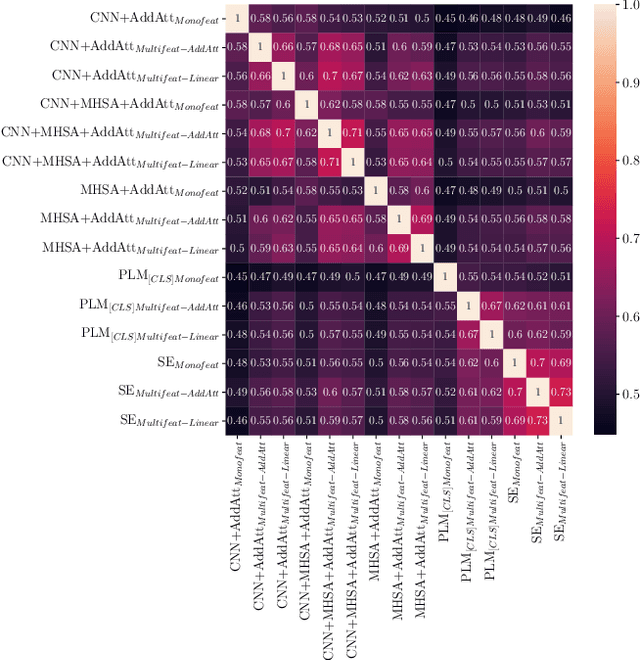
Encoder architectures play a pivotal role in neural news recommenders by embedding the semantic and contextual information of news and users. Thus, research has heavily focused on enhancing the representational capabilities of news and user encoders to improve recommender performance. Despite the significant impact of encoder architectures on the quality of news and user representations, existing analyses of encoder designs focus only on the overall downstream recommendation performance. This offers a one-sided assessment of the encoders' similarity, ignoring more nuanced differences in their behavior, and potentially resulting in sub-optimal model selection. In this work, we perform a comprehensive analysis of encoder architectures in neural news recommender systems. We systematically evaluate the most prominent news and user encoder architectures, focusing on their (i) representational similarity, measured with the Central Kernel Alignment, (ii) overlap of generated recommendation lists, quantified with the Jaccard similarity, and (iii) the overall recommendation performance. Our analysis reveals that the complexity of certain encoding techniques is often empirically unjustified, highlighting the potential for simpler, more efficient architectures. By isolating the effects of individual components, we provide valuable insights for researchers and practitioners to make better informed decisions about encoder selection and avoid unnecessary complexity in the design of news recommenders.
SnapE -- Training Snapshot Ensembles of Link Prediction Models
Aug 05, 2024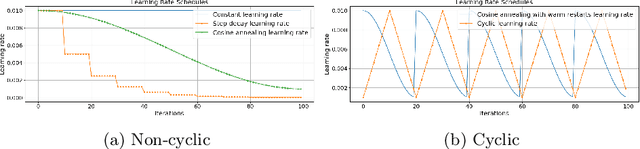
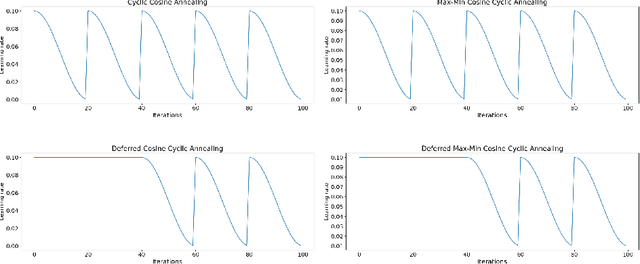

Snapshot ensembles have been widely used in various fields of prediction. They allow for training an ensemble of prediction models at the cost of training a single one. They are known to yield more robust predictions by creating a set of diverse base models. In this paper, we introduce an approach to transfer the idea of snapshot ensembles to link prediction models in knowledge graphs. Moreover, since link prediction in knowledge graphs is a setup without explicit negative examples, we propose a novel training loop that iteratively creates negative examples using previous snapshot models. An evaluation with four base models across four datasets shows that this approach constantly outperforms the single model approach, while keeping the training time constant.
Do LLMs Really Adapt to Domains? An Ontology Learning Perspective
Jul 29, 2024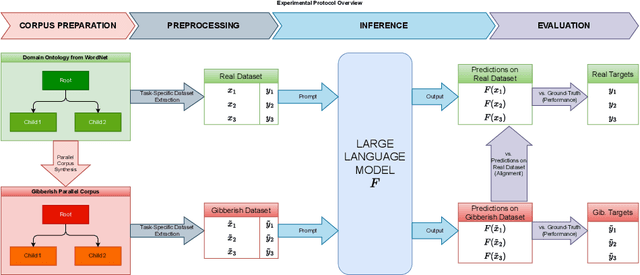
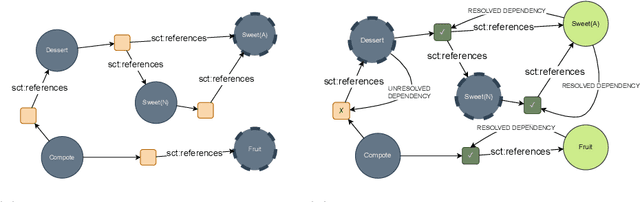

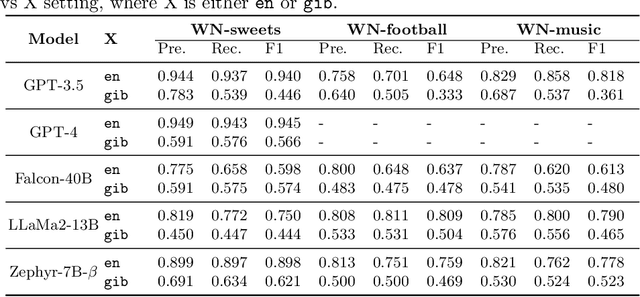
Large Language Models (LLMs) have demonstrated unprecedented prowess across various natural language processing tasks in various application domains. Recent studies show that LLMs can be leveraged to perform lexical semantic tasks, such as Knowledge Base Completion (KBC) or Ontology Learning (OL). However, it has not effectively been verified whether their success is due to their ability to reason over unstructured or semi-structured data, or their effective learning of linguistic patterns and senses alone. This unresolved question is particularly crucial when dealing with domain-specific data, where the lexical senses and their meaning can completely differ from what a LLM has learned during its training stage. This paper investigates the following question: Do LLMs really adapt to domains and remain consistent in the extraction of structured knowledge, or do they only learn lexical senses instead of reasoning? To answer this question and, we devise a controlled experiment setup that uses WordNet to synthesize parallel corpora, with English and gibberish terms. We examine the differences in the outputs of LLMs for each corpus in two OL tasks: relation extraction and taxonomy discovery. Empirical results show that, while adapting to the gibberish corpora, off-the-shelf LLMs do not consistently reason over semantic relationships between concepts, and instead leverage senses and their frame. However, fine-tuning improves the performance of LLMs on lexical semantic tasks even when the domain-specific terms are arbitrary and unseen during pre-training, hinting at the applicability of pre-trained LLMs for OL.
News Without Borders: Domain Adaptation of Multilingual Sentence Embeddings for Cross-lingual News Recommendation
Jun 18, 2024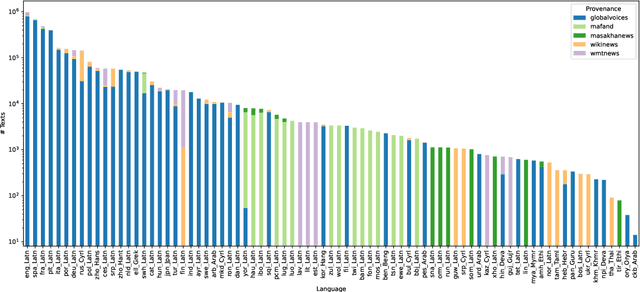
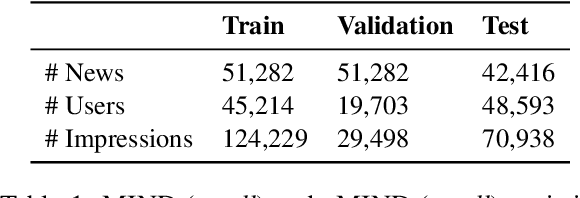
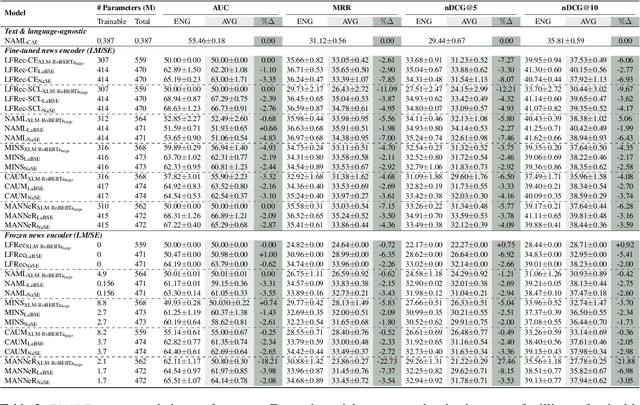
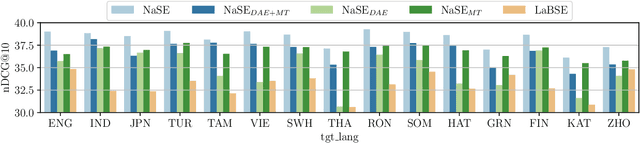
Rapidly growing numbers of multilingual news consumers pose an increasing challenge to news recommender systems in terms of providing customized recommendations. First, existing neural news recommenders, even when powered by multilingual language models (LMs), suffer substantial performance losses in zero-shot cross-lingual transfer (ZS-XLT). Second, the current paradigm of fine-tuning the backbone LM of a neural recommender on task-specific data is computationally expensive and infeasible in few-shot recommendation and cold-start setups, where data is scarce or completely unavailable. In this work, we propose a news-adapted sentence encoder (NaSE), domain-specialized from a pretrained massively multilingual sentence encoder (SE). To this end, we construct and leverage PolyNews and PolyNewsParallel, two multilingual news-specific corpora. With the news-adapted multilingual SE in place, we test the effectiveness of (i.e., question the need for) supervised fine-tuning for news recommendation, and propose a simple and strong baseline based on (i) frozen NaSE embeddings and (ii) late click-behavior fusion. We show that NaSE achieves state-of-the-art performance in ZS-XLT in true cold-start and few-shot news recommendation.