 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReaLitE: Enrichment of Relation Embeddings in Knowledge Graphs using Numeric Literals
Apr 01, 2025



Most knowledge graph embedding (KGE) methods tailored for link prediction focus on the entities and relations in the graph, giving little attention to other literal values, which might encode important information. Therefore, some literal-aware KGE models attempt to either integrate numerical values into the embeddings of the entities or convert these numerics into entities during preprocessing, leading to information loss. Other methods concerned with creating relation-specific numerical features assume completeness of numerical data, which does not apply to real-world graphs. In this work, we propose ReaLitE, a novel relation-centric KGE model that dynamically aggregates and merges entities' numerical attributes with the embeddings of the connecting relations. ReaLitE is designed to complement existing conventional KGE methods while supporting multiple variations for numerical aggregations, including a learnable method. We comprehensively evaluated the proposed relation-centric embedding using several benchmarks for link prediction and node classification tasks. The results showed the superiority of ReaLitE over the state of the art in both tasks.
Real-Time Event Detection with Random Forests and Temporal Convolutional Networks for More Sustainable Petroleum Industry
Oct 12, 2023



The petroleum industry is crucial for modern society, but the production process is complex and risky. During the production, accidents or failures, resulting from undesired production events, can cause severe environmental and economic damage. Previous studies have investigated machine learning (ML) methods for undesired event detection. However, the prediction of event probability in real-time was insufficiently addressed, which is essential since it is important to undertake early intervention when an event is expected to happen. This paper proposes two ML approaches, random forests and temporal convolutional networks, to detect undesired events in real-time. Results show that our approaches can effectively classify event types and predict the probability of their appearance, addressing the challenges uncovered in previous studies and providing a more effective solution for failure event management during the production.
Literal-Aware Knowledge Graph Embedding for Welding Quality Monitoring: A Bosch Case
Aug 02, 2023



Recently there has been a series of studies in knowledge graph embedding (KGE), which attempts to learn the embeddings of the entities and relations as numerical vectors and mathematical mappings via machine learning (ML). However, there has been limited research that applies KGE for industrial problems in manufacturing. This paper investigates whether and to what extent KGE can be used for an important problem: quality monitoring for welding in manufacturing industry, which is an impactful process accounting for production of millions of cars annually. The work is in line with Bosch research of data-driven solutions that intends to replace the traditional way of destroying cars, which is extremely costly and produces waste. The paper tackles two very challenging questions simultaneously: how large the welding spot diameter is; and to which car body the welded spot belongs to. The problem setting is difficult for traditional ML because there exist a high number of car bodies that should be assigned as class labels. We formulate the problem as link prediction, and experimented popular KGE methods on real industry data, with consideration of literals. Our results reveal both limitations and promising aspects of adapted KGE methods.
Scaling Data Science Solutions with Semantics and Machine Learning: Bosch Case
Aug 02, 2023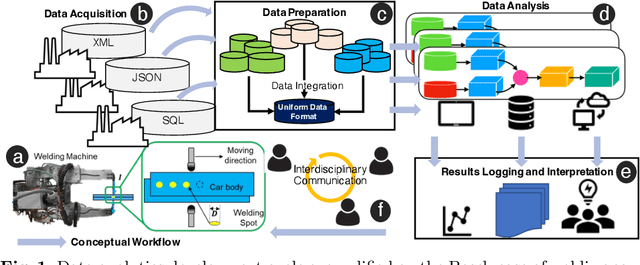
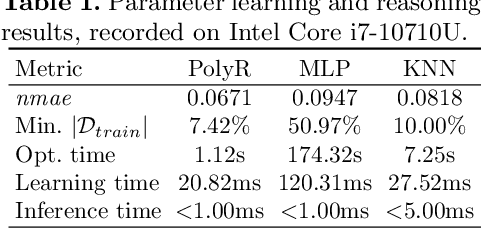
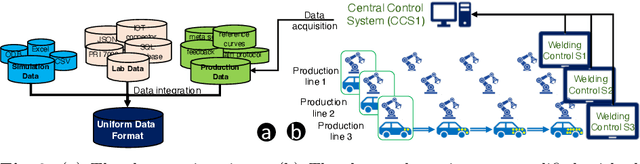
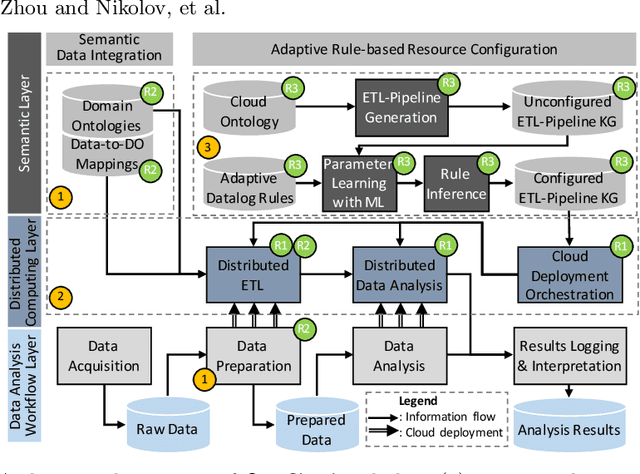
Industry 4.0 and Internet of Things (IoT) technologies unlock unprecedented amount of data from factory production, posing big data challenges in volume and variety. In that context, distributed computing solutions such as cloud systems are leveraged to parallelise the data processing and reduce computation time. As the cloud systems become increasingly popular, there is increased demand that more users that were originally not cloud experts (such as data scientists, domain experts) deploy their solutions on the cloud systems. However, it is non-trivial to address both the high demand for cloud system users and the excessive time required to train them. To this end, we propose SemCloud, a semantics-enhanced cloud system, that couples cloud system with semantic technologies and machine learning. SemCloud relies on domain ontologies and mappings for data integration, and parallelises the semantic data integration and data analysis on distributed computing nodes. Furthermore, SemCloud adopts adaptive Datalog rules and machine learning for automated resource configuration, allowing non-cloud experts to use the cloud system. The system has been evaluated in industrial use case with millions of data, thousands of repeated runs, and domain users, showing promising results.
ExeKGLib: Knowledge Graphs-Empowered Machine Learning Analytics
May 04, 2023


Many machine learning (ML) libraries are accessible online for ML practitioners. Typical ML pipelines are complex and consist of a series of steps, each of them invoking several ML libraries. In this demo paper, we present ExeKGLib, a Python library that allows users with coding skills and minimal ML knowledge to build ML pipelines. ExeKGLib relies on knowledge graphs to improve the transparency and reusability of the built ML workflows, and to ensure that they are executable. We demonstrate the usage of ExeKGLib and compare it with conventional ML code to show its benefits.
Query-based Industrial Analytics over Knowledge Graphs with Ontology Reshaping
Sep 22, 2022Industrial analytics that includes among others equipment diagnosis and anomaly detection heavily relies on integration of heterogeneous production data. Knowledge Graphs (KGs) as the data format and ontologies as the unified data schemata are a prominent solution that offers high quality data integration and a convenient and standardised way to exchange data and to layer analytical applications over it. However, poor design of ontologies of high degree of mismatch between them and industrial data naturally lead to KGs of low quality that impede the adoption and scalability of industrial analytics. Indeed, such KGs substantially increase the training time of writing queries for users, consume high volume of storage for redundant information, and are hard to maintain and update. To address this problem we propose an ontology reshaping approach to transform ontologies into KG schemata that better reflect the underlying data and thus help to construct better KGs. In this poster we present a preliminary discussion of our on-going research, evaluate our approach with a rich set of SPARQL queries on real-world industry data at Bosch and discuss our findings.
Towards Ontology Reshaping for KG Generation with User-in-the-Loop: Applied to Bosch Welding
Sep 22, 2022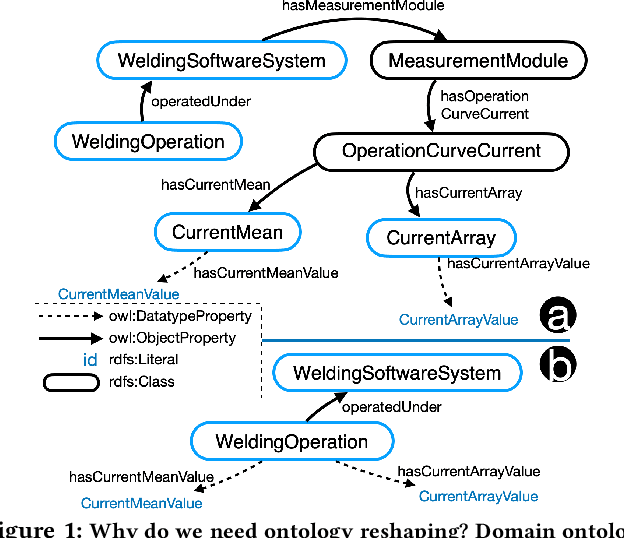
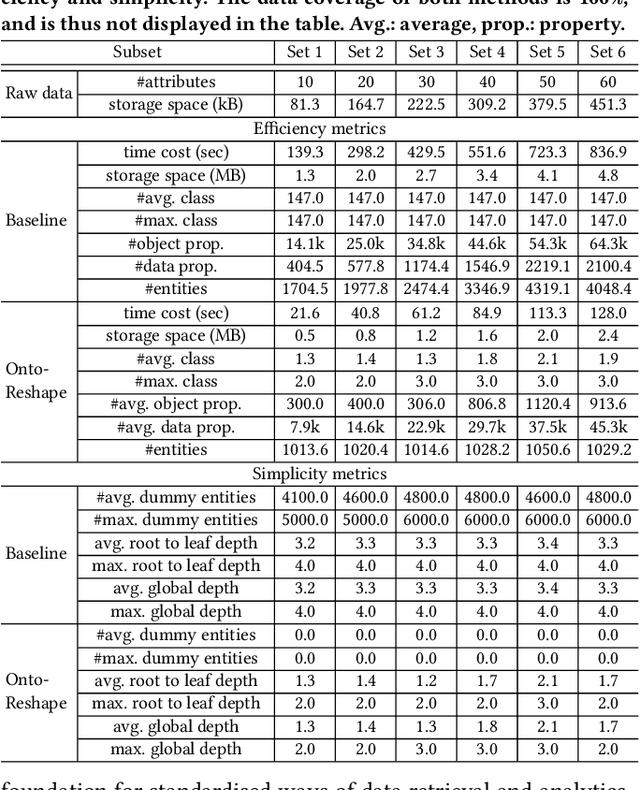
Knowledge graphs (KG) are used in a wide range of applications. The automation of KG generation is very desired due to the data volume and variety in industries. One important approach of KG generation is to map the raw data to a given KG schema, namely a domain ontology, and construct the entities and properties according to the ontology. However, the automatic generation of such ontology is demanding and existing solutions are often not satisfactory. An important challenge is a trade-off between two principles of ontology engineering: knowledge-orientation and data-orientation. The former one prescribes that an ontology should model the general knowledge of a domain, while the latter one emphasises on reflecting the data specificities to ensure good usability. We address this challenge by our method of ontology reshaping, which automates the process of converting a given domain ontology to a smaller ontology that serves as the KG schema. The domain ontology can be designed to be knowledge-oriented and the KG schema covers the data specificities. In addition, our approach allows the option of including user preferences in the loop. We demonstrate our on-going research on ontology reshaping and present an evaluation using real industrial data, with promising results.