 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGR-Agent: Adaptive Graph Reasoning Agent under Incomplete Knowledge
Dec 16, 2025

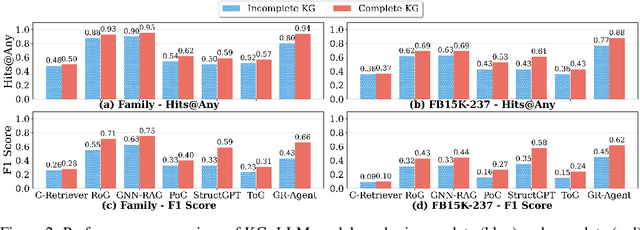

Large language models (LLMs) achieve strong results on knowledge graph question answering (KGQA), but most benchmarks assume complete knowledge graphs (KGs) where direct supporting triples exist. This reduces evaluation to shallow retrieval and overlooks the reality of incomplete KGs, where many facts are missing and answers must be inferred from existing facts. We bridge this gap by proposing a methodology for constructing benchmarks under KG incompleteness, which removes direct supporting triples while ensuring that alternative reasoning paths required to infer the answer remain. Experiments on benchmarks constructed using our methodology show that existing methods suffer consistent performance degradation under incompleteness, highlighting their limited reasoning ability. To overcome this limitation, we present the Adaptive Graph Reasoning Agent (GR-Agent). It first constructs an interactive environment from the KG, and then formalizes KGQA as agent environment interaction within this environment. GR-Agent operates over an action space comprising graph reasoning tools and maintains a memory of potential supporting reasoning evidence, including relevant relations and reasoning paths. Extensive experiments demonstrate that GR-Agent outperforms non-training baselines and performs comparably to training-based methods under both complete and incomplete settings.
What Breaks Knowledge Graph based RAG? Empirical Insights into Reasoning under Incomplete Knowledge
Aug 11, 2025Knowledge Graph-based Retrieval-Augmented Generation (KG-RAG) is an increasingly explored approach for combining the reasoning capabilities of large language models with the structured evidence of knowledge graphs. However, current evaluation practices fall short: existing benchmarks often include questions that can be directly answered using existing triples in KG, making it unclear whether models perform reasoning or simply retrieve answers directly. Moreover, inconsistent evaluation metrics and lenient answer matching criteria further obscure meaningful comparisons. In this work, we introduce a general method for constructing benchmarks, together with an evaluation protocol, to systematically assess KG-RAG methods under knowledge incompleteness. Our empirical results show that current KG-RAG methods have limited reasoning ability under missing knowledge, often rely on internal memorization, and exhibit varying degrees of generalization depending on their design.
Evaluating Knowledge Graph Based Retrieval Augmented Generation Methods under Knowledge Incompleteness
Apr 07, 2025

Knowledge Graph based Retrieval-Augmented Generation (KG-RAG) is a technique that enhances Large Language Model (LLM) inference in tasks like Question Answering (QA) by retrieving relevant information from knowledge graphs (KGs). However, real-world KGs are often incomplete, meaning that essential information for answering questions may be missing. Existing benchmarks do not adequately capture the impact of KG incompleteness on KG-RAG performance. In this paper, we systematically evaluate KG-RAG methods under incomplete KGs by removing triples using different methods and analyzing the resulting effects. We demonstrate that KG-RAG methods are sensitive to KG incompleteness, highlighting the need for more robust approaches in realistic settings.
Alleviating Over-Smoothing via Aggregation over Compact Manifolds
Jul 27, 2024Graph neural networks (GNNs) have achieved significant success in various applications. Most GNNs learn the node features with information aggregation of its neighbors and feature transformation in each layer. However, the node features become indistinguishable after many layers, leading to performance deterioration: a significant limitation known as over-smoothing. Past work adopted various techniques for addressing this issue, such as normalization and skip-connection of layer-wise output. After the study, we found that the information aggregations in existing work are all contracted aggregations, with the intrinsic property that features will inevitably converge to the same single point after many layers. To this end, we propose the aggregation over compacted manifolds method (ACM) that replaces the existing information aggregation with aggregation over compact manifolds, a special type of manifold, which avoids contracted aggregations. In this work, we theoretically analyze contracted aggregation and its properties. We also provide an extensive empirical evaluation that shows ACM can effectively alleviate over-smoothing and outperforms the state-of-the-art. The code can be found in https://github.com/DongzhuoranZhou/ACM.git.
Query-based Industrial Analytics over Knowledge Graphs with Ontology Reshaping
Sep 22, 2022Industrial analytics that includes among others equipment diagnosis and anomaly detection heavily relies on integration of heterogeneous production data. Knowledge Graphs (KGs) as the data format and ontologies as the unified data schemata are a prominent solution that offers high quality data integration and a convenient and standardised way to exchange data and to layer analytical applications over it. However, poor design of ontologies of high degree of mismatch between them and industrial data naturally lead to KGs of low quality that impede the adoption and scalability of industrial analytics. Indeed, such KGs substantially increase the training time of writing queries for users, consume high volume of storage for redundant information, and are hard to maintain and update. To address this problem we propose an ontology reshaping approach to transform ontologies into KG schemata that better reflect the underlying data and thus help to construct better KGs. In this poster we present a preliminary discussion of our on-going research, evaluate our approach with a rich set of SPARQL queries on real-world industry data at Bosch and discuss our findings.
Towards Ontology Reshaping for KG Generation with User-in-the-Loop: Applied to Bosch Welding
Sep 22, 2022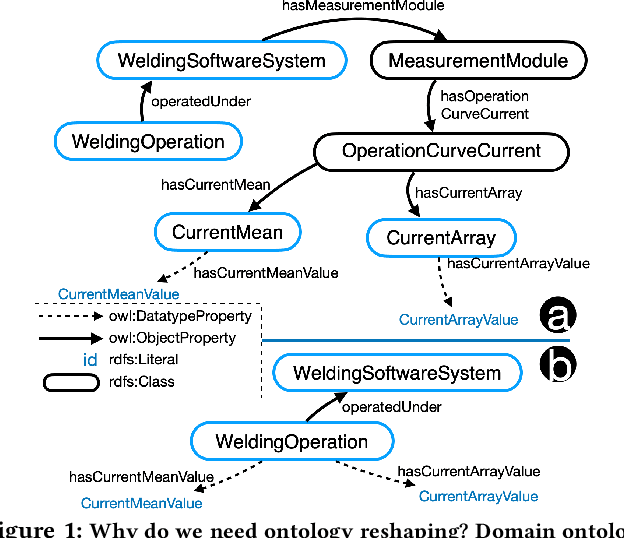
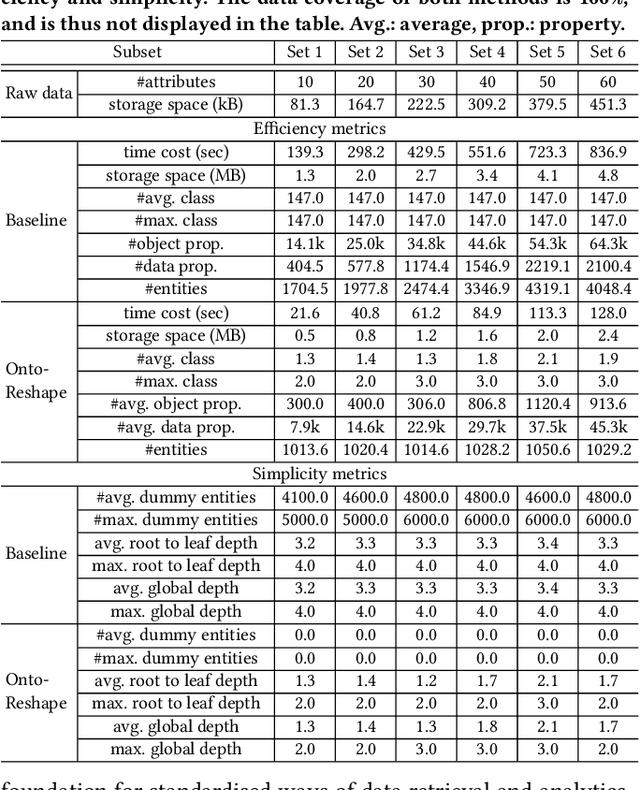
Knowledge graphs (KG) are used in a wide range of applications. The automation of KG generation is very desired due to the data volume and variety in industries. One important approach of KG generation is to map the raw data to a given KG schema, namely a domain ontology, and construct the entities and properties according to the ontology. However, the automatic generation of such ontology is demanding and existing solutions are often not satisfactory. An important challenge is a trade-off between two principles of ontology engineering: knowledge-orientation and data-orientation. The former one prescribes that an ontology should model the general knowledge of a domain, while the latter one emphasises on reflecting the data specificities to ensure good usability. We address this challenge by our method of ontology reshaping, which automates the process of converting a given domain ontology to a smaller ontology that serves as the KG schema. The domain ontology can be designed to be knowledge-oriented and the KG schema covers the data specificities. In addition, our approach allows the option of including user preferences in the loop. We demonstrate our on-going research on ontology reshaping and present an evaluation using real industrial data, with promising results.
Specializing Versatile Skill Libraries using Local Mixture of Experts
Jan 10, 2022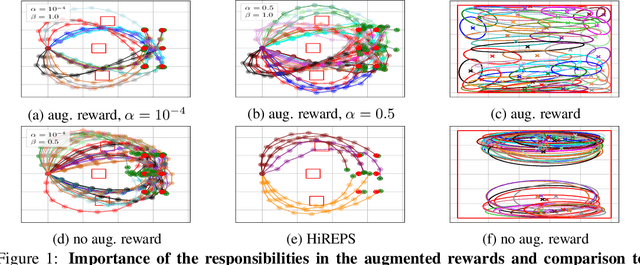
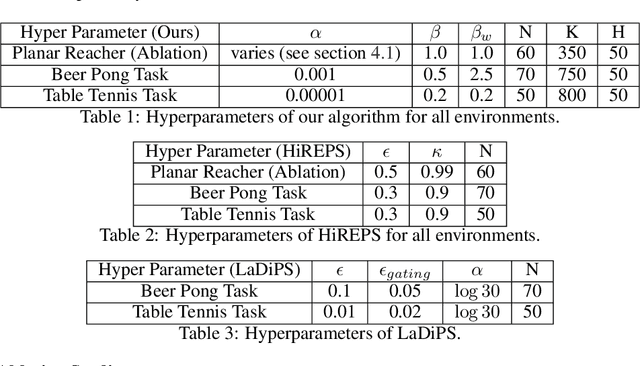


A long-cherished vision in robotics is to equip robots with skills that match the versatility and precision of humans. For example, when playing table tennis, a robot should be capable of returning the ball in various ways while precisely placing it at the desired location. A common approach to model such versatile behavior is to use a Mixture of Experts (MoE) model, where each expert is a contextual motion primitive. However, learning such MoEs is challenging as most objectives force the model to cover the entire context space, which prevents specialization of the primitives resulting in rather low-quality components. Starting from maximum entropy reinforcement learning (RL), we decompose the objective into optimizing an individual lower bound per mixture component. Further, we introduce a curriculum by allowing the components to focus on a local context region, enabling the model to learn highly accurate skill representations. To this end, we use local context distributions that are adapted jointly with the expert primitives. Our lower bound advocates an iterative addition of new components, where new components will concentrate on local context regions not covered by the current MoE. This local and incremental learning results in a modular MoE model of high accuracy and versatility, where both properties can be scaled by adding more components on the fly. We demonstrate this by an extensive ablation and on two challenging simulated robot skill learning tasks. We compare our achieved performance to LaDiPS and HiREPS, a known hierarchical policy search method for learning diverse skills.