 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaffolding Dexterous Manipulation with Vision-Language Models
Jun 24, 2025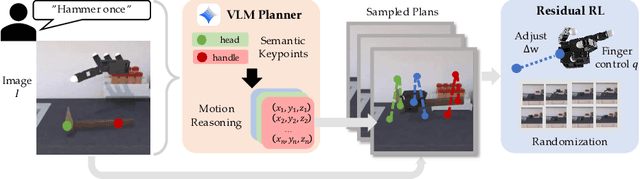
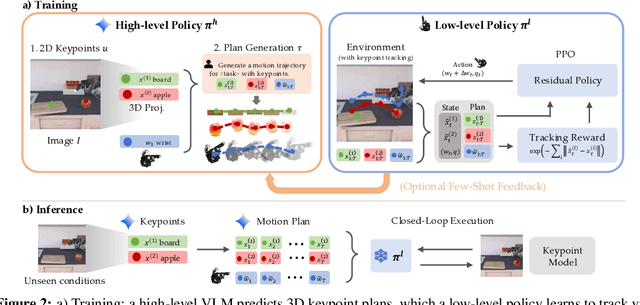
Dexterous robotic hands are essential for performing complex manipulation tasks, yet remain difficult to train due to the challenges of demonstration collection and high-dimensional control. While reinforcement learning (RL) can alleviate the data bottleneck by generating experience in simulation, it typically relies on carefully designed, task-specific reward functions, which hinder scalability and generalization. Thus, contemporary works in dexterous manipulation have often bootstrapped from reference trajectories. These trajectories specify target hand poses that guide the exploration of RL policies and object poses that enable dense, task-agnostic rewards. However, sourcing suitable trajectories - particularly for dexterous hands - remains a significant challenge. Yet, the precise details in explicit reference trajectories are often unnecessary, as RL ultimately refines the motion. Our key insight is that modern vision-language models (VLMs) already encode the commonsense spatial and semantic knowledge needed to specify tasks and guide exploration effectively. Given a task description (e.g., "open the cabinet") and a visual scene, our method uses an off-the-shelf VLM to first identify task-relevant keypoints (e.g., handles, buttons) and then synthesize 3D trajectories for hand motion and object motion. Subsequently, we train a low-level residual RL policy in simulation to track these coarse trajectories or "scaffolds" with high fidelity. Across a number of simulated tasks involving articulated objects and semantic understanding, we demonstrate that our method is able to learn robust dexterous manipulation policies. Moreover, we showcase that our method transfers to real-world robotic hands without any human demonstrations or handcrafted rewards.
Chunking the Critic: A Transformer-based Soft Actor-Critic with N-Step Returns
Mar 05, 2025Soft Actor-Critic (SAC) critically depends on its critic network, which typically evaluates a single state-action pair to guide policy updates. Using N-step returns is a common practice to reduce the bias in the target values of the critic. However, using N-step returns can again introduce high variance and necessitates importance sampling, often destabilizing training. Recent algorithms have also explored action chunking-such as direct action repetition and movement primitives-to enhance exploration. In this paper, we propose a Transformer-based Critic Network for SAC that integrates the N-returns framework in a stable and efficient manner. Unlike approaches that perform chunking in the actor network, we feed chunked actions into the critic network to explore potential performance gains. Our architecture leverages the Transformer's ability to process sequential information, facilitating more robust value estimation. Empirical results show that this method not only achieves efficient, stable training but also excels in sparse reward/multi-phase environments-traditionally a challenge for step-based methods. These findings underscore the promise of combining Transformer-based critics with N-returns to advance reinforcement learning performance
DIME:Diffusion-Based Maximum Entropy Reinforcement Learning
Feb 04, 2025Maximum entropy reinforcement learning (MaxEnt-RL) has become the standard approach to RL due to its beneficial exploration properties. Traditionally, policies are parameterized using Gaussian distributions, which significantly limits their representational capacity. Diffusion-based policies offer a more expressive alternative, yet integrating them into MaxEnt-RL poses challenges--primarily due to the intractability of computing their marginal entropy. To overcome this, we propose Diffusion-Based Maximum Entropy RL (DIME). DIME leverages recent advances in approximate inference with diffusion models to derive a lower bound on the maximum entropy objective. Additionally, we propose a policy iteration scheme that provably converges to the optimal diffusion policy. Our method enables the use of expressive diffusion-based policies while retaining the principled exploration benefits of MaxEnt-RL, significantly outperforming other diffusion-based methods on challenging high-dimensional control benchmarks. It is also competitive with state-of-the-art non-diffusion based RL methods while requiring fewer algorithmic design choices and smaller update-to-data ratios, reducing computational complexity.
MuTT: A Multimodal Trajectory Transformer for Robot Skills
Jul 22, 2024



High-level robot skills represent an increasingly popular paradigm in robot programming. However, configuring the skills' parameters for a specific task remains a manual and time-consuming endeavor. Existing approaches for learning or optimizing these parameters often require numerous real-world executions or do not work in dynamic environments. To address these challenges, we propose MuTT, a novel encoder-decoder transformer architecture designed to predict environment-aware executions of robot skills by integrating vision, trajectory, and robot skill parameters. Notably, we pioneer the fusion of vision and trajectory, introducing a novel trajectory projection. Furthermore, we illustrate MuTT's efficacy as a predictor when combined with a model-based robot skill optimizer. This approach facilitates the optimization of robot skill parameters for the current environment, without the need for real-world executions during optimization. Designed for compatibility with any representation of robot skills, MuTT demonstrates its versatility across three comprehensive experiments, showcasing superior performance across two different skill representations.
Variational Distillation of Diffusion Policies into Mixture of Experts
Jun 18, 2024



This work introduces Variational Diffusion Distillation (VDD), a novel method that distills denoising diffusion policies into Mixtures of Experts (MoE) through variational inference. Diffusion Models are the current state-of-the-art in generative modeling due to their exceptional ability to accurately learn and represent complex, multi-modal distributions. This ability allows Diffusion Models to replicate the inherent diversity in human behavior, making them the preferred models in behavior learning such as Learning from Human Demonstrations (LfD). However, diffusion models come with some drawbacks, including the intractability of likelihoods and long inference times due to their iterative sampling process. The inference times, in particular, pose a significant challenge to real-time applications such as robot control. In contrast, MoEs effectively address the aforementioned issues while retaining the ability to represent complex distributions but are notoriously difficult to train. VDD is the first method that distills pre-trained diffusion models into MoE models, and hence, combines the expressiveness of Diffusion Models with the benefits of Mixture Models. Specifically, VDD leverages a decompositional upper bound of the variational objective that allows the training of each expert separately, resulting in a robust optimization scheme for MoEs. VDD demonstrates across nine complex behavior learning tasks, that it is able to: i) accurately distill complex distributions learned by the diffusion model, ii) outperform existing state-of-the-art distillation methods, and iii) surpass conventional methods for training MoE.
MaIL: Improving Imitation Learning with Mamba
Jun 12, 2024



This work introduces Mamba Imitation Learning (MaIL), a novel imitation learning (IL) architecture that offers a computationally efficient alternative to state-of-the-art (SoTA) Transformer policies. Transformer-based policies have achieved remarkable results due to their ability in handling human-recorded data with inherently non-Markovian behavior. However, their high performance comes with the drawback of large models that complicate effective training. While state space models (SSMs) have been known for their efficiency, they were not able to match the performance of Transformers. Mamba significantly improves the performance of SSMs and rivals against Transformers, positioning it as an appealing alternative for IL policies. MaIL leverages Mamba as a backbone and introduces a formalism that allows using Mamba in the encoder-decoder structure. This formalism makes it a versatile architecture that can be used as a standalone policy or as part of a more advanced architecture, such as a diffuser in the diffusion process. Extensive evaluations on the LIBERO IL benchmark and three real robot experiments show that MaIL: i) outperforms Transformers in all LIBERO tasks, ii) achieves good performance even with small datasets, iii) is able to effectively process multi-modal sensory inputs, iv) is more robust to input noise compared to Transformers.
Acquiring Diverse Skills using Curriculum Reinforcement Learning with Mixture of Experts
Mar 11, 2024



Reinforcement learning (RL) is a powerful approach for acquiring a good-performing policy. However, learning diverse skills is challenging in RL due to the commonly used Gaussian policy parameterization. We propose \textbf{Di}verse \textbf{Skil}l \textbf{L}earning (Di-SkilL), an RL method for learning diverse skills using Mixture of Experts, where each expert formalizes a skill as a contextual motion primitive. Di-SkilL optimizes each expert and its associate context distribution to a maximum entropy objective that incentivizes learning diverse skills in similar contexts. The per-expert context distribution enables automatic curricula learning, allowing each expert to focus on its best-performing sub-region of the context space. To overcome hard discontinuities and multi-modalities without any prior knowledge of the environment's unknown context probability space, we leverage energy-based models to represent the per-expert context distributions and demonstrate how we can efficiently train them using the standard policy gradient objective. We show on challenging robot simulation tasks that Di-SkilL can learn diverse and performant skills.
MP3: Movement Primitive-Based (Re-)Planning Policy
Jul 02, 2023
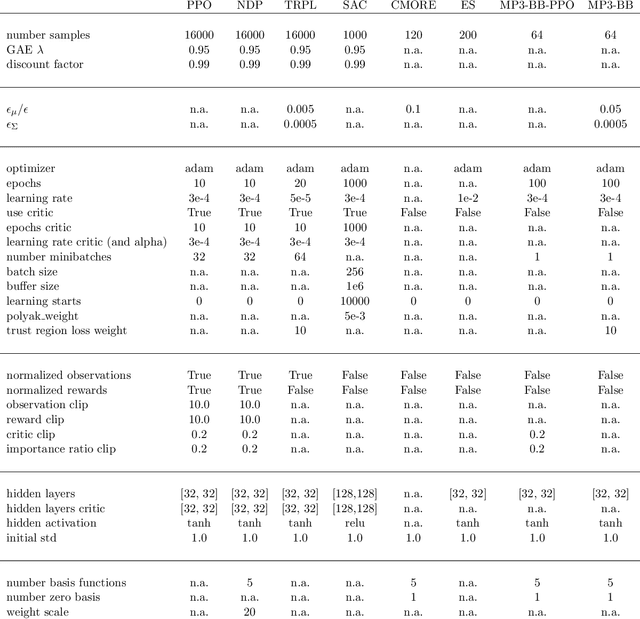

We introduce a novel deep reinforcement learning (RL) approach called Movement Primitive-based Planning Policy (MP3). By integrating movement primitives (MPs) into the deep RL framework, MP3 enables the generation of smooth trajectories throughout the whole learning process while effectively learning from sparse and non-Markovian rewards. Additionally, MP3 maintains the capability to adapt to changes in the environment during execution. Although many early successes in robot RL have been achieved by combining RL with MPs, these approaches are often limited to learning single stroke-based motions, lacking the ability to adapt to task variations or adjust motions during execution. Building upon our previous work, which introduced an episode-based RL method for the non-linear adaptation of MP parameters to different task variations, this paper extends the approach to incorporating replanning strategies. This allows adaptation of the MP parameters throughout motion execution, addressing the lack of online motion adaptation in stochastic domains requiring feedback. We compared our approach against state-of-the-art deep RL and RL with MPs methods. The results demonstrated improved performance in sophisticated, sparse reward settings and in domains requiring replanning.
Curriculum-Based Imitation of Versatile Skills
Apr 11, 2023



Learning skills by imitation is a promising concept for the intuitive teaching of robots. A common way to learn such skills is to learn a parametric model by maximizing the likelihood given the demonstrations. Yet, human demonstrations are often multi-modal, i.e., the same task is solved in multiple ways which is a major challenge for most imitation learning methods that are based on such a maximum likelihood (ML) objective. The ML objective forces the model to cover all data, it prevents specialization in the context space and can cause mode-averaging in the behavior space, leading to suboptimal or potentially catastrophic behavior. Here, we alleviate those issues by introducing a curriculum using a weight for each data point, allowing the model to specialize on data it can represent while incentivizing it to cover as much data as possible by an entropy bonus. We extend our algorithm to a Mixture of (linear) Experts (MoE) such that the single components can specialize on local context regions, while the MoE covers all data points. We evaluate our approach in complex simulated and real robot control tasks and show it learns from versatile human demonstrations and significantly outperforms current SOTA methods. A reference implementation can be found at https://github.com/intuitive-robots/ml-cur
Information Maximizing Curriculum: A Curriculum-Based Approach for Training Mixtures of Experts
Mar 27, 2023
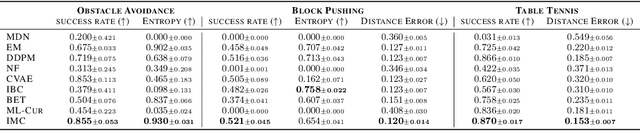
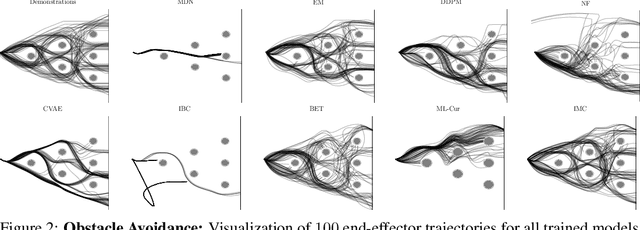

Mixtures of Experts (MoE) are known for their ability to learn complex conditional distributions with multiple modes. However, despite their potential, these models are challenging to train and often tend to produce poor performance, explaining their limited popularity. Our hypothesis is that this under-performance is a result of the commonly utilized maximum likelihood (ML) optimization, which leads to mode averaging and a higher likelihood of getting stuck in local maxima. We propose a novel curriculum-based approach to learning mixture models in which each component of the MoE is able to select its own subset of the training data for learning. This approach allows for independent optimization of each component, resulting in a more modular architecture that enables the addition and deletion of components on the fly, leading to an optimization less susceptible to local optima. The curricula can ignore data-points from modes not represented by the MoE, reducing the mode-averaging problem. To achieve a good data coverage, we couple the optimization of the curricula with a joint entropy objective and optimize a lower bound of this objective. We evaluate our curriculum-based approach on a variety of multimodal behavior learning tasks and demonstrate its superiority over competing methods for learning MoE models and conditional generative models.