 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-driven Exploration Strategies for Online Grasp Learning
Sep 21, 2023Existing grasp prediction approaches are mostly based on offline learning, while, ignored the exploratory grasp learning during online adaptation to new picking scenarios, i.e., unseen object portfolio, camera and bin settings etc. In this paper, we present a novel method for online learning of grasp predictions for robotic bin picking in a principled way. Existing grasp prediction approaches are mostly based on offline learning, while, ignored the exploratory grasp learning during online adaptation to new picking scenarios, i.e., unseen object portfolio, camera and bin settings etc. In this paper, we present a novel method for online learning of grasp predictions for robotic bin picking in a principled way. Specifically, the online learning algorithm with an effective exploration strategy can significantly improve its adaptation performance to unseen environment settings. To this end, we first propose to formulate online grasp learning as a RL problem that will allow to adapt both grasp reward prediction and grasp poses. We propose various uncertainty estimation schemes based on Bayesian Uncertainty Quantification and Distributional Ensembles. We carry out evaluations on real-world bin picking scenes of varying difficulty. The objects in the bin have various challenging physical and perceptual characteristics that can be characterized by semi- or total transparency, and irregular or curved surfaces. The results of our experiments demonstrate a notable improvement in the suggested approach compared to conventional online learning methods which incorporate only naive exploration strategies.
SA6D: Self-Adaptive Few-Shot 6D Pose Estimator for Novel and Occluded Objects
Aug 31, 2023To enable meaningful robotic manipulation of objects in the real-world, 6D pose estimation is one of the critical aspects. Most existing approaches have difficulties to extend predictions to scenarios where novel object instances are continuously introduced, especially with heavy occlusions. In this work, we propose a few-shot pose estimation (FSPE) approach called SA6D, which uses a self-adaptive segmentation module to identify the novel target object and construct a point cloud model of the target object using only a small number of cluttered reference images. Unlike existing methods, SA6D does not require object-centric reference images or any additional object information, making it a more generalizable and scalable solution across categories. We evaluate SA6D on real-world tabletop object datasets and demonstrate that SA6D outperforms existing FSPE methods, particularly in cluttered scenes with occlusions, while requiring fewer reference images.
Model-free Grasping with Multi-Suction Cup Grippers for Robotic Bin Picking
Jul 31, 2023This paper presents a novel method for model-free prediction of grasp poses for suction grippers with multiple suction cups. Our approach is agnostic to the design of the gripper and does not require gripper-specific training data. In particular, we propose a two-step approach, where first, a neural network predicts pixel-wise grasp quality for an input image to indicate areas that are generally graspable. Second, an optimization step determines the optimal gripper selection and corresponding grasp poses based on configured gripper layouts and activation schemes. In addition, we introduce a method for automated labeling for supervised training of the grasp quality network. Experimental evaluations on a real-world industrial application with bin picking scenes of varying difficulty demonstrate the effectiveness of our method.
SyMFM6D: Symmetry-aware Multi-directional Fusion for Multi-View 6D Object Pose Estimation
Jul 01, 2023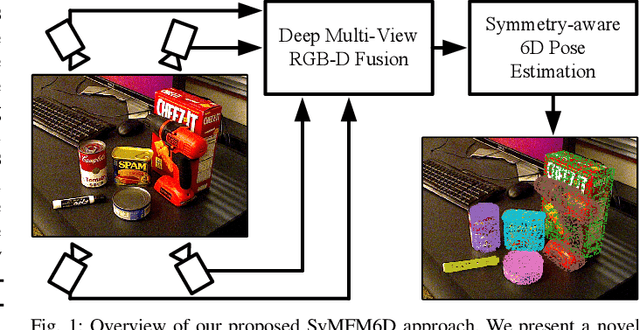
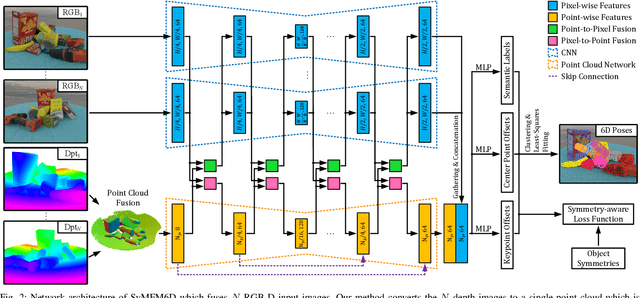
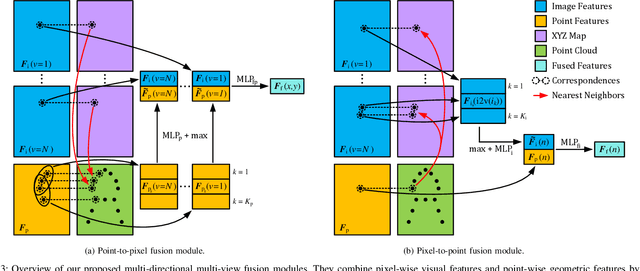
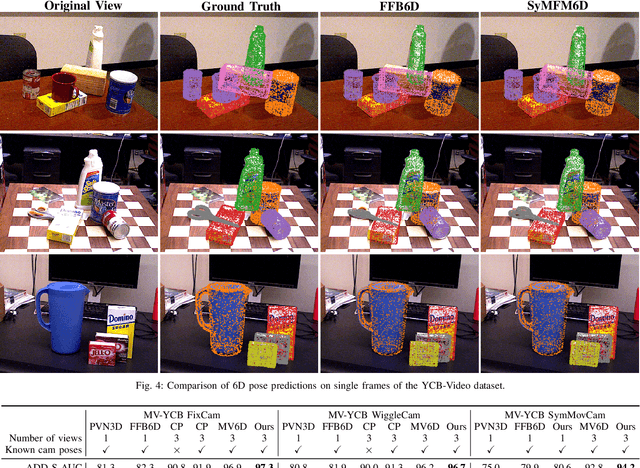
Detecting objects and estimating their 6D poses is essential for automated systems to interact safely with the environment. Most 6D pose estimators, however, rely on a single camera frame and suffer from occlusions and ambiguities due to object symmetries. We overcome this issue by presenting a novel symmetry-aware multi-view 6D pose estimator called SyMFM6D. Our approach efficiently fuses the RGB-D frames from multiple perspectives in a deep multi-directional fusion network and predicts predefined keypoints for all objects in the scene simultaneously. Based on the keypoints and an instance semantic segmentation, we efficiently compute the 6D poses by least-squares fitting. To address the ambiguity issues for symmetric objects, we propose a novel training procedure for symmetry-aware keypoint detection including a new objective function. Our SyMFM6D network significantly outperforms the state-of-the-art in both single-view and multi-view 6D pose estimation. We furthermore show the effectiveness of our symmetry-aware training procedure and demonstrate that our approach is robust towards inaccurate camera calibration and dynamic camera setups.
Wasserstein Gradient Flows for Optimizing Gaussian Mixture Policies
May 17, 2023Robots often rely on a repertoire of previously-learned motion policies for performing tasks of diverse complexities. When facing unseen task conditions or when new task requirements arise, robots must adapt their motion policies accordingly. In this context, policy optimization is the \emph{de facto} paradigm to adapt robot policies as a function of task-specific objectives. Most commonly-used motion policies carry particular structures that are often overlooked in policy optimization algorithms. We instead propose to leverage the structure of probabilistic policies by casting the policy optimization as an optimal transport problem. Specifically, we focus on robot motion policies that build on Gaussian mixture models (GMMs) and formulate the policy optimization as a Wassertein gradient flow over the GMMs space. This naturally allows us to constrain the policy updates via the $L^2$-Wasserstein distance between GMMs to enhance the stability of the policy optimization process. Furthermore, we leverage the geometry of the Bures-Wasserstein manifold to optimize the Gaussian distributions of the GMM policy via Riemannian optimization. We evaluate our approach on common robotic settings: Reaching motions, collision-avoidance behaviors, and multi-goal tasks. Our results show that our method outperforms common policy optimization baselines in terms of task success rate and low-variance solutions.
The e-Bike Motor Assembly: Towards Advanced Robotic Manipulation for Flexible Manufacturing
Apr 20, 2023



Robotic manipulation is currently undergoing a profound paradigm shift due to the increasing needs for flexible manufacturing systems, and at the same time, because of the advances in enabling technologies such as sensing, learning, optimization, and hardware. This demands for robots that can observe and reason about their workspace, and that are skillfull enough to complete various assembly processes in weakly-structured settings. Moreover, it remains a great challenge to enable operators for teaching robots on-site, while managing the inherent complexity of perception, control, motion planning and reaction to unexpected situations. Motivated by real-world industrial applications, this paper demonstrates the potential of such a paradigm shift in robotics on the industrial case of an e-Bike motor assembly. The paper presents a concept for teaching and programming adaptive robots on-site and demonstrates their potential for the named applications. The framework includes: (i) a method to teach perception systems onsite in a self-supervised manner, (ii) a general representation of object-centric motion skills and force-sensitive assembly skills, both learned from demonstration, (iii) a sequencing approach that exploits a human-designed plan to perform complex tasks, and (iv) a system solution for adapting and optimizing skills online. The aforementioned components are interfaced through a four-layer software architecture that makes our framework a tangible industrial technology. To demonstrate the generality of the proposed framework, we provide, in addition to the motivating e-Bike motor assembly, a further case study on dense box packing for logistics automation.
Deep Black-Box Reinforcement Learning with Movement Primitives
Oct 18, 2022
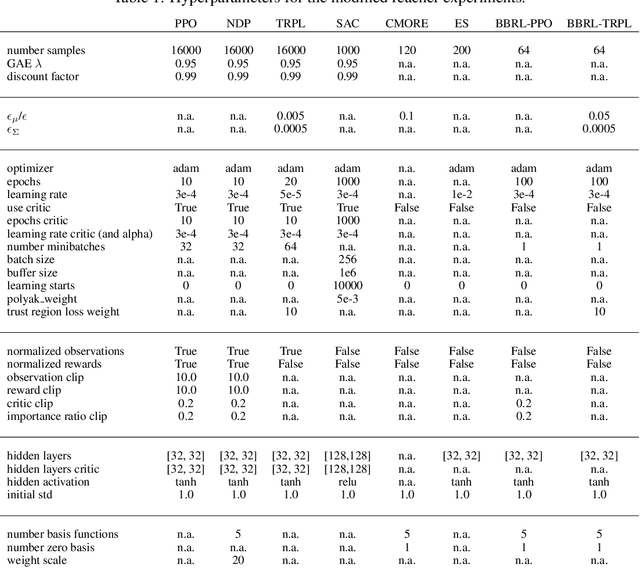
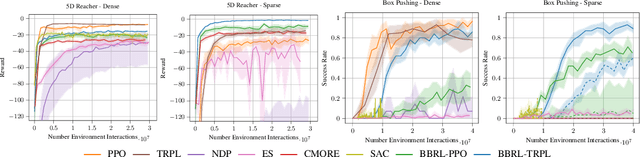
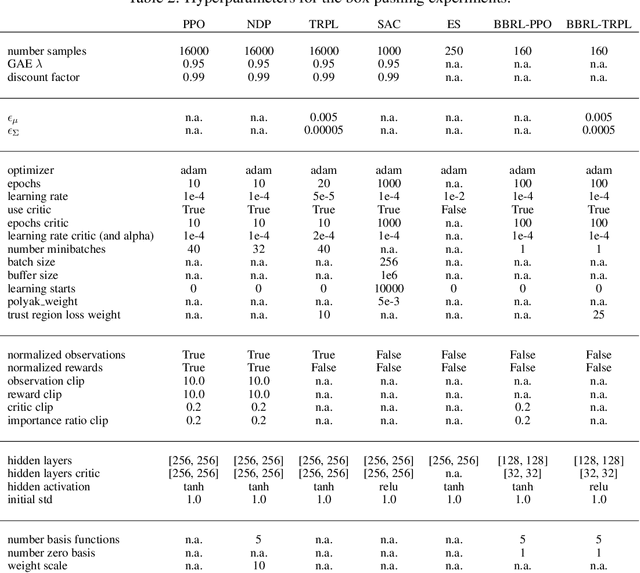
\Episode-based reinforcement learning (ERL) algorithms treat reinforcement learning (RL) as a black-box optimization problem where we learn to select a parameter vector of a controller, often represented as a movement primitive, for a given task descriptor called a context. ERL offers several distinct benefits in comparison to step-based RL. It generates smooth control trajectories, can handle non-Markovian reward definitions, and the resulting exploration in parameter space is well suited for solving sparse reward settings. Yet, the high dimensionality of the movement primitive parameters has so far hampered the effective use of deep RL methods. In this paper, we present a new algorithm for deep ERL. It is based on differentiable trust region layers, a successful on-policy deep RL algorithm. These layers allow us to specify trust regions for the policy update that are solved exactly for each state using convex optimization, which enables policies learning with the high precision required for the ERL. We compare our ERL algorithm to state-of-the-art step-based algorithms in many complex simulated robotic control tasks. In doing so, we investigate different reward formulations - dense, sparse, and non-Markovian. While step-based algorithms perform well only on dense rewards, ERL performs favorably on sparse and non-Markovian rewards. Moreover, our results show that the sparse and the non-Markovian rewards are also often better suited to define the desired behavior, allowing us to obtain considerably higher quality policies compared to step-based RL.
FusionVAE: A Deep Hierarchical Variational Autoencoder for RGB Image Fusion
Sep 22, 2022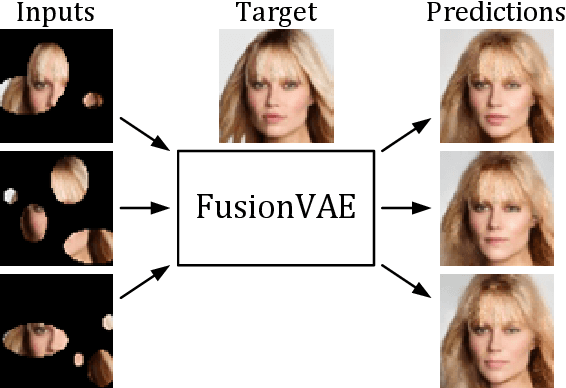
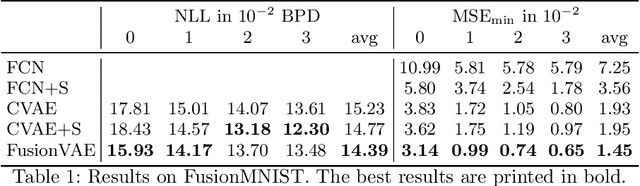
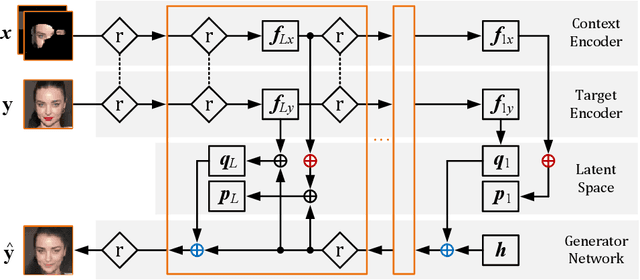
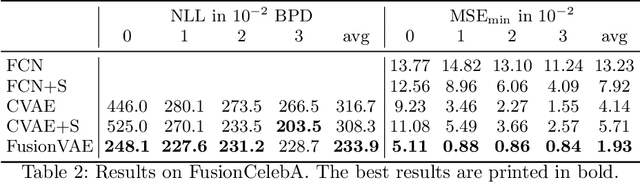
Sensor fusion can significantly improve the performance of many computer vision tasks. However, traditional fusion approaches are either not data-driven and cannot exploit prior knowledge nor find regularities in a given dataset or they are restricted to a single application. We overcome this shortcoming by presenting a novel deep hierarchical variational autoencoder called FusionVAE that can serve as a basis for many fusion tasks. Our approach is able to generate diverse image samples that are conditioned on multiple noisy, occluded, or only partially visible input images. We derive and optimize a variational lower bound for the conditional log-likelihood of FusionVAE. In order to assess the fusion capabilities of our model thoroughly, we created three novel datasets for image fusion based on popular computer vision datasets. In our experiments, we show that FusionVAE learns a representation of aggregated information that is relevant to fusion tasks. The results demonstrate that our approach outperforms traditional methods significantly. Furthermore, we present the advantages and disadvantages of different design choices.
Category-Agnostic 6D Pose Estimation with Conditional Neural Processes
Jun 14, 2022

We present a novel meta-learning approach for 6D pose estimation on unknown objects. In contrast to "instance-level" pose estimation methods, our algorithm learns object representation in a category-agnostic way, which endows it with strong generalization capabilities within and across object categories. Specifically, we employ a conditional neural process-based meta-learning approach to train an encoder to capture texture and geometry of an object in a latent representation, based on very few RGB-D images and ground-truth keypoints. The latent representation is then used by a simultaneously meta-trained decoder to predict the 6D pose of the object in new images. To evaluate our algorithm, experiments are conducted on our new fully-annotated synthetic datasets generated from Multiple Categories in Multiple Scenes (MCMS). Experimental results demonstrate that our model performs well on unseen objects with various shapes and appearances.
Meta-Learning Regrasping Strategies for Physical-Agnostic Objects
May 23, 2022
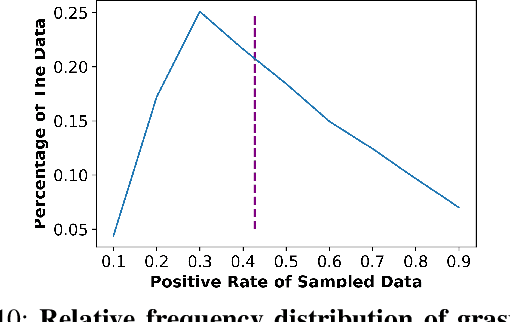
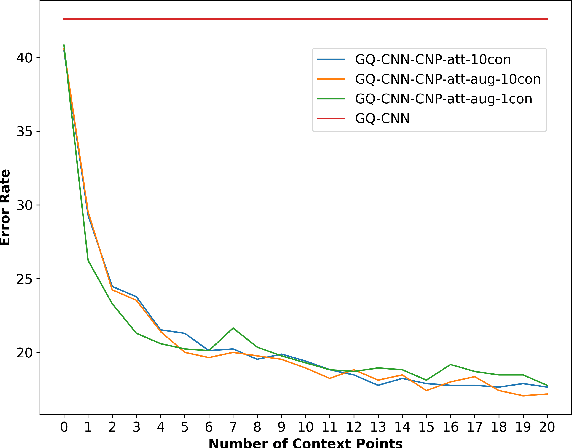
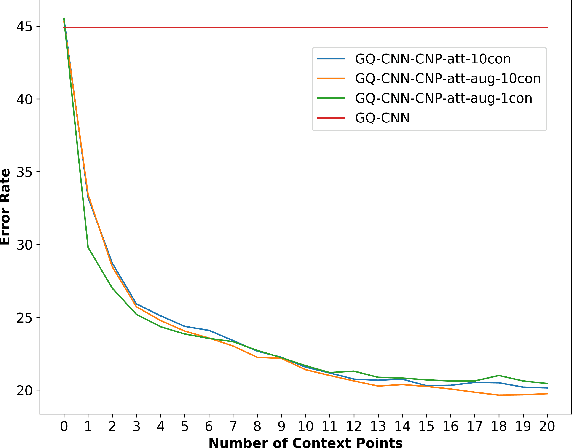
Grasping inhomogeneous objects, practical use in real-world applications, remains a challenging task due to the unknown physical properties such as mass distribution and coefficient of friction. In this study, we propose a vision-based meta-learning algorithm to learn physical properties in an agnostic way. In particular, we employ Conditional Neural Processes (CNPs) on top of DexNet-2.0. CNPs learn physical embeddings rapidly from a few observations where each observation is composed of i) the cropped depth image, ii) the grasping height between the gripper and estimated grasping point, and iii) the binary grasping result. Our modified conditional DexNet-2.0 (DexNet-CNP) updates the predicted grasping quality iteratively from new observations, which can be executed in an online fashion. We evaluate our method in the Pybullet simulator using various shape primitive objects with different physical parameters. The results show that our model outperforms the original DexNet-2.0 and is able to generalize on unseen objects with different shapes.