 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Storytelling Images with Rich Chains-of-Reasoning
Dec 08, 2025An image can convey a compelling story by presenting rich, logically connected visual clues. These connections form Chains-of-Reasoning (CoRs) within the image, enabling viewers to infer events, causal relationships, and other information, thereby understanding the underlying story. In this paper, we focus on these semantically rich images and define them as Storytelling Images. Such images have diverse applications beyond illustration creation and cognitive screening, leveraging their ability to convey multi-layered information visually and inspire active interpretation. However, due to their complex semantic nature, Storytelling Images are inherently challenging to create, and thus remain relatively scarce. To address this challenge, we introduce the Storytelling Image Generation task, which explores how generative AI models can be leveraged to create such images. Specifically, we propose a two-stage pipeline, StorytellingPainter, which combines the creative reasoning abilities of Large Language Models (LLMs) with the visual synthesis capabilities of Text-to-Image (T2I) models to generate Storytelling Images. Alongside this pipeline, we develop a dedicated evaluation framework comprising three main evaluators: a Semantic Complexity Evaluator, a KNN-based Diversity Evaluator and a Story-Image Alignment Evaluator. Given the critical role of story generation in the Storytelling Image Generation task and the performance disparity between open-source and proprietary LLMs, we further explore tailored training strategies to reduce this gap, resulting in a series of lightweight yet effective models named Mini-Storytellers. Experimental results demonstrate the feasibility and effectiveness of our approaches. The code is available at https://github.com/xiujiesong/StorytellingImageGeneration.
Stable Diffusion is a Natural Cross-Modal Decoder for Layered AI-generated Image Compression
Dec 17, 2024



Recent advances in Artificial Intelligence Generated Content (AIGC) have garnered significant interest, accompanied by an increasing need to transmit and compress the vast number of AI-generated images (AIGIs). However, there is a noticeable deficiency in research focused on compression methods for AIGIs. To address this critical gap, we introduce a scalable cross-modal compression framework that incorporates multiple human-comprehensible modalities, designed to efficiently capture and relay essential visual information for AIGIs. In particular, our framework encodes images into a layered bitstream consisting of a semantic layer that delivers high-level semantic information through text prompts; a structural layer that captures spatial details using edge or skeleton maps; and a texture layer that preserves local textures via a colormap. Utilizing Stable Diffusion as the backend, the framework effectively leverages these multimodal priors for image generation, effectively functioning as a decoder when these priors are encoded. Qualitative and quantitative results show that our method proficiently restores both semantic and visual details, competing against baseline approaches at extremely low bitrates ( <0.02 bpp). Additionally, our framework facilitates downstream editing applications without requiring full decoding, thereby paving a new direction for future research in AIGI compression.
Scalable Face Image Coding via StyleGAN Prior: Towards Compression for Human-Machine Collaborative Vision
Dec 25, 2023



The accelerated proliferation of visual content and the rapid development of machine vision technologies bring significant challenges in delivering visual data on a gigantic scale, which shall be effectively represented to satisfy both human and machine requirements. In this work, we investigate how hierarchical representations derived from the advanced generative prior facilitate constructing an efficient scalable coding paradigm for human-machine collaborative vision. Our key insight is that by exploiting the StyleGAN prior, we can learn three-layered representations encoding hierarchical semantics, which are elaborately designed into the basic, middle, and enhanced layers, supporting machine intelligence and human visual perception in a progressive fashion. With the aim of achieving efficient compression, we propose the layer-wise scalable entropy transformer to reduce the redundancy between layers. Based on the multi-task scalable rate-distortion objective, the proposed scheme is jointly optimized to achieve optimal machine analysis performance, human perception experience, and compression ratio. We validate the proposed paradigm's feasibility in face image compression. Extensive qualitative and quantitative experimental results demonstrate the superiority of the proposed paradigm over the latest compression standard Versatile Video Coding (VVC) in terms of both machine analysis as well as human perception at extremely low bitrates ($<0.01$ bpp), offering new insights for human-machine collaborative compression.
Meta-Learning Regrasping Strategies for Physical-Agnostic Objects
May 23, 2022
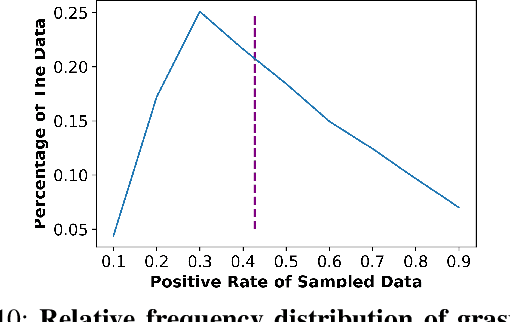
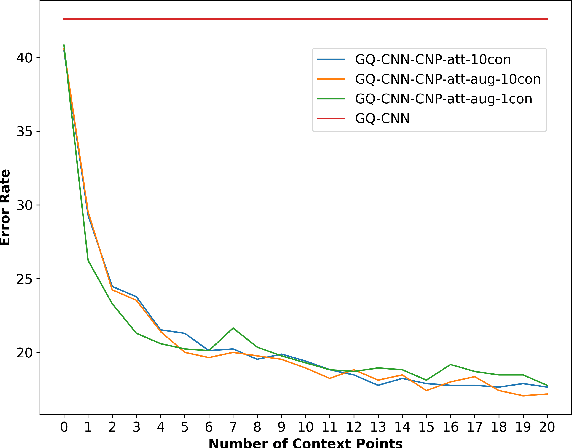
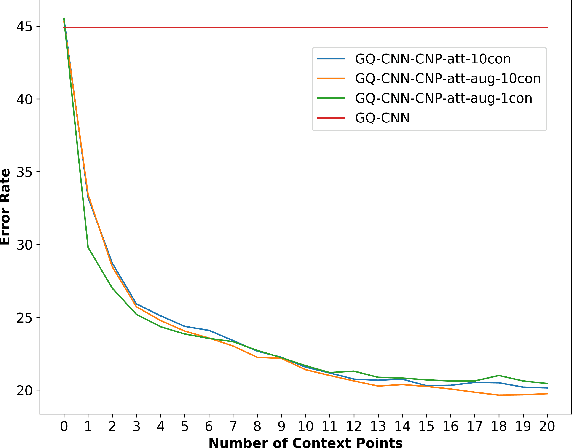
Grasping inhomogeneous objects, practical use in real-world applications, remains a challenging task due to the unknown physical properties such as mass distribution and coefficient of friction. In this study, we propose a vision-based meta-learning algorithm to learn physical properties in an agnostic way. In particular, we employ Conditional Neural Processes (CNPs) on top of DexNet-2.0. CNPs learn physical embeddings rapidly from a few observations where each observation is composed of i) the cropped depth image, ii) the grasping height between the gripper and estimated grasping point, and iii) the binary grasping result. Our modified conditional DexNet-2.0 (DexNet-CNP) updates the predicted grasping quality iteratively from new observations, which can be executed in an online fashion. We evaluate our method in the Pybullet simulator using various shape primitive objects with different physical parameters. The results show that our model outperforms the original DexNet-2.0 and is able to generalize on unseen objects with different shapes.
Asking Crowdworkers to Write Entailment Examples: The Best of Bad Options
Oct 13, 2020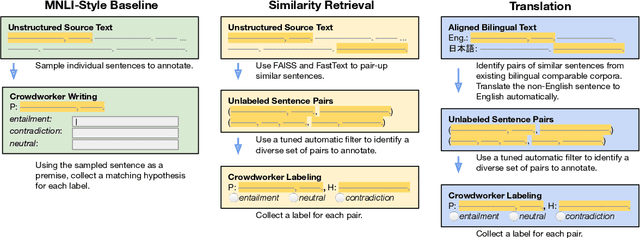

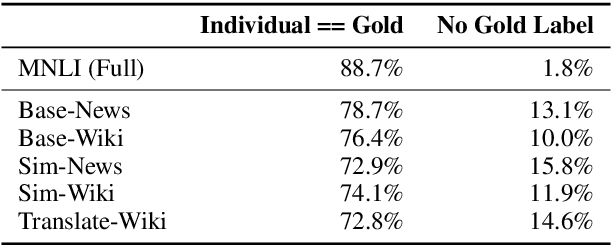

Large-scale natural language inference (NLI) datasets such as SNLI or MNLI have been created by asking crowdworkers to read a premise and write three new hypotheses, one for each possible semantic relationships (entailment, contradiction, and neutral). While this protocol has been used to create useful benchmark data, it remains unclear whether the writing-based annotation protocol is optimal for any purpose, since it has not been evaluated directly. Furthermore, there is ample evidence that crowdworker writing can introduce artifacts in the data. We investigate two alternative protocols which automatically create candidate (premise, hypothesis) pairs for annotators to label. Using these protocols and a writing-based baseline, we collect several new English NLI datasets of over 3k examples each, each using a fixed amount of annotator time, but a varying number of examples to fit that time budget. Our experiments on NLI and transfer learning show negative results: None of the alternative protocols outperforms the baseline in evaluations of generalization within NLI or on transfer to outside target tasks. We conclude that crowdworker writing still the best known option for entailment data, highlighting the need for further data collection work to focus on improving writing-based annotation processes.