 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCutVerse: A Compositional GUI Agents Benchmark for Media Post-Production Editing
May 19, 2026While GUI agents have made significant progress in web navigation and basic operating system tasks, their capabilities in professional creative workflows remain largely underexplored. To bridge this gap, we introduce Cutverse, a benchmark designed to systematically evaluate autonomous GUI agents in realistic media post-production environments. We curate expert demonstrations across 7 professional applications (e.g., Premiere Pro, Photoshop), covering 186 complex, long-horizon tasks grounded in authentic editing workflows, involving dense multimodal interfaces and tightly coupled interaction sequences. To support scalable evaluation, we develop a lightweight parser that transforms raw screen recordings and low-level interaction logs into structured, compositional GUI action trajectories with precise grounding. Extensive evaluations reveal that existing agents achieve only 36.0\% task success on realistic media editing tasks, underscoring the challenges posed by complex, long-horizon media post-production workflows in our benchmark.While current models demonstrate promising spatial grounding, multimodal alignment, and coordinated action execution, they remain limited in long-horizon reliability and domain-specific planning.
Camera Artist: A Multi-Agent Framework for Cinematic Language Storytelling Video Generation
Apr 10, 2026We propose Camera Artist, a multi-agent framework that models a real-world filmmaking workflow to generate narrative videos with explicit cinematic language. While recent multi-agent systems have made substantial progress in automating filmmaking workflows from scripts to videos, they often lack explicit mechanisms to structure narrative progression across adjacent shots and deliberate use of cinematic language, resulting in fragmented storytelling and limited filmic quality. To address this, Camera Artist builds upon established agentic pipelines and introduces a dedicated Cinematography Shot Agent, which integrates recursive storyboard generation to strengthen shot-to-shot narrative continuity and cinematic language injection to produce more expressive, film-oriented shot designs. Extensive quantitative and qualitative results demonstrate that our approach consistently outperforms existing baselines in narrative consistency, dynamic expressiveness, and perceived film quality.
IC-Effect: Precise and Efficient Video Effects Editing via In-Context Learning
Dec 17, 2025

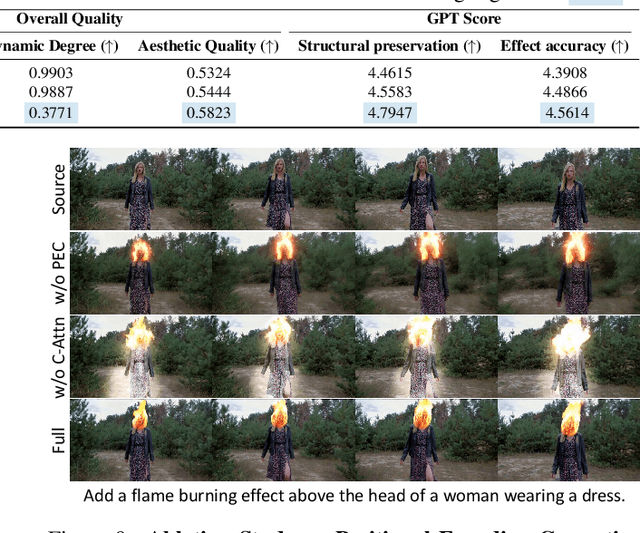

We propose \textbf{IC-Effect}, an instruction-guided, DiT-based framework for few-shot video VFX editing that synthesizes complex effects (\eg flames, particles and cartoon characters) while strictly preserving spatial and temporal consistency. Video VFX editing is highly challenging because injected effects must blend seamlessly with the background, the background must remain entirely unchanged, and effect patterns must be learned efficiently from limited paired data. However, existing video editing models fail to satisfy these requirements. IC-Effect leverages the source video as clean contextual conditions, exploiting the contextual learning capability of DiT models to achieve precise background preservation and natural effect injection. A two-stage training strategy, consisting of general editing adaptation followed by effect-specific learning via Effect-LoRA, ensures strong instruction following and robust effect modeling. To further improve efficiency, we introduce spatiotemporal sparse tokenization, enabling high fidelity with substantially reduced computation. We also release a paired VFX editing dataset spanning $15$ high-quality visual styles. Extensive experiments show that IC-Effect delivers high-quality, controllable, and temporally consistent VFX editing, opening new possibilities for video creation.
UniMIC: Token-Based Multimodal Interactive Coding for Human-AI Collaboration
Sep 26, 2025



The rapid progress of Large Multimodal Models (LMMs) and cloud-based AI agents is transforming human-AI collaboration into bidirectional, multimodal interaction. However, existing codecs remain optimized for unimodal, one-way communication, resulting in repeated degradation under conventional compress-transmit-reconstruct pipelines. To address this limitation, we propose UniMIC, a Unified token-based Multimodal Interactive Coding framework that bridges edge devices and cloud AI agents. Instead of transmitting raw pixels or plain text, UniMIC employs compact tokenized representations as the communication medium, enabling efficient low-bitrate transmission while maintaining compatibility with LMMs. To further enhance compression, lightweight Transformer-based entropy models with scenario-specific designs-generic, masked, and text-conditioned-effectively minimize inter-token redundancy. Extensive experiments on text-to-image generation, text-guided inpainting, outpainting, and visual question answering show that UniMIC achieves substantial bitrate savings and remains robust even at ultra-low bitrates (<0.05bpp), without compromising downstream task performance. These results establish UniMIC as a practical and forward-looking paradigm for next-generation multimodal interactive communication.
EmoAgent: Multi-Agent Collaboration of Plan, Edit, and Critic, for Affective Image Manipulation
Mar 14, 2025



Affective Image Manipulation (AIM) aims to alter an image's emotional impact by adjusting multiple visual elements to evoke specific feelings.Effective AIM is inherently complex, necessitating a collaborative approach that involves identifying semantic cues within source images, manipulating these elements to elicit desired emotional responses, and verifying that the combined adjustments successfully evoke the target emotion.To address these challenges, we introduce EmoAgent, the first multi-agent collaboration framework for AIM. By emulating the cognitive behaviors of a human painter, EmoAgent incorporates three specialized agents responsible for planning, editing, and critical evaluation. Furthermore, we develop an emotion-factor knowledge retriever, a decision-making tree space, and a tool library to enhance EmoAgent's effectiveness in handling AIM. Experiments demonstrate that the proposed multi-agent framework outperforms existing methods, offering more reasonable and effective emotional expression.
Scalable Face Image Coding via StyleGAN Prior: Towards Compression for Human-Machine Collaborative Vision
Dec 25, 2023



The accelerated proliferation of visual content and the rapid development of machine vision technologies bring significant challenges in delivering visual data on a gigantic scale, which shall be effectively represented to satisfy both human and machine requirements. In this work, we investigate how hierarchical representations derived from the advanced generative prior facilitate constructing an efficient scalable coding paradigm for human-machine collaborative vision. Our key insight is that by exploiting the StyleGAN prior, we can learn three-layered representations encoding hierarchical semantics, which are elaborately designed into the basic, middle, and enhanced layers, supporting machine intelligence and human visual perception in a progressive fashion. With the aim of achieving efficient compression, we propose the layer-wise scalable entropy transformer to reduce the redundancy between layers. Based on the multi-task scalable rate-distortion objective, the proposed scheme is jointly optimized to achieve optimal machine analysis performance, human perception experience, and compression ratio. We validate the proposed paradigm's feasibility in face image compression. Extensive qualitative and quantitative experimental results demonstrate the superiority of the proposed paradigm over the latest compression standard Versatile Video Coding (VVC) in terms of both machine analysis as well as human perception at extremely low bitrates ($<0.01$ bpp), offering new insights for human-machine collaborative compression.
Dynamic Storyboard Generation in an Engine-based Virtual Environment for Video Production
Jan 31, 2023


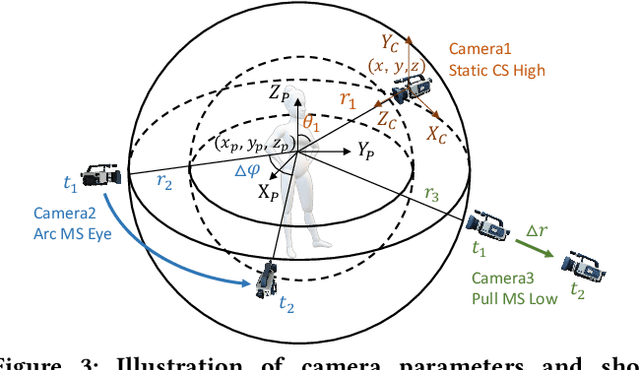
Amateurs working on mini-films and short-form videos usually spend lots of time and effort on the multi-round complicated process of setting and adjusting scenes, plots, and cameras to deliver satisfying video shots. We present Virtual Dynamic Storyboard (VDS) to allow users storyboarding shots in virtual environments, where the filming staff can easily test the settings of shots before the actual filming. VDS runs on a "propose-simulate-discriminate" mode: Given a formatted story script and a camera script as input, it generates several character animation and camera movement proposals following predefined story and cinematic rules to allow an off-the-shelf simulation engine to render videos. To pick up the top-quality dynamic storyboard from the candidates, we equip it with a shot ranking discriminator based on shot quality criteria learned from professional manual-created data. VDS is comprehensively validated via extensive experiments and user studies, demonstrating its efficiency, effectiveness, and great potential in assisting amateur video production.
Temporal and Contextual Transformer for Multi-Camera Editing of TV Shows
Oct 17, 2022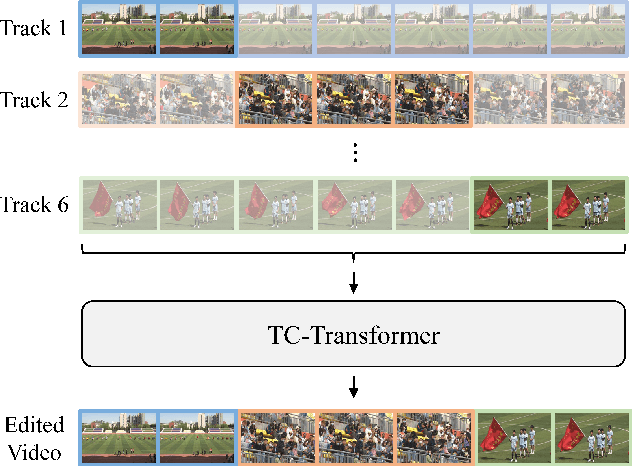
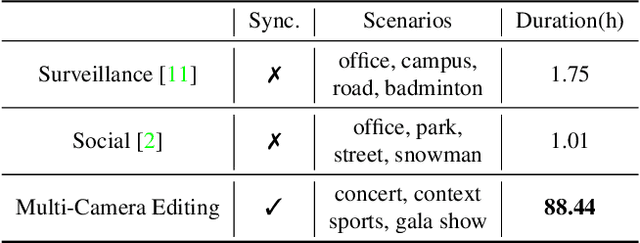

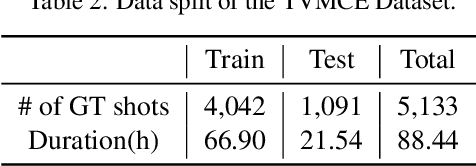
The ability to choose an appropriate camera view among multiple cameras plays a vital role in TV shows delivery. But it is hard to figure out the statistical pattern and apply intelligent processing due to the lack of high-quality training data. To solve this issue, we first collect a novel benchmark on this setting with four diverse scenarios including concerts, sports games, gala shows, and contests, where each scenario contains 6 synchronized tracks recorded by different cameras. It contains 88-hour raw videos that contribute to the 14-hour edited videos. Based on this benchmark, we further propose a new approach temporal and contextual transformer that utilizes clues from historical shots and other views to make shot transition decisions and predict which view to be used. Extensive experiments show that our method outperforms existing methods on the proposed multi-camera editing benchmark.