 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCinePreGen: Camera Controllable Video Previsualization via Engine-powered Diffusion
Aug 30, 2024With advancements in video generative AI models (e.g., SORA), creators are increasingly using these techniques to enhance video previsualization. However, they face challenges with incomplete and mismatched AI workflows. Existing methods mainly rely on text descriptions and struggle with camera placement, a key component of previsualization. To address these issues, we introduce CinePreGen, a visual previsualization system enhanced with engine-powered diffusion. It features a novel camera and storyboard interface that offers dynamic control, from global to local camera adjustments. This is combined with a user-friendly AI rendering workflow, which aims to achieve consistent results through multi-masked IP-Adapter and engine simulation guidelines. In our comprehensive evaluation study, we demonstrate that our system reduces development viscosity (i.e., the complexity and challenges in the development process), meets users' needs for extensive control and iteration in the design process, and outperforms other AI video production workflows in cinematic camera movement, as shown by our experiments and a within-subjects user study. With its intuitive camera controls and realistic rendering of camera motion, CinePreGen shows great potential for improving video production for both individual creators and industry professionals.
Cinematic Behavior Transfer via NeRF-based Differentiable Filming
Nov 29, 2023In the evolving landscape of digital media and video production, the precise manipulation and reproduction of visual elements like camera movements and character actions are highly desired. Existing SLAM methods face limitations in dynamic scenes and human pose estimation often focuses on 2D projections, neglecting 3D statuses. To address these issues, we first introduce a reverse filming behavior estimation technique. It optimizes camera trajectories by leveraging NeRF as a differentiable renderer and refining SMPL tracks. We then introduce a cinematic transfer pipeline that is able to transfer various shot types to a new 2D video or a 3D virtual environment. The incorporation of 3D engine workflow enables superior rendering and control abilities, which also achieves a higher rating in the user study.
Controllable Motion Diffusion Model
Jun 01, 2023



Generating realistic and controllable motions for virtual characters is a challenging task in computer animation, and its implications extend to games, simulations, and virtual reality. Recent studies have drawn inspiration from the success of diffusion models in image generation, demonstrating the potential for addressing this task. However, the majority of these studies have been limited to offline applications that target at sequence-level generation that generates all steps simultaneously. To enable real-time motion synthesis with diffusion models in response to time-varying control signals, we propose the framework of the Controllable Motion Diffusion Model (COMODO). Our framework begins with an auto-regressive motion diffusion model (A-MDM), which generates motion sequences step by step. In this way, simply using the standard DDPM algorithm without any additional complexity, our framework is able to generate high-fidelity motion sequences over extended periods with different types of control signals. Then, we propose our reinforcement learning-based controller and controlling strategies on top of the A-MDM model, so that our framework can steer the motion synthesis process across multiple tasks, including target reaching, joystick-based control, goal-oriented control, and trajectory following. The proposed framework enables the real-time generation of diverse motions that react adaptively to user commands on-the-fly, thereby enhancing the overall user experience. Besides, it is compatible with the inpainting-based editing methods and can predict much more diverse motions without additional fine-tuning of the basic motion generation models. We conduct comprehensive experiments to evaluate the effectiveness of our framework in performing various tasks and compare its performance against state-of-the-art methods.
Dynamic Storyboard Generation in an Engine-based Virtual Environment for Video Production
Jan 31, 2023


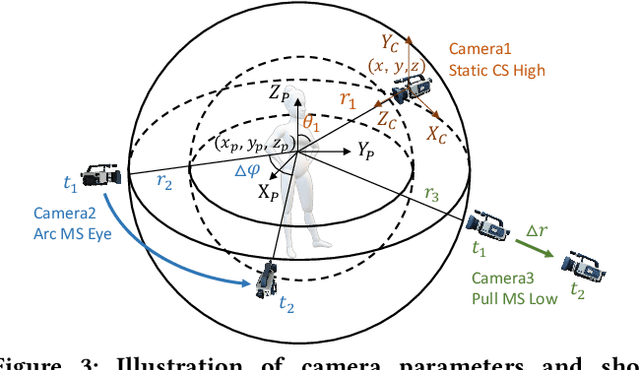
Amateurs working on mini-films and short-form videos usually spend lots of time and effort on the multi-round complicated process of setting and adjusting scenes, plots, and cameras to deliver satisfying video shots. We present Virtual Dynamic Storyboard (VDS) to allow users storyboarding shots in virtual environments, where the filming staff can easily test the settings of shots before the actual filming. VDS runs on a "propose-simulate-discriminate" mode: Given a formatted story script and a camera script as input, it generates several character animation and camera movement proposals following predefined story and cinematic rules to allow an off-the-shelf simulation engine to render videos. To pick up the top-quality dynamic storyboard from the candidates, we equip it with a shot ranking discriminator based on shot quality criteria learned from professional manual-created data. VDS is comprehensively validated via extensive experiments and user studies, demonstrating its efficiency, effectiveness, and great potential in assisting amateur video production.
Temporal and Contextual Transformer for Multi-Camera Editing of TV Shows
Oct 17, 2022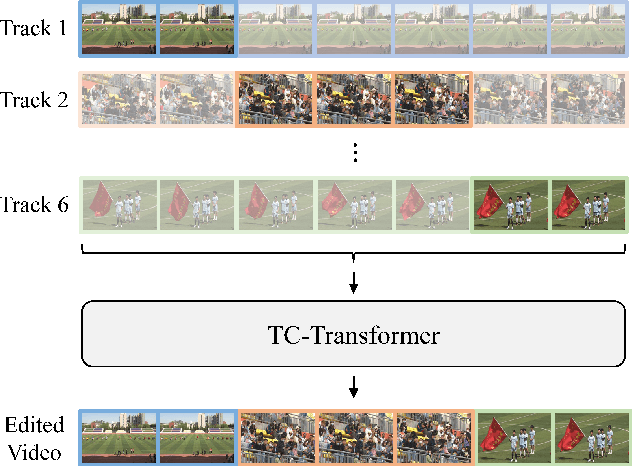
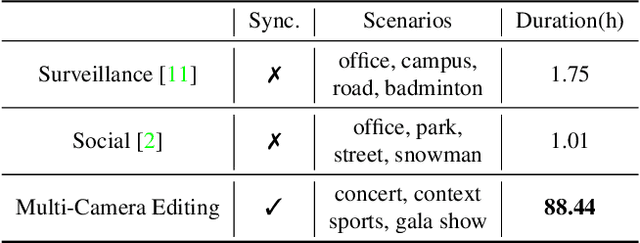

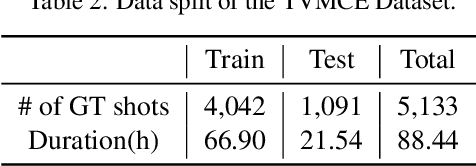
The ability to choose an appropriate camera view among multiple cameras plays a vital role in TV shows delivery. But it is hard to figure out the statistical pattern and apply intelligent processing due to the lack of high-quality training data. To solve this issue, we first collect a novel benchmark on this setting with four diverse scenarios including concerts, sports games, gala shows, and contests, where each scenario contains 6 synchronized tracks recorded by different cameras. It contains 88-hour raw videos that contribute to the 14-hour edited videos. Based on this benchmark, we further propose a new approach temporal and contextual transformer that utilizes clues from historical shots and other views to make shot transition decisions and predict which view to be used. Extensive experiments show that our method outperforms existing methods on the proposed multi-camera editing benchmark.
A Unified Framework for Shot Type Classification Based on Subject Centric Lens
Aug 08, 2020
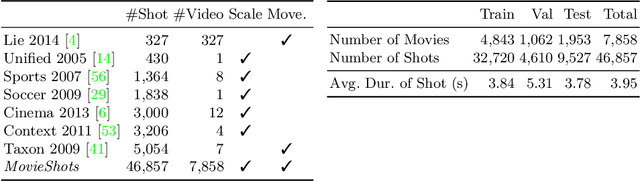

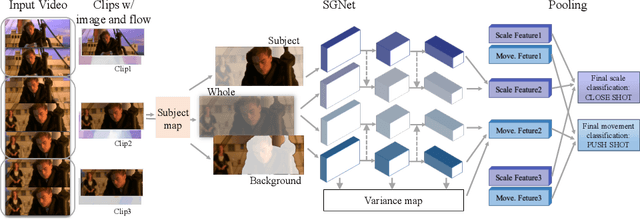
Shots are key narrative elements of various videos, e.g. movies, TV series, and user-generated videos that are thriving over the Internet. The types of shots greatly influence how the underlying ideas, emotions, and messages are expressed. The technique to analyze shot types is important to the understanding of videos, which has seen increasing demand in real-world applications in this era. Classifying shot type is challenging due to the additional information required beyond the video content, such as the spatial composition of a frame and camera movement. To address these issues, we propose a learning framework Subject Guidance Network (SGNet) for shot type recognition. SGNet separates the subject and background of a shot into two streams, serving as separate guidance maps for scale and movement type classification respectively. To facilitate shot type analysis and model evaluations, we build a large-scale dataset MovieShots, which contains 46K shots from 7K movie trailers with annotations of their scale and movement types. Experiments show that our framework is able to recognize these two attributes of shot accurately, outperforming all the previous methods.