 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAGE: A Stream-Centric Generative World Model for Long-Horizon Driving-Scene Simulation
Jun 16, 2025The generation of temporally consistent, high-fidelity driving videos over extended horizons presents a fundamental challenge in autonomous driving world modeling. Existing approaches often suffer from error accumulation and feature misalignment due to inadequate decoupling of spatio-temporal dynamics and limited cross-frame feature propagation mechanisms. To address these limitations, we present STAGE (Streaming Temporal Attention Generative Engine), a novel auto-regressive framework that pioneers hierarchical feature coordination and multi-phase optimization for sustainable video synthesis. To achieve high-quality long-horizon driving video generation, we introduce Hierarchical Temporal Feature Transfer (HTFT) and a novel multi-stage training strategy. HTFT enhances temporal consistency between video frames throughout the video generation process by modeling the temporal and denoising process separately and transferring denoising features between frames. The multi-stage training strategy is to divide the training into three stages, through model decoupling and auto-regressive inference process simulation, thereby accelerating model convergence and reducing error accumulation. Experiments on the Nuscenes dataset show that STAGE has significantly surpassed existing methods in the long-horizon driving video generation task. In addition, we also explored STAGE's ability to generate unlimited-length driving videos. We generated 600 frames of high-quality driving videos on the Nuscenes dataset, which far exceeds the maximum length achievable by existing methods.
PARTNER: Level up the Polar Representation for LiDAR 3D Object Detection
Aug 08, 2023



Recently, polar-based representation has shown promising properties in perceptual tasks. In addition to Cartesian-based approaches, which separate point clouds unevenly, representing point clouds as polar grids has been recognized as an alternative due to (1) its advantage in robust performance under different resolutions and (2) its superiority in streaming-based approaches. However, state-of-the-art polar-based detection methods inevitably suffer from the feature distortion problem because of the non-uniform division of polar representation, resulting in a non-negligible performance gap compared to Cartesian-based approaches. To tackle this issue, we present PARTNER, a novel 3D object detector in the polar coordinate. PARTNER alleviates the dilemma of feature distortion with global representation re-alignment and facilitates the regression by introducing instance-level geometric information into the detection head. Extensive experiments show overwhelming advantages in streaming-based detection and different resolutions. Furthermore, our method outperforms the previous polar-based works with remarkable margins of 3.68% and 9.15% on Waymo and ONCE validation set, thus achieving competitive results over the state-of-the-art methods.
CLIP$^2$: Contrastive Language-Image-Point Pretraining from Real-World Point Cloud Data
Mar 26, 2023
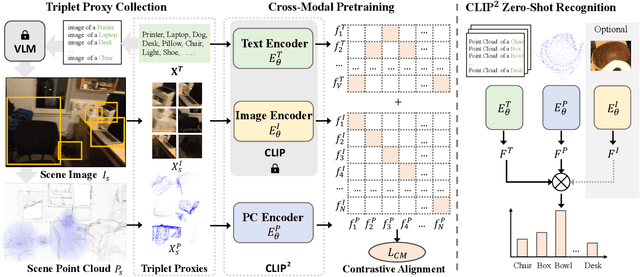

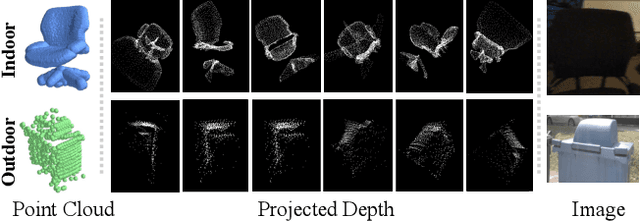
Contrastive Language-Image Pre-training, benefiting from large-scale unlabeled text-image pairs, has demonstrated great performance in open-world vision understanding tasks. However, due to the limited Text-3D data pairs, adapting the success of 2D Vision-Language Models (VLM) to the 3D space remains an open problem. Existing works that leverage VLM for 3D understanding generally resort to constructing intermediate 2D representations for the 3D data, but at the cost of losing 3D geometry information. To take a step toward open-world 3D vision understanding, we propose Contrastive Language-Image-Point Cloud Pretraining (CLIP$^2$) to directly learn the transferable 3D point cloud representation in realistic scenarios with a novel proxy alignment mechanism. Specifically, we exploit naturally-existed correspondences in 2D and 3D scenarios, and build well-aligned and instance-based text-image-point proxies from those complex scenarios. On top of that, we propose a cross-modal contrastive objective to learn semantic and instance-level aligned point cloud representation. Experimental results on both indoor and outdoor scenarios show that our learned 3D representation has great transfer ability in downstream tasks, including zero-shot and few-shot 3D recognition, which boosts the state-of-the-art methods by large margins. Furthermore, we provide analyses of the capability of different representations in real scenarios and present the optional ensemble scheme.
TransFusion: Robust LiDAR-Camera Fusion for 3D Object Detection with Transformers
Mar 22, 2022
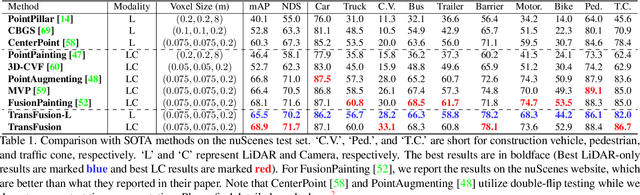
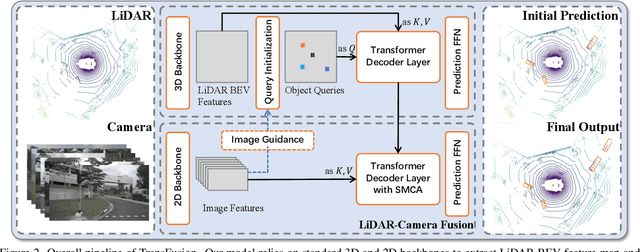
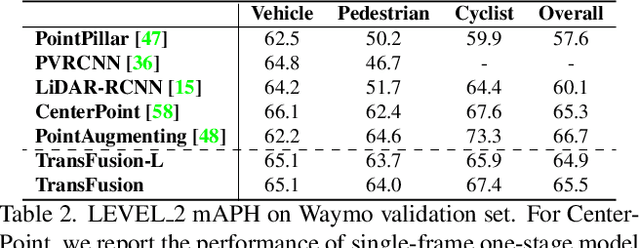
LiDAR and camera are two important sensors for 3D object detection in autonomous driving. Despite the increasing popularity of sensor fusion in this field, the robustness against inferior image conditions, e.g., bad illumination and sensor misalignment, is under-explored. Existing fusion methods are easily affected by such conditions, mainly due to a hard association of LiDAR points and image pixels, established by calibration matrices. We propose TransFusion, a robust solution to LiDAR-camera fusion with a soft-association mechanism to handle inferior image conditions. Specifically, our TransFusion consists of convolutional backbones and a detection head based on a transformer decoder. The first layer of the decoder predicts initial bounding boxes from a LiDAR point cloud using a sparse set of object queries, and its second decoder layer adaptively fuses the object queries with useful image features, leveraging both spatial and contextual relationships. The attention mechanism of the transformer enables our model to adaptively determine where and what information should be taken from the image, leading to a robust and effective fusion strategy. We additionally design an image-guided query initialization strategy to deal with objects that are difficult to detect in point clouds. TransFusion achieves state-of-the-art performance on large-scale datasets. We provide extensive experiments to demonstrate its robustness against degenerated image quality and calibration errors. We also extend the proposed method to the 3D tracking task and achieve the 1st place in the leaderboard of nuScenes tracking, showing its effectiveness and generalization capability.
Adversarial Robustness under Long-Tailed Distribution
Apr 06, 2021

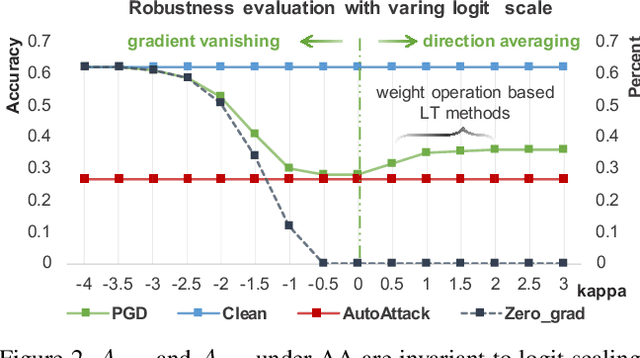

Adversarial robustness has attracted extensive studies recently by revealing the vulnerability and intrinsic characteristics of deep networks. However, existing works on adversarial robustness mainly focus on balanced datasets, while real-world data usually exhibits a long-tailed distribution. To push adversarial robustness towards more realistic scenarios, in this work we investigate the adversarial vulnerability as well as defense under long-tailed distributions. In particular, we first reveal the negative impacts induced by imbalanced data on both recognition performance and adversarial robustness, uncovering the intrinsic challenges of this problem. We then perform a systematic study on existing long-tailed recognition methods in conjunction with the adversarial training framework. Several valuable observations are obtained: 1) natural accuracy is relatively easy to improve, 2) fake gain of robust accuracy exists under unreliable evaluation, and 3) boundary error limits the promotion of robustness. Inspired by these observations, we propose a clean yet effective framework, RoBal, which consists of two dedicated modules, a scale-invariant classifier and data re-balancing via both margin engineering at training stage and boundary adjustment during inference. Extensive experiments demonstrate the superiority of our approach over other state-of-the-art defense methods. To our best knowledge, we are the first to tackle adversarial robustness under long-tailed distributions, which we believe would be a significant step towards real-world robustness. Our code is available at: https://github.com/wutong16/Adversarial_Long-Tail .
A Unified Framework for Shot Type Classification Based on Subject Centric Lens
Aug 08, 2020
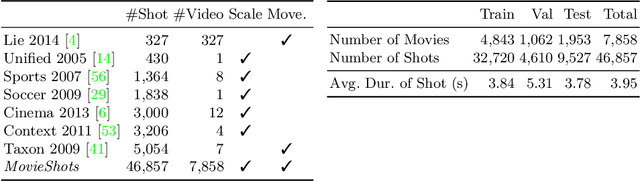

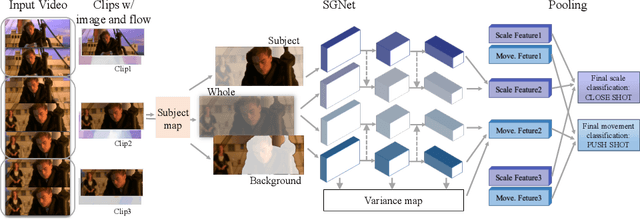
Shots are key narrative elements of various videos, e.g. movies, TV series, and user-generated videos that are thriving over the Internet. The types of shots greatly influence how the underlying ideas, emotions, and messages are expressed. The technique to analyze shot types is important to the understanding of videos, which has seen increasing demand in real-world applications in this era. Classifying shot type is challenging due to the additional information required beyond the video content, such as the spatial composition of a frame and camera movement. To address these issues, we propose a learning framework Subject Guidance Network (SGNet) for shot type recognition. SGNet separates the subject and background of a shot into two streams, serving as separate guidance maps for scale and movement type classification respectively. To facilitate shot type analysis and model evaluations, we build a large-scale dataset MovieShots, which contains 46K shots from 7K movie trailers with annotations of their scale and movement types. Experiments show that our framework is able to recognize these two attributes of shot accurately, outperforming all the previous methods.
Online Multi-modal Person Search in Videos
Aug 08, 2020
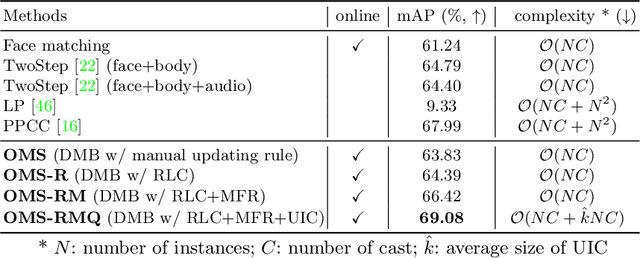
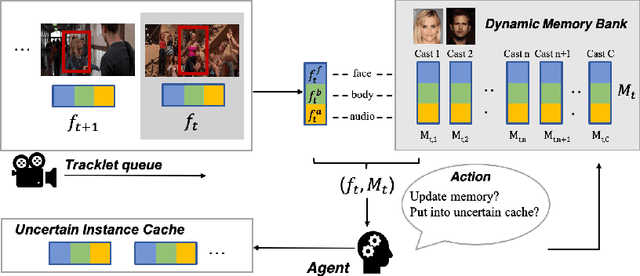
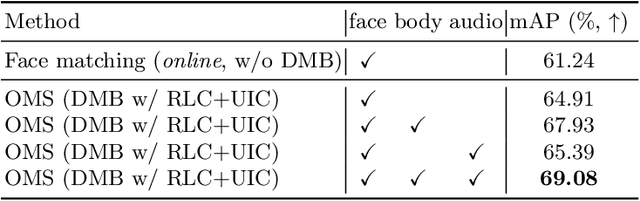
The task of searching certain people in videos has seen increasing potential in real-world applications, such as video organization and editing. Most existing approaches are devised to work in an offline manner, where identities can only be inferred after an entire video is examined. This working manner precludes such methods from being applied to online services or those applications that require real-time responses. In this paper, we propose an online person search framework, which can recognize people in a video on the fly. This framework maintains a multimodal memory bank at its heart as the basis for person recognition, and updates it dynamically with a policy obtained by reinforcement learning. Our experiments on a large movie dataset show that the proposed method is effective, not only achieving remarkable improvements over online schemes but also outperforming offline methods.
Distribution-Balanced Loss for Multi-Label Classification in Long-Tailed Datasets
Jul 25, 2020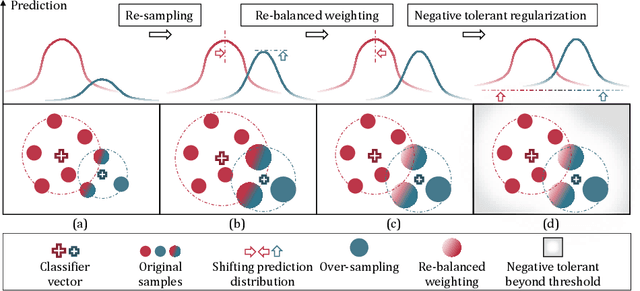

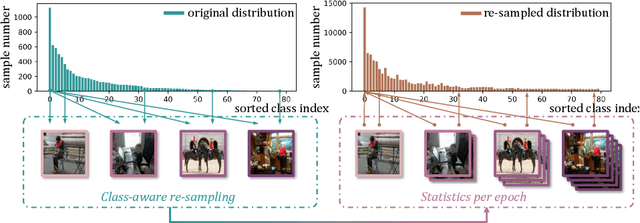
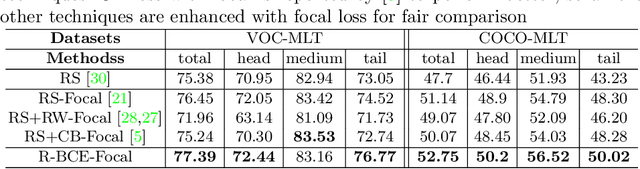
We present a new loss function called Distribution-Balanced Loss for the multi-label recognition problems that exhibit long-tailed class distributions. Compared to conventional single-label classification problem, multi-label recognition problems are often more challenging due to two significant issues, namely the co-occurrence of labels and the dominance of negative labels (when treated as multiple binary classification problems). The Distribution-Balanced Loss tackles these issues through two key modifications to the standard binary cross-entropy loss: 1) a new way to re-balance the weights that takes into account the impact caused by label co-occurrence, and 2) a negative tolerant regularization to mitigate the over-suppression of negative labels. Experiments on both Pascal VOC and COCO show that the models trained with this new loss function achieve significant performance gains over existing methods. Code and models are available at: https://github.com/wutong16/DistributionBalancedLoss .
MovieNet: A Holistic Dataset for Movie Understanding
Jul 21, 2020

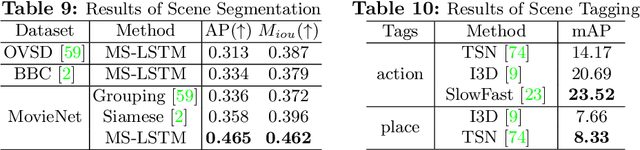

Recent years have seen remarkable advances in visual understanding. However, how to understand a story-based long video with artistic styles, e.g. movie, remains challenging. In this paper, we introduce MovieNet -- a holistic dataset for movie understanding. MovieNet contains 1,100 movies with a large amount of multi-modal data, e.g. trailers, photos, plot descriptions, etc. Besides, different aspects of manual annotations are provided in MovieNet, including 1.1M characters with bounding boxes and identities, 42K scene boundaries, 2.5K aligned description sentences, 65K tags of place and action, and 92K tags of cinematic style. To the best of our knowledge, MovieNet is the largest dataset with richest annotations for comprehensive movie understanding. Based on MovieNet, we set up several benchmarks for movie understanding from different angles. Extensive experiments are executed on these benchmarks to show the immeasurable value of MovieNet and the gap of current approaches towards comprehensive movie understanding. We believe that such a holistic dataset would promote the researches on story-based long video understanding and beyond. MovieNet will be published in compliance with regulations at https://movienet.github.io.
Placepedia: Comprehensive Place Understanding with Multi-Faceted Annotations
Jul 17, 2020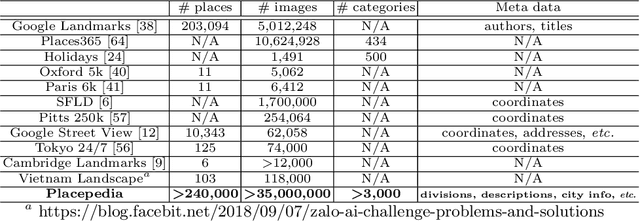



Place is an important element in visual understanding. Given a photo of a building, people can often tell its functionality, e.g. a restaurant or a shop, its cultural style, e.g. Asian or European, as well as its economic type, e.g. industry oriented or tourism oriented. While place recognition has been widely studied in previous work, there remains a long way towards comprehensive place understanding, which is far beyond categorizing a place with an image and requires information of multiple aspects. In this work, we contribute Placepedia, a large-scale place dataset with more than 35M photos from 240K unique places. Besides the photos, each place also comes with massive multi-faceted information, e.g. GDP, population, etc., and labels at multiple levels, including function, city, country, etc.. This dataset, with its large amount of data and rich annotations, allows various studies to be conducted. Particularly, in our studies, we develop 1) PlaceNet, a unified framework for multi-level place recognition, and 2) a method for city embedding, which can produce a vector representation for a city that captures both visual and multi-faceted side information. Such studies not only reveal key challenges in place understanding, but also establish connections between visual observations and underlying socioeconomic/cultural implications.