 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePARTNER: Level up the Polar Representation for LiDAR 3D Object Detection
Aug 08, 2023



Recently, polar-based representation has shown promising properties in perceptual tasks. In addition to Cartesian-based approaches, which separate point clouds unevenly, representing point clouds as polar grids has been recognized as an alternative due to (1) its advantage in robust performance under different resolutions and (2) its superiority in streaming-based approaches. However, state-of-the-art polar-based detection methods inevitably suffer from the feature distortion problem because of the non-uniform division of polar representation, resulting in a non-negligible performance gap compared to Cartesian-based approaches. To tackle this issue, we present PARTNER, a novel 3D object detector in the polar coordinate. PARTNER alleviates the dilemma of feature distortion with global representation re-alignment and facilitates the regression by introducing instance-level geometric information into the detection head. Extensive experiments show overwhelming advantages in streaming-based detection and different resolutions. Furthermore, our method outperforms the previous polar-based works with remarkable margins of 3.68% and 9.15% on Waymo and ONCE validation set, thus achieving competitive results over the state-of-the-art methods.
FULLER: Unified Multi-modality Multi-task 3D Perception via Multi-level Gradient Calibration
Jul 31, 2023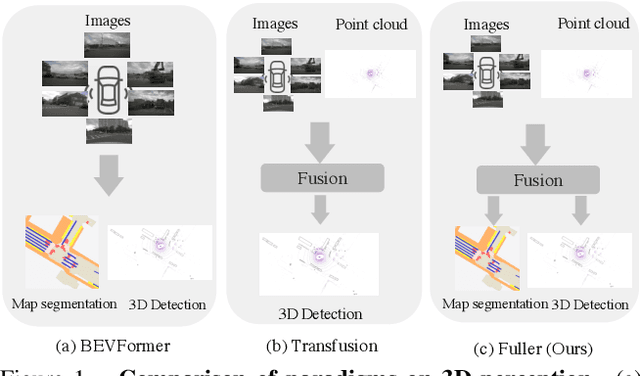
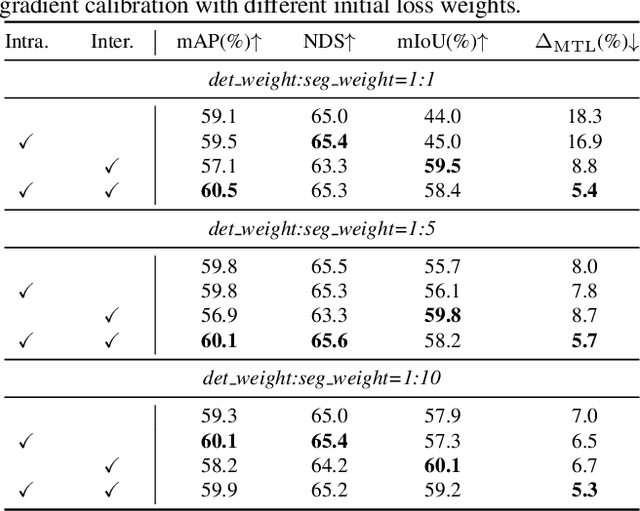
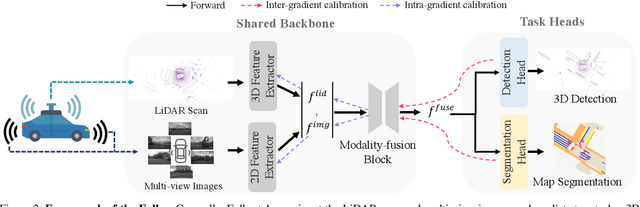
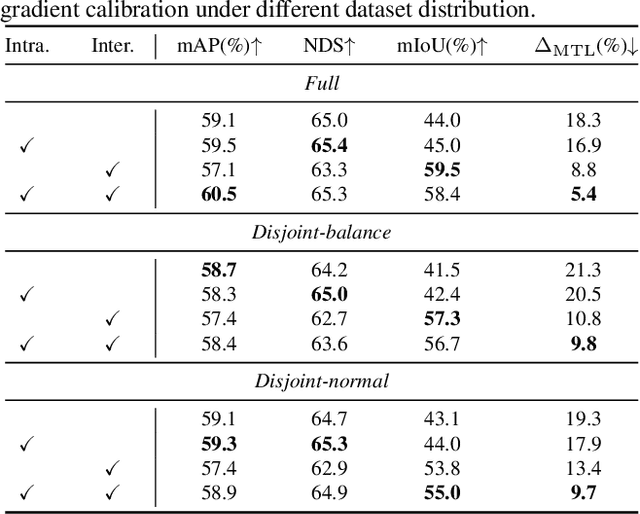
Multi-modality fusion and multi-task learning are becoming trendy in 3D autonomous driving scenario, considering robust prediction and computation budget. However, naively extending the existing framework to the domain of multi-modality multi-task learning remains ineffective and even poisonous due to the notorious modality bias and task conflict. Previous works manually coordinate the learning framework with empirical knowledge, which may lead to sub-optima. To mitigate the issue, we propose a novel yet simple multi-level gradient calibration learning framework across tasks and modalities during optimization. Specifically, the gradients, produced by the task heads and used to update the shared backbone, will be calibrated at the backbone's last layer to alleviate the task conflict. Before the calibrated gradients are further propagated to the modality branches of the backbone, their magnitudes will be calibrated again to the same level, ensuring the downstream tasks pay balanced attention to different modalities. Experiments on large-scale benchmark nuScenes demonstrate the effectiveness of the proposed method, eg, an absolute 14.4% mIoU improvement on map segmentation and 1.4% mAP improvement on 3D detection, advancing the application of 3D autonomous driving in the domain of multi-modality fusion and multi-task learning. We also discuss the links between modalities and tasks.
CLIP$^2$: Contrastive Language-Image-Point Pretraining from Real-World Point Cloud Data
Mar 26, 2023
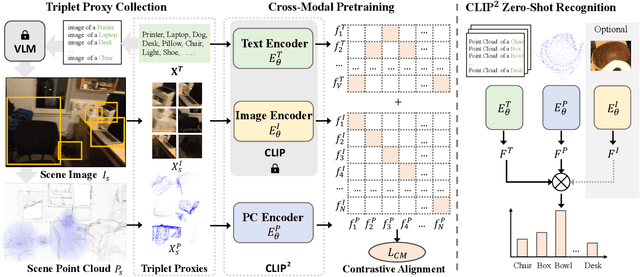

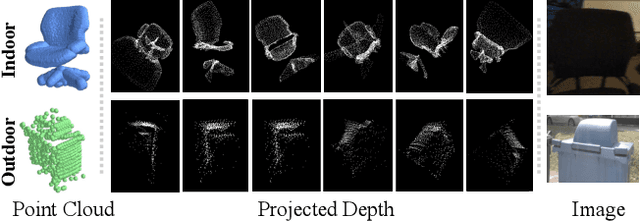
Contrastive Language-Image Pre-training, benefiting from large-scale unlabeled text-image pairs, has demonstrated great performance in open-world vision understanding tasks. However, due to the limited Text-3D data pairs, adapting the success of 2D Vision-Language Models (VLM) to the 3D space remains an open problem. Existing works that leverage VLM for 3D understanding generally resort to constructing intermediate 2D representations for the 3D data, but at the cost of losing 3D geometry information. To take a step toward open-world 3D vision understanding, we propose Contrastive Language-Image-Point Cloud Pretraining (CLIP$^2$) to directly learn the transferable 3D point cloud representation in realistic scenarios with a novel proxy alignment mechanism. Specifically, we exploit naturally-existed correspondences in 2D and 3D scenarios, and build well-aligned and instance-based text-image-point proxies from those complex scenarios. On top of that, we propose a cross-modal contrastive objective to learn semantic and instance-level aligned point cloud representation. Experimental results on both indoor and outdoor scenarios show that our learned 3D representation has great transfer ability in downstream tasks, including zero-shot and few-shot 3D recognition, which boosts the state-of-the-art methods by large margins. Furthermore, we provide analyses of the capability of different representations in real scenarios and present the optional ensemble scheme.
DevNet: Self-supervised Monocular Depth Learning via Density Volume Construction
Sep 20, 2022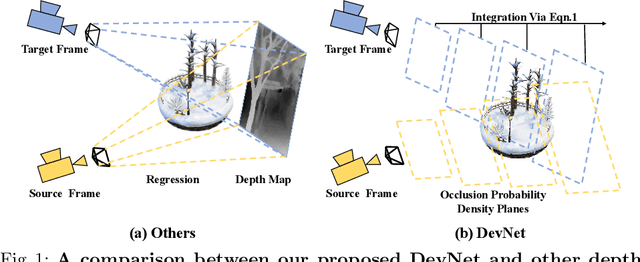
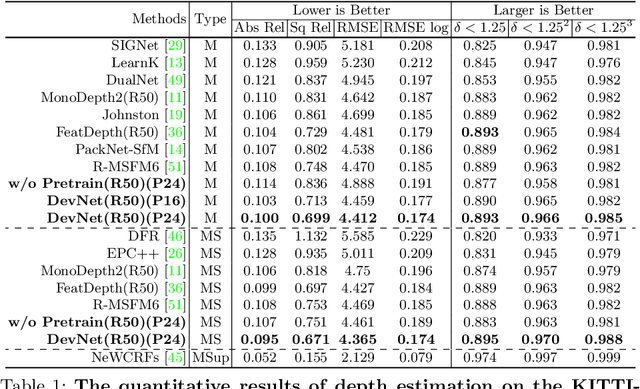
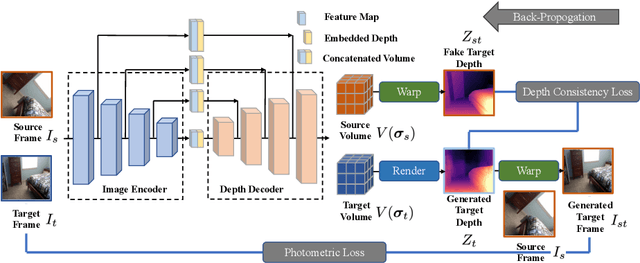

Self-supervised depth learning from monocular images normally relies on the 2D pixel-wise photometric relation between temporally adjacent image frames. However, they neither fully exploit the 3D point-wise geometric correspondences, nor effectively tackle the ambiguities in the photometric warping caused by occlusions or illumination inconsistency. To address these problems, this work proposes Density Volume Construction Network (DevNet), a novel self-supervised monocular depth learning framework, that can consider 3D spatial information, and exploit stronger geometric constraints among adjacent camera frustums. Instead of directly regressing the pixel value from a single image, our DevNet divides the camera frustum into multiple parallel planes and predicts the pointwise occlusion probability density on each plane. The final depth map is generated by integrating the density along corresponding rays. During the training process, novel regularization strategies and loss functions are introduced to mitigate photometric ambiguities and overfitting. Without obviously enlarging model parameters size or running time, DevNet outperforms several representative baselines on both the KITTI-2015 outdoor dataset and NYU-V2 indoor dataset. In particular, the root-mean-square-deviation is reduced by around 4% with DevNet on both KITTI-2015 and NYU-V2 in the task of depth estimation. Code is available at https://github.com/gitkaichenzhou/DevNet.
ONCE-3DLanes: Building Monocular 3D Lane Detection
May 14, 2022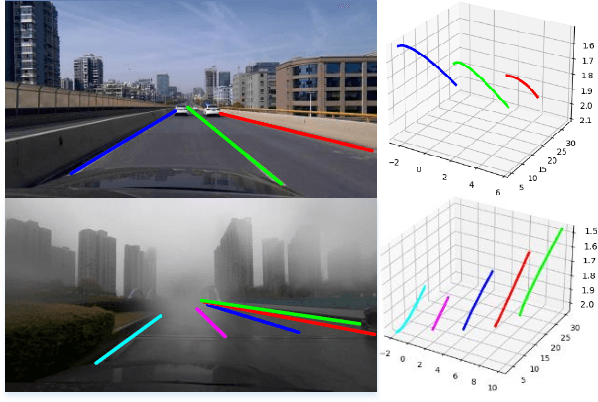
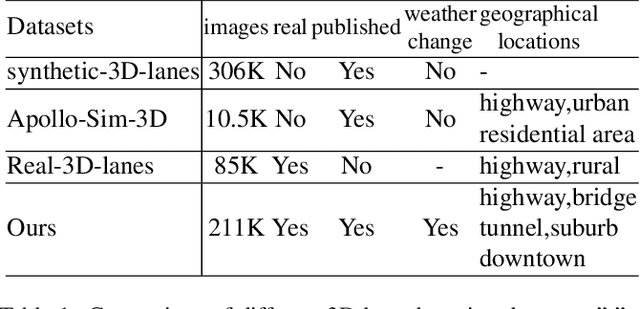
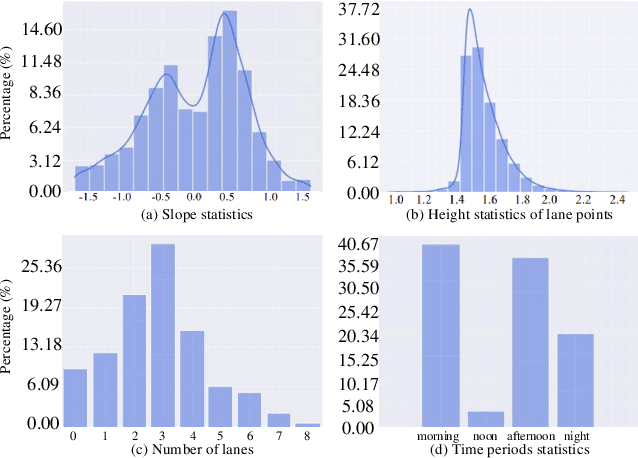
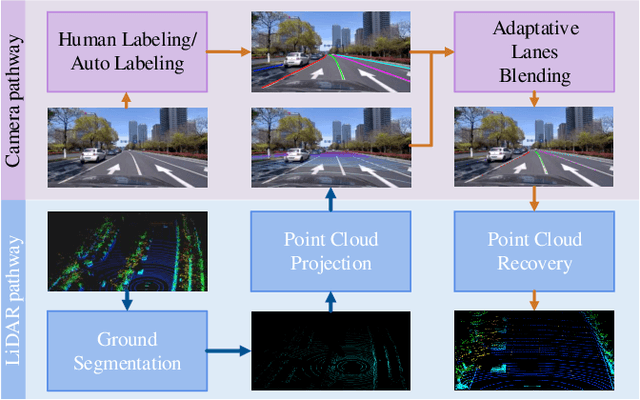
We present ONCE-3DLanes, a real-world autonomous driving dataset with lane layout annotation in 3D space. Conventional 2D lane detection from a monocular image yields poor performance of following planning and control tasks in autonomous driving due to the case of uneven road. Predicting the 3D lane layout is thus necessary and enables effective and safe driving. However, existing 3D lane detection datasets are either unpublished or synthesized from a simulated environment, severely hampering the development of this field. In this paper, we take steps towards addressing these issues. By exploiting the explicit relationship between point clouds and image pixels, a dataset annotation pipeline is designed to automatically generate high-quality 3D lane locations from 2D lane annotations in 211K road scenes. In addition, we present an extrinsic-free, anchor-free method, called SALAD, regressing the 3D coordinates of lanes in image view without converting the feature map into the bird's-eye view (BEV). To facilitate future research on 3D lane detection, we benchmark the dataset and provide a novel evaluation metric, performing extensive experiments of both existing approaches and our proposed method. The aim of our work is to revive the interest of 3D lane detection in a real-world scenario. We believe our work can lead to the expected and unexpected innovations in both academia and industry.
CODA: A Real-World Road Corner Case Dataset for Object Detection in Autonomous Driving
Mar 15, 2022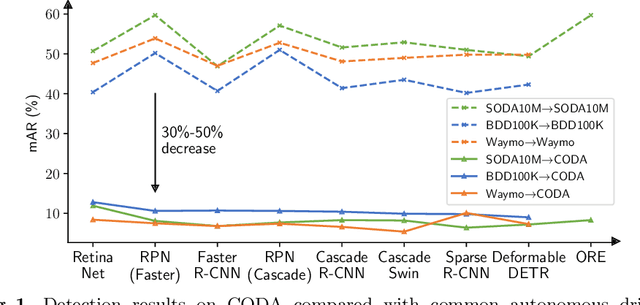
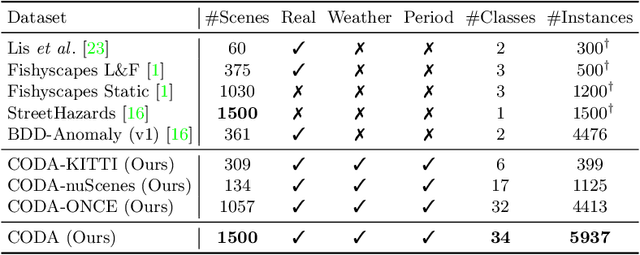

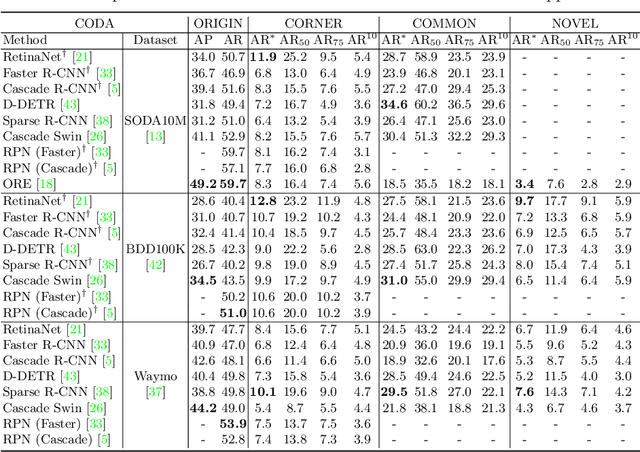
Contemporary deep-learning object detection methods for autonomous driving usually assume prefixed categories of common traffic participants, such as pedestrians and cars. Most existing detectors are unable to detect uncommon objects and corner cases (e.g., a dog crossing a street), which may lead to severe accidents in some situations, making the timeline for the real-world application of reliable autonomous driving uncertain. One main reason that impedes the development of truly reliably self-driving systems is the lack of public datasets for evaluating the performance of object detectors on corner cases. Hence, we introduce a challenging dataset named CODA that exposes this critical problem of vision-based detectors. The dataset consists of 1500 carefully selected real-world driving scenes, each containing four object-level corner cases (on average), spanning 30+ object categories. On CODA, the performance of standard object detectors trained on large-scale autonomous driving datasets significantly drops to no more than 12.8% in mAR. Moreover, we experiment with the state-of-the-art open-world object detector and find that it also fails to reliably identify the novel objects in CODA, suggesting that a robust perception system for autonomous driving is probably still far from reach. We expect our CODA dataset to facilitate further research in reliable detection for real-world autonomous driving. Our dataset will be released at https://coda-dataset.github.io.
SODA10M: Towards Large-Scale Object Detection Benchmark for Autonomous Driving
Jun 22, 2021

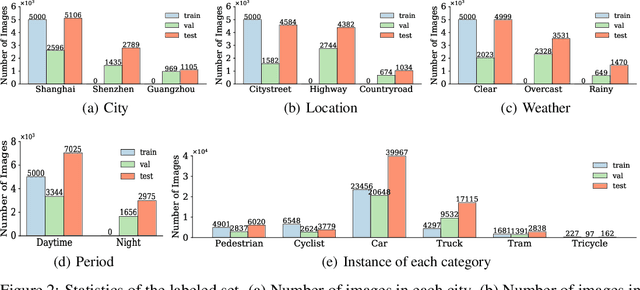
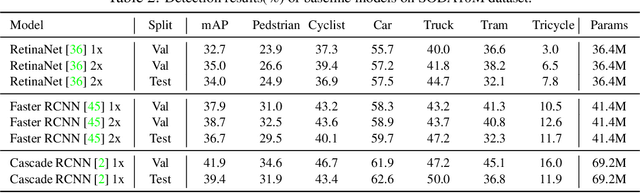
Aiming at facilitating a real-world, ever-evolving and scalable autonomous driving system, we present a large-scale benchmark for standardizing the evaluation of different self-supervised and semi-supervised approaches by learning from raw data, which is the first and largest benchmark to date. Existing autonomous driving systems heavily rely on `perfect' visual perception models (e.g., detection) trained using extensive annotated data to ensure the safety. However, it is unrealistic to elaborately label instances of all scenarios and circumstances (e.g., night, extreme weather, cities) when deploying a robust autonomous driving system. Motivated by recent powerful advances of self-supervised and semi-supervised learning, a promising direction is to learn a robust detection model by collaboratively exploiting large-scale unlabeled data and few labeled data. Existing dataset (e.g., KITTI, Waymo) either provides only a small amount of data or covers limited domains with full annotation, hindering the exploration of large-scale pre-trained models. Here, we release a Large-Scale Object Detection benchmark for Autonomous driving, named as SODA10M, containing 10 million unlabeled images and 20K images labeled with 6 representative object categories. To improve diversity, the images are collected every ten seconds per frame within 32 different cities under different weather conditions, periods and location scenes. We provide extensive experiments and deep analyses of existing supervised state-of-the-art detection models, popular self-supervised and semi-supervised approaches, and some insights about how to develop future models. The data and more up-to-date information have been released at https://soda-2d.github.io.
One Million Scenes for Autonomous Driving: ONCE Dataset
Jun 21, 2021
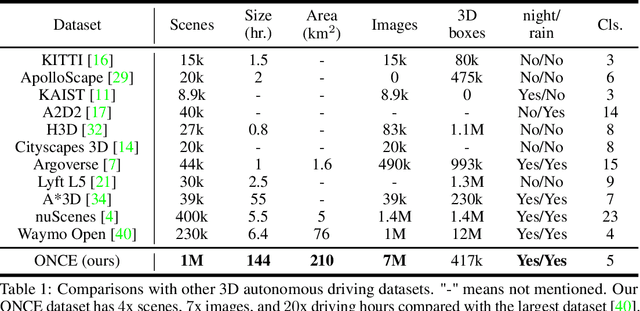
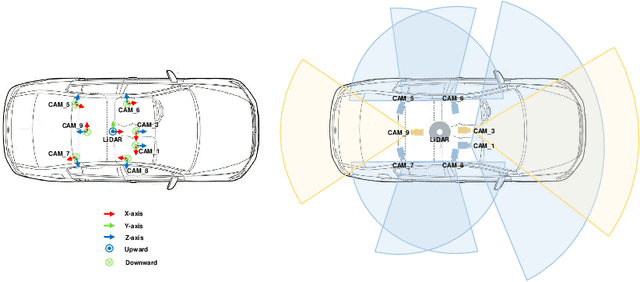

Current perception models in autonomous driving have become notorious for greatly relying on a mass of annotated data to cover unseen cases and address the long-tail problem. On the other hand, learning from unlabeled large-scale collected data and incrementally self-training powerful recognition models have received increasing attention and may become the solutions of next-generation industry-level powerful and robust perception models in autonomous driving. However, the research community generally suffered from data inadequacy of those essential real-world scene data, which hampers the future exploration of fully/semi/self-supervised methods for 3D perception. In this paper, we introduce the ONCE (One millioN sCenEs) dataset for 3D object detection in the autonomous driving scenario. The ONCE dataset consists of 1 million LiDAR scenes and 7 million corresponding camera images. The data is selected from 144 driving hours, which is 20x longer than the largest 3D autonomous driving dataset available (e.g. nuScenes and Waymo), and it is collected across a range of different areas, periods and weather conditions. To facilitate future research on exploiting unlabeled data for 3D detection, we additionally provide a benchmark in which we reproduce and evaluate a variety of self-supervised and semi-supervised methods on the ONCE dataset. We conduct extensive analyses on those methods and provide valuable observations on their performance related to the scale of used data. Data, code, and more information are available at https://once-for-auto-driving.github.io/index.html.