 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Two-Tower Matching: Learning Sparse Retrievable Cross-Interactions for Recommendation
Nov 30, 2023Two-tower models are a prevalent matching framework for recommendation, which have been widely deployed in industrial applications. The success of two-tower matching attributes to its efficiency in retrieval among a large number of items, since the item tower can be precomputed and used for fast Approximate Nearest Neighbor (ANN) search. However, it suffers two main challenges, including limited feature interaction capability and reduced accuracy in online serving. Existing approaches attempt to design novel late interactions instead of dot products, but they still fail to support complex feature interactions or lose retrieval efficiency. To address these challenges, we propose a new matching paradigm named SparCode, which supports not only sophisticated feature interactions but also efficient retrieval. Specifically, SparCode introduces an all-to-all interaction module to model fine-grained query-item interactions. Besides, we design a discrete code-based sparse inverted index jointly trained with the model to achieve effective and efficient model inference. Extensive experiments have been conducted on open benchmark datasets to demonstrate the superiority of our framework. The results show that SparCode significantly improves the accuracy of candidate item matching while retaining the same level of retrieval efficiency with two-tower models. Our source code will be available at MindSpore/models.
Diffusion Augmentation for Sequential Recommendation
Sep 22, 2023



Sequential recommendation (SRS) has become the technical foundation in many applications recently, which aims to recommend the next item based on the user's historical interactions. However, sequential recommendation often faces the problem of data sparsity, which widely exists in recommender systems. Besides, most users only interact with a few items, but existing SRS models often underperform these users. Such a problem, named the long-tail user problem, is still to be resolved. Data augmentation is a distinct way to alleviate these two problems, but they often need fabricated training strategies or are hindered by poor-quality generated interactions. To address these problems, we propose a Diffusion Augmentation for Sequential Recommendation (DiffuASR) for a higher quality generation. The augmented dataset by DiffuASR can be used to train the sequential recommendation models directly, free from complex training procedures. To make the best of the generation ability of the diffusion model, we first propose a diffusion-based pseudo sequence generation framework to fill the gap between image and sequence generation. Then, a sequential U-Net is designed to adapt the diffusion noise prediction model U-Net to the discrete sequence generation task. At last, we develop two guide strategies to assimilate the preference between generated and origin sequences. To validate the proposed DiffuASR, we conduct extensive experiments on three real-world datasets with three sequential recommendation models. The experimental results illustrate the effectiveness of DiffuASR. As far as we know, DiffuASR is one pioneer that introduce the diffusion model to the recommendation.
HAMUR: Hyper Adapter for Multi-Domain Recommendation
Sep 12, 2023Multi-Domain Recommendation (MDR) has gained significant attention in recent years, which leverages data from multiple domains to enhance their performance concurrently.However, current MDR models are confronted with two limitations. Firstly, the majority of these models adopt an approach that explicitly shares parameters between domains, leading to mutual interference among them. Secondly, due to the distribution differences among domains, the utilization of static parameters in existing methods limits their flexibility to adapt to diverse domains. To address these challenges, we propose a novel model Hyper Adapter for Multi-Domain Recommendation (HAMUR). Specifically, HAMUR consists of two components: (1). Domain-specific adapter, designed as a pluggable module that can be seamlessly integrated into various existing multi-domain backbone models, and (2). Domain-shared hyper-network, which implicitly captures shared information among domains and dynamically generates the parameters for the adapter. We conduct extensive experiments on two public datasets using various backbone networks. The experimental results validate the effectiveness and scalability of the proposed model.
NFTVis: Visual Analysis of NFT Performance
Jun 05, 2023



A non-fungible token (NFT) is a data unit stored on the blockchain. Nowadays, more and more investors and collectors (NFT traders), who participate in transactions of NFTs, have an urgent need to assess the performance of NFTs. However, there are two challenges for NFT traders when analyzing the performance of NFT. First, the current rarity models have flaws and are sometimes not convincing. In addition, NFT performance is dependent on multiple factors, such as images (high-dimensional data), history transactions (network), and market evolution (time series). It is difficult to take comprehensive consideration and analyze NFT performance efficiently. To address these challenges, we propose NFTVis, a visual analysis system that facilitates assessing individual NFT performance. A new NFT rarity model is proposed to quantify NFTs with images. Four well-coordinated views are designed to represent the various factors affecting the performance of the NFT. Finally, we evaluate the usefulness and effectiveness of our system using two case studies and user studies.
ONCE-3DLanes: Building Monocular 3D Lane Detection
May 14, 2022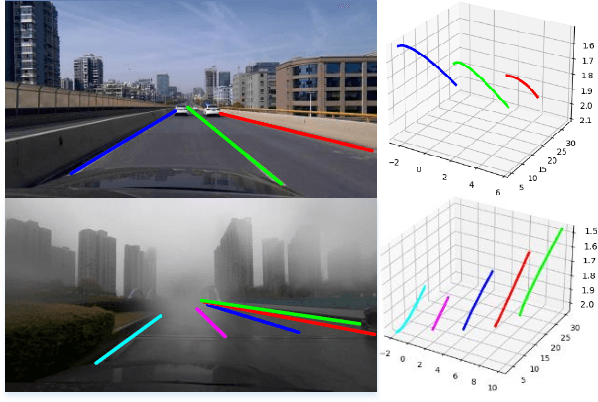
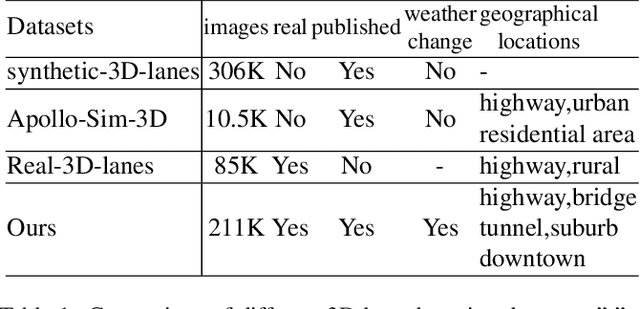
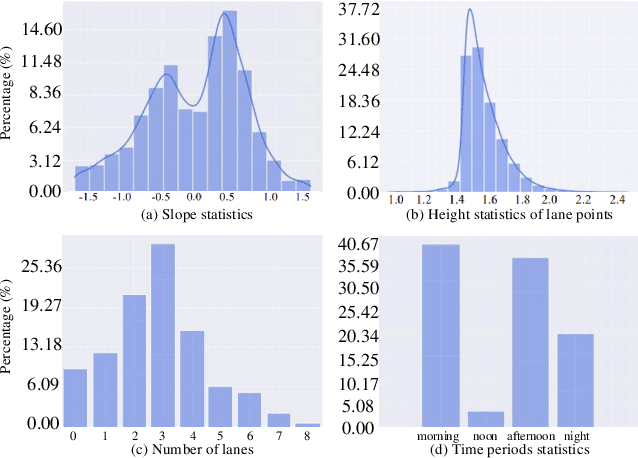
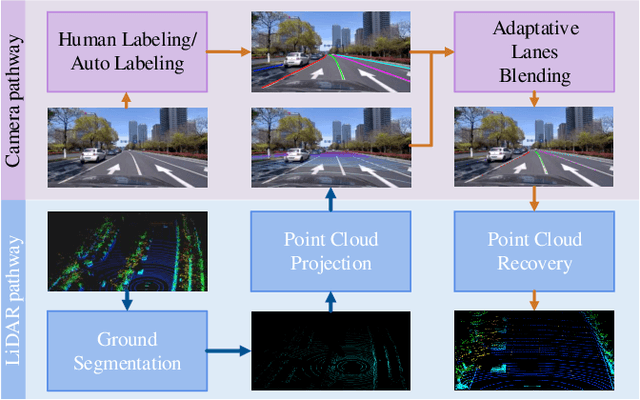
We present ONCE-3DLanes, a real-world autonomous driving dataset with lane layout annotation in 3D space. Conventional 2D lane detection from a monocular image yields poor performance of following planning and control tasks in autonomous driving due to the case of uneven road. Predicting the 3D lane layout is thus necessary and enables effective and safe driving. However, existing 3D lane detection datasets are either unpublished or synthesized from a simulated environment, severely hampering the development of this field. In this paper, we take steps towards addressing these issues. By exploiting the explicit relationship between point clouds and image pixels, a dataset annotation pipeline is designed to automatically generate high-quality 3D lane locations from 2D lane annotations in 211K road scenes. In addition, we present an extrinsic-free, anchor-free method, called SALAD, regressing the 3D coordinates of lanes in image view without converting the feature map into the bird's-eye view (BEV). To facilitate future research on 3D lane detection, we benchmark the dataset and provide a novel evaluation metric, performing extensive experiments of both existing approaches and our proposed method. The aim of our work is to revive the interest of 3D lane detection in a real-world scenario. We believe our work can lead to the expected and unexpected innovations in both academia and industry.
DINs: Deep Interactive Networks for Neurofibroma Segmentation in Neurofibromatosis Type 1 on Whole-Body MRI
Jun 07, 2021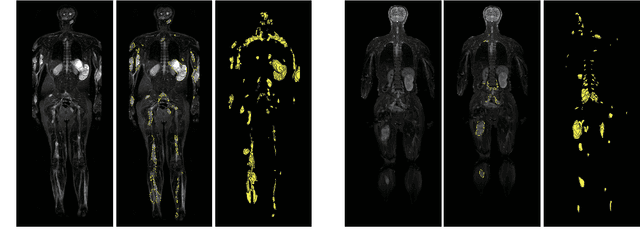
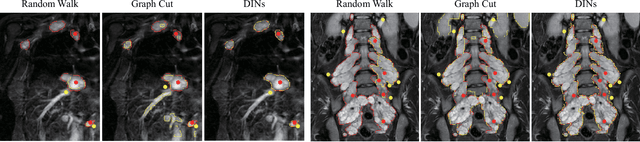
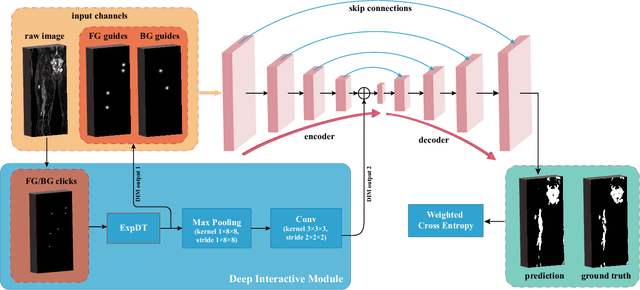
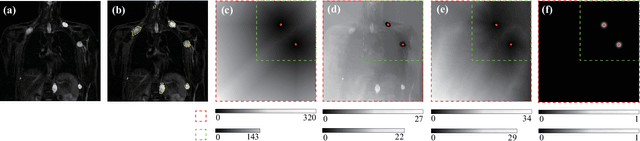
Neurofibromatosis type 1 (NF1) is an autosomal dominant tumor predisposition syndrome that involves the central and peripheral nervous systems. Accurate detection and segmentation of neurofibromas are essential for assessing tumor burden and longitudinal tumor size changes. Automatic convolutional neural networks (CNNs) are sensitive and vulnerable as tumors' variable anatomical location and heterogeneous appearance on MRI. In this study, we propose deep interactive networks (DINs) to address the above limitations. User interactions guide the model to recognize complicated tumors and quickly adapt to heterogeneous tumors. We introduce a simple but effective Exponential Distance Transform (ExpDT) that converts user interactions into guide maps regarded as the spatial and appearance prior. Comparing with popular Euclidean and geodesic distances, ExpDT is more robust to various image sizes, which reserves the distribution of interactive inputs. Furthermore, to enhance the tumor-related features, we design a deep interactive module to propagate the guides into deeper layers. We train and evaluate DINs on three MRI data sets from NF1 patients. The experiment results yield significant improvements of 44% and 14% in DSC comparing with automated and other interactive methods, respectively. We also experimentally demonstrate the efficiency of DINs in reducing user burden when comparing with conventional interactive methods. The source code of our method is available at \url{https://github.com/Jarvis73/DINs}.