 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchorSplat: Feed-Forward 3D Gaussian Splatting with 3D Geometric Priors
Apr 09, 2026Recent feed-forward Gaussian reconstruction models adopt a pixel-aligned formulation that maps each 2D pixel to a 3D Gaussian, entangling Gaussian representations tightly with the input images. In this paper, we propose AnchorSplat, a novel feed-forward 3DGS framework for scene-level reconstruction that represents the scene directly in 3D space. AnchorSplat introduces an anchor-aligned Gaussian representation guided by 3D geometric priors (e.g., sparse point clouds, voxels, or RGB-D point clouds), enabling a more geometry-aware renderable 3D Gaussians that is independent of image resolution and number of views. This design substantially reduces the number of required Gaussians, improving computational efficiency while enhancing reconstruction fidelity. Beyond the anchor-aligned design, we utilize a Gaussian Refiner to adjust the intermediate Gaussiansy via merely a few forward passes. Experiments on the ScanNet++ v2 NVS benchmark demonstrate the SOTA performance, outperforming previous methods with more view-consistent and substantially fewer Gaussian primitives.
HiFloat4 Format for Language Model Inference
Feb 13, 2026This paper introduces HiFloat4 (HiF4), a block floating-point data format tailored for deep learning. Each HiF4 unit packs 64 4-bit elements with 32 bits of shared scaling metadata, averaging 4.5 bits per value. The metadata specifies a three-level scaling hierarchy, capturing inter- and intra-group dynamic range while improving the utilization of the representational space. In addition, the large 64-element group size enables matrix multiplications to be executed in a highly fixed-point manner, significantly reducing hardware area and power consumption. To evaluate the proposed format, we conducted inference experiments on several language models, including LLaMA, Qwen, Mistral, DeepSeek-V3.1 and LongCat. Results show that HiF4 achieves higher average accuracy than the state-of-the-art NVFP4 format across multiple models and diverse downstream tasks.
GhostRNN: Reducing State Redundancy in RNN with Cheap Operations
Nov 20, 2024



Recurrent neural network (RNNs) that are capable of modeling long-distance dependencies are widely used in various speech tasks, eg., keyword spotting (KWS) and speech enhancement (SE). Due to the limitation of power and memory in low-resource devices, efficient RNN models are urgently required for real-world applications. In this paper, we propose an efficient RNN architecture, GhostRNN, which reduces hidden state redundancy with cheap operations. In particular, we observe that partial dimensions of hidden states are similar to the others in trained RNN models, suggesting that redundancy exists in specific RNNs. To reduce the redundancy and hence computational cost, we propose to first generate a few intrinsic states, and then apply cheap operations to produce ghost states based on the intrinsic states. Experiments on KWS and SE tasks demonstrate that the proposed GhostRNN significantly reduces the memory usage (~40%) and computation cost while keeping performance similar.
Vista3D: Unravel the 3D Darkside of a Single Image
Sep 18, 2024We embark on the age-old quest: unveiling the hidden dimensions of objects from mere glimpses of their visible parts. To address this, we present Vista3D, a framework that realizes swift and consistent 3D generation within a mere 5 minutes. At the heart of Vista3D lies a two-phase approach: the coarse phase and the fine phase. In the coarse phase, we rapidly generate initial geometry with Gaussian Splatting from a single image. In the fine phase, we extract a Signed Distance Function (SDF) directly from learned Gaussian Splatting, optimizing it with a differentiable isosurface representation. Furthermore, it elevates the quality of generation by using a disentangled representation with two independent implicit functions to capture both visible and obscured aspects of objects. Additionally, it harmonizes gradients from 2D diffusion prior with 3D-aware diffusion priors by angular diffusion prior composition. Through extensive evaluation, we demonstrate that Vista3D effectively sustains a balance between the consistency and diversity of the generated 3D objects. Demos and code will be available at https://github.com/florinshen/Vista3D.
Isomorphic Pruning for Vision Models
Jul 05, 2024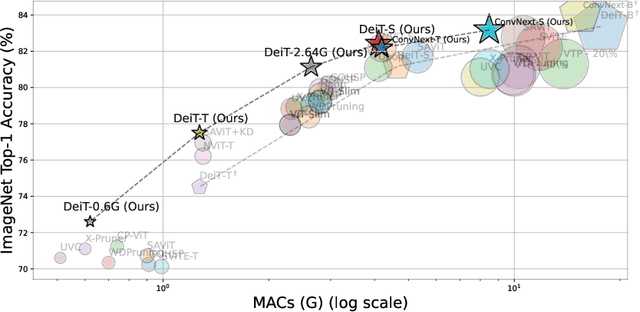
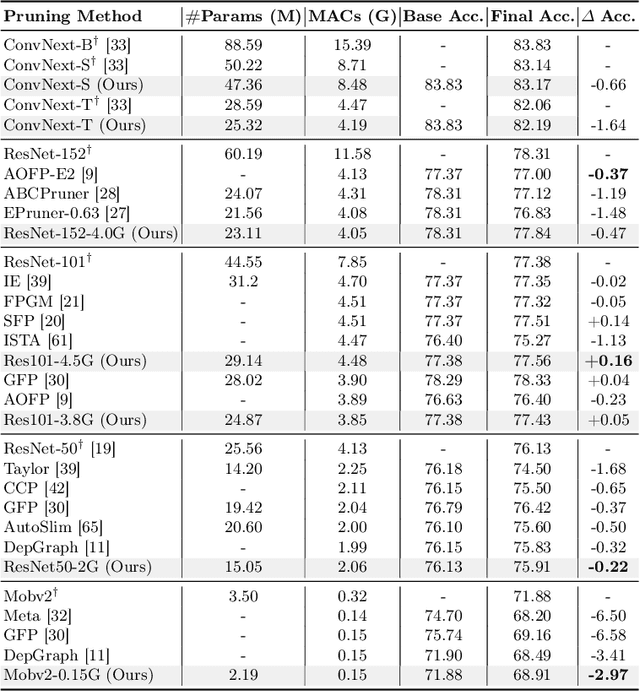

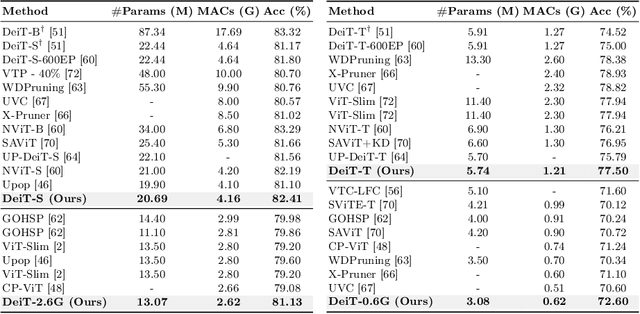
Structured pruning reduces the computational overhead of deep neural networks by removing redundant sub-structures. However, assessing the relative importance of different sub-structures remains a significant challenge, particularly in advanced vision models featuring novel mechanisms and architectures like self-attention, depth-wise convolutions, or residual connections. These heterogeneous substructures usually exhibit diverged parameter scales, weight distributions, and computational topology, introducing considerable difficulty to importance comparison. To overcome this, we present Isomorphic Pruning, a simple approach that demonstrates effectiveness across a range of network architectures such as Vision Transformers and CNNs, and delivers competitive performance across different model sizes. Isomorphic Pruning originates from an observation that, when evaluated under a pre-defined importance criterion, heterogeneous sub-structures demonstrate significant divergence in their importance distribution, as opposed to isomorphic structures that present similar importance patterns. This inspires us to perform isolated ranking and comparison on different types of sub-structures for more reliable pruning. Our empirical results on ImageNet-1K demonstrate that Isomorphic Pruning surpasses several pruning baselines dedicatedly designed for Transformers or CNNs. For instance, we improve the accuracy of DeiT-Tiny from 74.52% to 77.50% by pruning an off-the-shelf DeiT-Base model. And for ConvNext-Tiny, we enhanced performance from 82.06% to 82.18%, while reducing the number of parameters and memory usage. Code is available at \url{https://github.com/VainF/Isomorphic-Pruning}.
Learning-to-Cache: Accelerating Diffusion Transformer via Layer Caching
Jun 03, 2024



Diffusion Transformers have recently demonstrated unprecedented generative capabilities for various tasks. The encouraging results, however, come with the cost of slow inference, since each denoising step requires inference on a transformer model with a large scale of parameters. In this study, we make an interesting and somehow surprising observation: the computation of a large proportion of layers in the diffusion transformer, through introducing a caching mechanism, can be readily removed even without updating the model parameters. In the case of U-ViT-H/2, for example, we may remove up to 93.68% of the computation in the cache steps (46.84% for all steps), with less than 0.01 drop in FID. To achieve this, we introduce a novel scheme, named Learning-to-Cache (L2C), that learns to conduct caching in a dynamic manner for diffusion transformers. Specifically, by leveraging the identical structure of layers in transformers and the sequential nature of diffusion, we explore redundant computations between timesteps by treating each layer as the fundamental unit for caching. To address the challenge of the exponential search space in deep models for identifying layers to cache and remove, we propose a novel differentiable optimization objective. An input-invariant yet timestep-variant router is then optimized, which can finally produce a static computation graph. Experimental results show that L2C largely outperforms samplers such as DDIM and DPM-Solver, alongside prior cache-based methods at the same inference speed.
MotionMix: Weakly-Supervised Diffusion for Controllable Motion Generation
Jan 24, 2024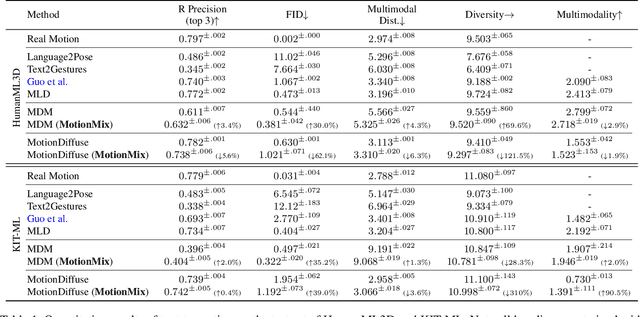
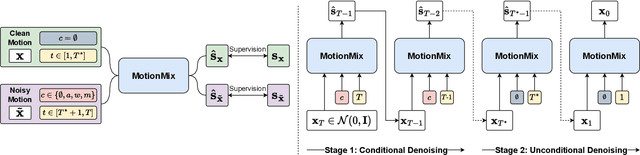
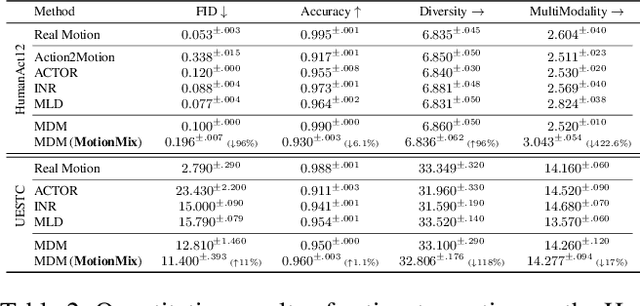
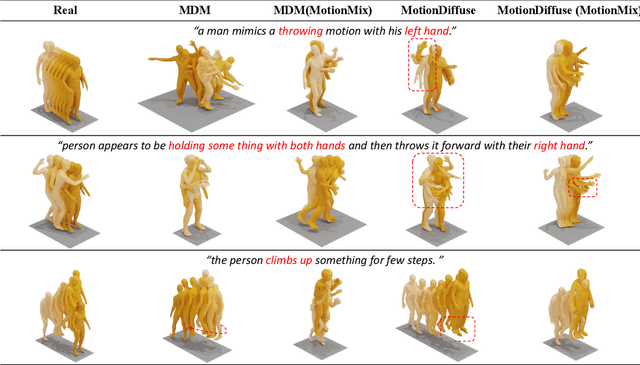
Controllable generation of 3D human motions becomes an important topic as the world embraces digital transformation. Existing works, though making promising progress with the advent of diffusion models, heavily rely on meticulously captured and annotated (e.g., text) high-quality motion corpus, a resource-intensive endeavor in the real world. This motivates our proposed MotionMix, a simple yet effective weakly-supervised diffusion model that leverages both noisy and unannotated motion sequences. Specifically, we separate the denoising objectives of a diffusion model into two stages: obtaining conditional rough motion approximations in the initial $T-T^*$ steps by learning the noisy annotated motions, followed by the unconditional refinement of these preliminary motions during the last $T^*$ steps using unannotated motions. Notably, though learning from two sources of imperfect data, our model does not compromise motion generation quality compared to fully supervised approaches that access gold data. Extensive experiments on several benchmarks demonstrate that our MotionMix, as a versatile framework, consistently achieves state-of-the-art performances on text-to-motion, action-to-motion, and music-to-dance tasks. Project page: https://nhathoang2002.github.io/MotionMix-page/
Semantic Segmentation in Multiple Adverse Weather Conditions with Domain Knowledge Retention
Jan 15, 2024Semantic segmentation's performance is often compromised when applied to unlabeled adverse weather conditions. Unsupervised domain adaptation is a potential approach to enhancing the model's adaptability and robustness to adverse weather. However, existing methods encounter difficulties when sequentially adapting the model to multiple unlabeled adverse weather conditions. They struggle to acquire new knowledge while also retaining previously learned knowledge.To address these problems, we propose a semantic segmentation method for multiple adverse weather conditions that incorporates adaptive knowledge acquisition, pseudolabel blending, and weather composition replay. Our adaptive knowledge acquisition enables the model to avoid learning from extreme images that could potentially cause the model to forget. In our approach of blending pseudo-labels, we not only utilize the current model but also integrate the previously learned model into the ongoing learning process. This collaboration between the current teacher and the previous model enhances the robustness of the pseudo-labels for the current target. Our weather composition replay mechanism allows the model to continuously refine its previously learned weather information while simultaneously learning from the new target domain. Our method consistently outperforms the stateof-the-art methods, and obtains the best performance with averaged mIoU (%) of 65.7 and the lowest forgetting (%) of 3.6 against 60.1 and 11.3, on the ACDC datasets for a four-target continual multi-target domain adaptation.
HEAP: Unsupervised Object Discovery and Localization with Contrastive Grouping
Jan 04, 2024Unsupervised object discovery and localization aims to detect or segment objects in an image without any supervision. Recent efforts have demonstrated a notable potential to identify salient foreground objects by utilizing self-supervised transformer features. However, their scopes only build upon patch-level features within an image, neglecting region/image-level and cross-image relationships at a broader scale. Moreover, these methods cannot differentiate various semantics from multiple instances. To address these problems, we introduce Hierarchical mErging framework via contrAstive grouPing (HEAP). Specifically, a novel lightweight head with cross-attention mechanism is designed to adaptively group intra-image patches into semantically coherent regions based on correlation among self-supervised features. Further, to ensure the distinguishability among various regions, we introduce a region-level contrastive clustering loss to pull closer similar regions across images. Also, an image-level contrastive loss is present to push foreground and background representations apart, with which foreground objects and background are accordingly discovered. HEAP facilitates efficient hierarchical image decomposition, which contributes to more accurate object discovery while also enabling differentiation among objects of various classes. Extensive experimental results on semantic segmentation retrieval, unsupervised object discovery, and saliency detection tasks demonstrate that HEAP achieves state-of-the-art performance.
DreamDrone
Dec 17, 2023



We introduce DreamDrone, an innovative method for generating unbounded flythrough scenes from textual prompts. Central to our method is a novel feature-correspondence-guidance diffusion process, which utilizes the strong correspondence of intermediate features in the diffusion model. Leveraging this guidance strategy, we further propose an advanced technique for editing the intermediate latent code, enabling the generation of subsequent novel views with geometric consistency. Extensive experiments reveal that DreamDrone significantly surpasses existing methods, delivering highly authentic scene generation with exceptional visual quality. This approach marks a significant step in zero-shot perpetual view generation from textual prompts, enabling the creation of diverse scenes, including natural landscapes like oases and caves, as well as complex urban settings such as Lego-style street views. Our code is publicly available.