 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 The Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 12, 2026This paper presents an overview of the NTIRE 2026 Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images. Building upon the success of the first edition, this challenge attracted a wide range of impressive solutions, all developed and evaluated on our real-world Raindrop Clarity dataset~\cite{jin2024raindrop}. For this edition, we adjust the dataset with 14,139 images for training, 407 images for validation, and 593 images for testing. The primary goal of this challenge is to establish a strong and practical benchmark for the removal of raindrops under various illumination and focus conditions. In total, 168 teams have registered for the competition, and 17 teams submitted valid final solutions and fact sheets for the testing phase. The submitted methods achieved strong performance on the Raindrop Clarity dataset, demonstrating the growing progress in this challenging task.
RIRF: Reasoning Image Restoration Framework
Apr 10, 2026Universal image restoration (UIR) aims to recover clean images from diverse and unknown degradations using a unified model. Existing UIR methods primarily focus on pixel reconstruction and often lack explicit diagnostic reasoning over degradation composition, severity, and scene semantics prior to restoration. We propose Reason and Restore (R\&R), a novel framework that integrates structured Chain-of-Thought (CoT) reasoning into the image restoration pipeline. R\&R introduces an explicit reasoner, implemented by fine-tuning Qwen3-VL, to diagnose degradation types, quantify degradation severity, infer key degradation-related factors, and describe relevant scene and object semantics. The resulting structured reasoning provides interpretable and fine-grained diagnostic priors for the restorer. To further improve restoration quality, the quantified degradation severity produced by the reasoner is leveraged as reinforcement learning (RL) signals to guide and strengthen the restorer. Unlike existing multimodal LLM-based agentic systems that decouple reasoning from low-level vision tasks, R\&R tightly couples semantic diagnostic reasoning with pixel-level restoration in a unified framework. Extensive experiments across diverse UIR benchmarks demonstrate that R\&R achieves state-of-the-art performance while offering unique interpretability into the restoration process.
Adverse Weather Optical Flow: Cumulative Homogeneous-Heterogeneous Adaptation
Sep 25, 2024

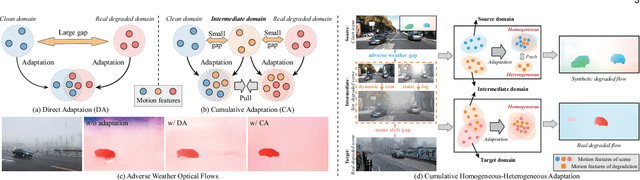

Optical flow has made great progress in clean scenes, while suffers degradation under adverse weather due to the violation of the brightness constancy and gradient continuity assumptions of optical flow. Typically, existing methods mainly adopt domain adaptation to transfer motion knowledge from clean to degraded domain through one-stage adaptation. However, this direct adaptation is ineffective, since there exists a large gap due to adverse weather and scene style between clean and real degraded domains. Moreover, even within the degraded domain itself, static weather (e.g., fog) and dynamic weather (e.g., rain) have different impacts on optical flow. To address above issues, we explore synthetic degraded domain as an intermediate bridge between clean and real degraded domains, and propose a cumulative homogeneous-heterogeneous adaptation framework for real adverse weather optical flow. Specifically, for clean-degraded transfer, our key insight is that static weather possesses the depth-association homogeneous feature which does not change the intrinsic motion of the scene, while dynamic weather additionally introduces the heterogeneous feature which results in a significant boundary discrepancy in warp errors between clean and degraded domains. For synthetic-real transfer, we figure out that cost volume correlation shares a similar statistical histogram between synthetic and real degraded domains, benefiting to holistically aligning the homogeneous correlation distribution for synthetic-real knowledge distillation. Under this unified framework, the proposed method can progressively and explicitly transfer knowledge from clean scenes to real adverse weather. In addition, we further collect a real adverse weather dataset with manually annotated optical flow labels and perform extensive experiments to verify the superiority of the proposed method.
NightHaze: Nighttime Image Dehazing via Self-Prior Learning
Mar 12, 2024



Masked autoencoder (MAE) shows that severe augmentation during training produces robust representations for high-level tasks. This paper brings the MAE-like framework to nighttime image enhancement, demonstrating that severe augmentation during training produces strong network priors that are resilient to real-world night haze degradations. We propose a novel nighttime image dehazing method with self-prior learning. Our main novelty lies in the design of severe augmentation, which allows our model to learn robust priors. Unlike MAE that uses masking, we leverage two key challenging factors of nighttime images as augmentation: light effects and noise. During training, we intentionally degrade clear images by blending them with light effects as well as by adding noise, and subsequently restore the clear images. This enables our model to learn clear background priors. By increasing the noise values to approach as high as the pixel intensity values of the glow and light effect blended images, our augmentation becomes severe, resulting in stronger priors. While our self-prior learning is considerably effective in suppressing glow and revealing details of background scenes, in some cases, there are still some undesired artifacts that remain, particularly in the forms of over-suppression. To address these artifacts, we propose a self-refinement module based on the semi-supervised teacher-student framework. Our NightHaze, especially our MAE-like self-prior learning, shows that models trained with severe augmentation effectively improve the visibility of input haze images, approaching the clarity of clear nighttime images. Extensive experiments demonstrate that our NightHaze achieves state-of-the-art performance, outperforming existing nighttime image dehazing methods by a substantial margin of 15.5% for MUSIQ and 23.5% for ClipIQA.
Exploring the Common Appearance-Boundary Adaptation for Nighttime Optical Flow
Jan 31, 2024



We investigate a challenging task of nighttime optical flow, which suffers from weakened texture and amplified noise. These degradations weaken discriminative visual features, thus causing invalid motion feature matching. Typically, existing methods employ domain adaptation to transfer knowledge from auxiliary domain to nighttime domain in either input visual space or output motion space. However, this direct adaptation is ineffective, since there exists a large domain gap due to the intrinsic heterogeneous nature of the feature representations between auxiliary and nighttime domains. To overcome this issue, we explore a common-latent space as the intermediate bridge to reinforce the feature alignment between auxiliary and nighttime domains. In this work, we exploit two auxiliary daytime and event domains, and propose a novel common appearance-boundary adaptation framework for nighttime optical flow. In appearance adaptation, we employ the intrinsic image decomposition to embed the auxiliary daytime image and the nighttime image into a reflectance-aligned common space. We discover that motion distributions of the two reflectance maps are very similar, benefiting us to consistently transfer motion appearance knowledge from daytime to nighttime domain. In boundary adaptation, we theoretically derive the motion correlation formula between nighttime image and accumulated events within a spatiotemporal gradient-aligned common space. We figure out that the correlation of the two spatiotemporal gradient maps shares significant discrepancy, benefitting us to contrastively transfer boundary knowledge from event to nighttime domain. Moreover, appearance adaptation and boundary adaptation are complementary to each other, since they could jointly transfer global motion and local boundary knowledge to the nighttime domain.
Semantic Segmentation in Multiple Adverse Weather Conditions with Domain Knowledge Retention
Jan 15, 2024Semantic segmentation's performance is often compromised when applied to unlabeled adverse weather conditions. Unsupervised domain adaptation is a potential approach to enhancing the model's adaptability and robustness to adverse weather. However, existing methods encounter difficulties when sequentially adapting the model to multiple unlabeled adverse weather conditions. They struggle to acquire new knowledge while also retaining previously learned knowledge.To address these problems, we propose a semantic segmentation method for multiple adverse weather conditions that incorporates adaptive knowledge acquisition, pseudolabel blending, and weather composition replay. Our adaptive knowledge acquisition enables the model to avoid learning from extreme images that could potentially cause the model to forget. In our approach of blending pseudo-labels, we not only utilize the current model but also integrate the previously learned model into the ongoing learning process. This collaboration between the current teacher and the previous model enhances the robustness of the pseudo-labels for the current target. Our weather composition replay mechanism allows the model to continuously refine its previously learned weather information while simultaneously learning from the new target domain. Our method consistently outperforms the stateof-the-art methods, and obtains the best performance with averaged mIoU (%) of 65.7 and the lowest forgetting (%) of 3.6 against 60.1 and 11.3, on the ACDC datasets for a four-target continual multi-target domain adaptation.
NightRain: Nighttime Video Deraining via Adaptive-Rain-Removal and Adaptive-Correction
Jan 10, 2024

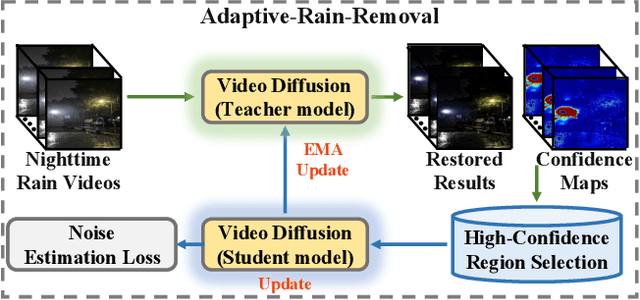
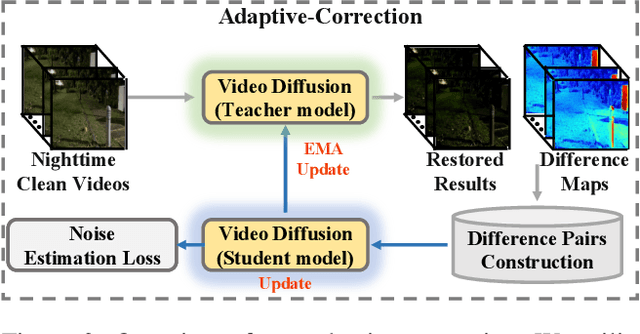
Existing deep-learning-based methods for nighttime video deraining rely on synthetic data due to the absence of real-world paired data. However, the intricacies of the real world, particularly with the presence of light effects and low-light regions affected by noise, create significant domain gaps, hampering synthetic-trained models in removing rain streaks properly and leading to over-saturation and color shifts. Motivated by this, we introduce NightRain, a novel nighttime video deraining method with adaptive-rain-removal and adaptive-correction. Our adaptive-rain-removal uses unlabeled rain videos to enable our model to derain real-world rain videos, particularly in regions affected by complex light effects. The idea is to allow our model to obtain rain-free regions based on the confidence scores. Once rain-free regions and the corresponding regions from our input are obtained, we can have region-based paired real data. These paired data are used to train our model using a teacher-student framework, allowing the model to iteratively learn from less challenging regions to more challenging regions. Our adaptive-correction aims to rectify errors in our model's predictions, such as over-saturation and color shifts. The idea is to learn from clear night input training videos based on the differences or distance between those input videos and their corresponding predictions. Our model learns from these differences, compelling our model to correct the errors. From extensive experiments, our method demonstrates state-of-the-art performance. It achieves a PSNR of 26.73dB, surpassing existing nighttime video deraining methods by a substantial margin of 13.7%.
Enhancing Visibility in Nighttime Haze Images Using Guided APSF and Gradient Adaptive Convolution
Aug 05, 2023Visibility in hazy nighttime scenes is frequently reduced by multiple factors, including low light, intense glow, light scattering, and the presence of multicolored light sources. Existing nighttime dehazing methods often struggle with handling glow or low-light conditions, resulting in either excessively dark visuals or unsuppressed glow outputs. In this paper, we enhance the visibility from a single nighttime haze image by suppressing glow and enhancing low-light regions. To handle glow effects, our framework learns from the rendered glow pairs. Specifically, a light source aware network is proposed to detect light sources of night images, followed by the APSF (Angular Point Spread Function)-guided glow rendering. Our framework is then trained on the rendered images, resulting in glow suppression. Moreover, we utilize gradient-adaptive convolution, to capture edges and textures in hazy scenes. By leveraging extracted edges and textures, we enhance the contrast of the scene without losing important structural details. To boost low-light intensity, our network learns an attention map, then adjusted by gamma correction. This attention has high values on low-light regions and low values on haze and glow regions. Extensive evaluation on real nighttime haze images, demonstrates the effectiveness of our method. Our experiments demonstrate that our method achieves a PSNR of 30.38dB, outperforming state-of-the-art methods by 13$\%$ on GTA5 nighttime haze dataset. Our data and code is available at: \url{https://github.com/jinyeying/nighttime_dehaze}.
* Accepted to ACMMM2023, https://github.com/jinyeying/nighttime_dehaze
Unsupervised Cumulative Domain Adaptation for Foggy Scene Optical Flow
Mar 20, 2023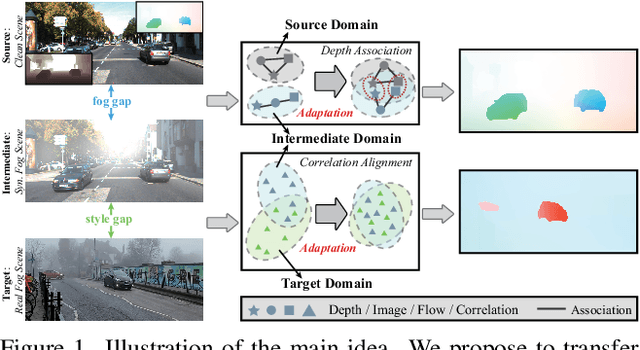
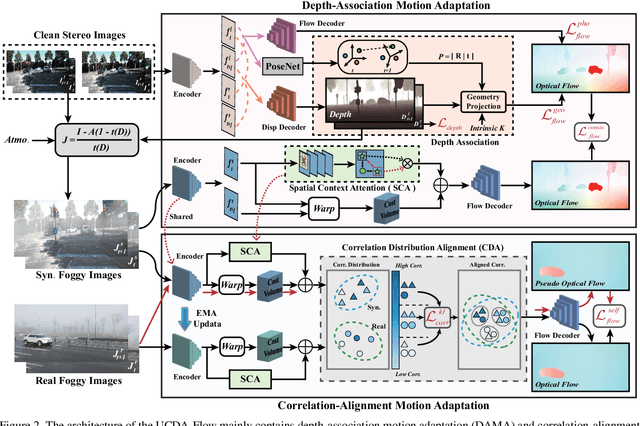
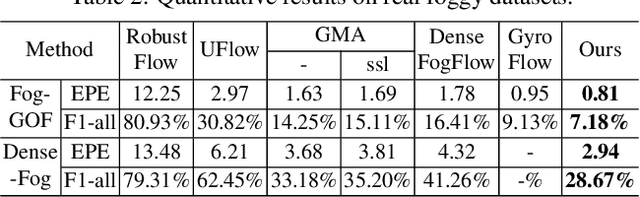
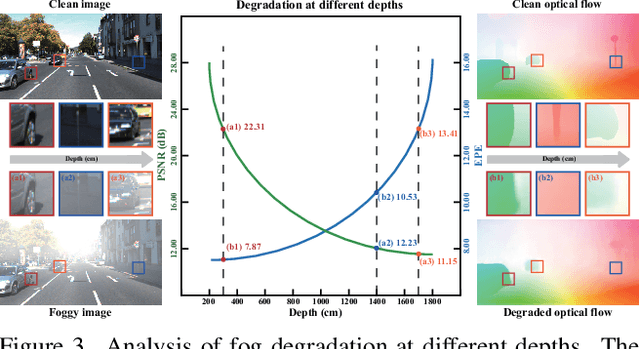
Optical flow has achieved great success under clean scenes, but suffers from restricted performance under foggy scenes. To bridge the clean-to-foggy domain gap, the existing methods typically adopt the domain adaptation to transfer the motion knowledge from clean to synthetic foggy domain. However, these methods unexpectedly neglect the synthetic-to-real domain gap, and thus are erroneous when applied to real-world scenes. To handle the practical optical flow under real foggy scenes, in this work, we propose a novel unsupervised cumulative domain adaptation optical flow (UCDA-Flow) framework: depth-association motion adaptation and correlation-alignment motion adaptation. Specifically, we discover that depth is a key ingredient to influence the optical flow: the deeper depth, the inferior optical flow, which motivates us to design a depth-association motion adaptation module to bridge the clean-to-foggy domain gap. Moreover, we figure out that the cost volume correlation shares similar distribution of the synthetic and real foggy images, which enlightens us to devise a correlation-alignment motion adaptation module to distill motion knowledge of the synthetic foggy domain to the real foggy domain. Note that synthetic fog is designed as the intermediate domain. Under this unified framework, the proposed cumulative adaptation progressively transfers knowledge from clean scenes to real foggy scenes. Extensive experiments have been performed to verify the superiority of the proposed method.
Structure Representation Network and Uncertainty Feedback Learning for Dense Non-Uniform Fog Removal
Oct 06, 2022
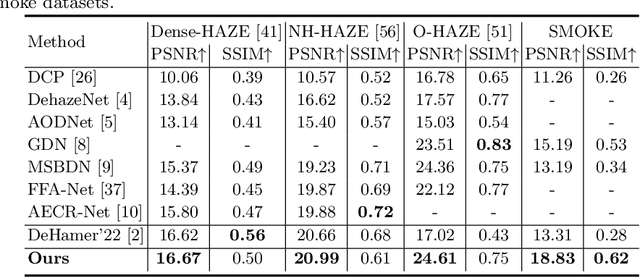
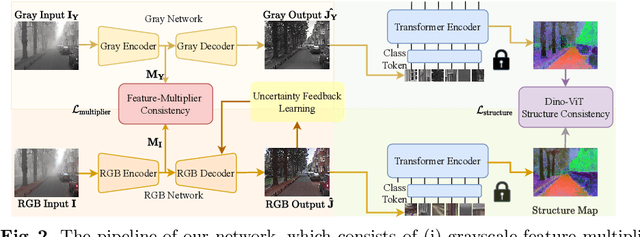

Few existing image defogging or dehazing methods consider dense and non-uniform particle distributions, which usually happen in smoke, dust and fog. Dealing with these dense and/or non-uniform distributions can be intractable, since fog's attenuation and airlight (or veiling effect) significantly weaken the background scene information in the input image. To address this problem, we introduce a structure-representation network with uncertainty feedback learning. Specifically, we extract the feature representations from a pre-trained Vision Transformer (DINO-ViT) module to recover the background information. To guide our network to focus on non-uniform fog areas, and then remove the fog accordingly, we introduce the uncertainty feedback learning, which produces the uncertainty maps, that have higher uncertainty in denser fog regions, and can be regarded as an attention map that represents fog's density and uneven distribution. Based on the uncertainty map, our feedback network refines our defogged output iteratively. Moreover, to handle the intractability of estimating the atmospheric light colors, we exploit the grayscale version of our input image, since it is less affected by varying light colors that are possibly present in the input image. The experimental results demonstrate the effectiveness of our method both quantitatively and qualitatively compared to the state-of-the-art methods in handling dense and non-uniform fog or smoke.