 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridge Frame and Event: Common Spatiotemporal Fusion for High-Dynamic Scene Optical Flow
Mar 11, 2025High-dynamic scene optical flow is a challenging task, which suffers spatial blur and temporal discontinuous motion due to large displacement in frame imaging, thus deteriorating the spatiotemporal feature of optical flow. Typically, existing methods mainly introduce event camera to directly fuse the spatiotemporal features between the two modalities. However, this direct fusion is ineffective, since there exists a large gap due to the heterogeneous data representation between frame and event modalities. To address this issue, we explore a common-latent space as an intermediate bridge to mitigate the modality gap. In this work, we propose a novel common spatiotemporal fusion between frame and event modalities for high-dynamic scene optical flow, including visual boundary localization and motion correlation fusion. Specifically, in visual boundary localization, we figure out that frame and event share the similar spatiotemporal gradients, whose similarity distribution is consistent with the extracted boundary distribution. This motivates us to design the common spatiotemporal gradient to constrain the reference boundary localization. In motion correlation fusion, we discover that the frame-based motion possesses spatially dense but temporally discontinuous correlation, while the event-based motion has spatially sparse but temporally continuous correlation. This inspires us to use the reference boundary to guide the complementary motion knowledge fusion between the two modalities. Moreover, common spatiotemporal fusion can not only relieve the cross-modal feature discrepancy, but also make the fusion process interpretable for dense and continuous optical flow. Extensive experiments have been performed to verify the superiority of the proposed method.
CoSEC: A Coaxial Stereo Event Camera Dataset for Autonomous Driving
Aug 16, 2024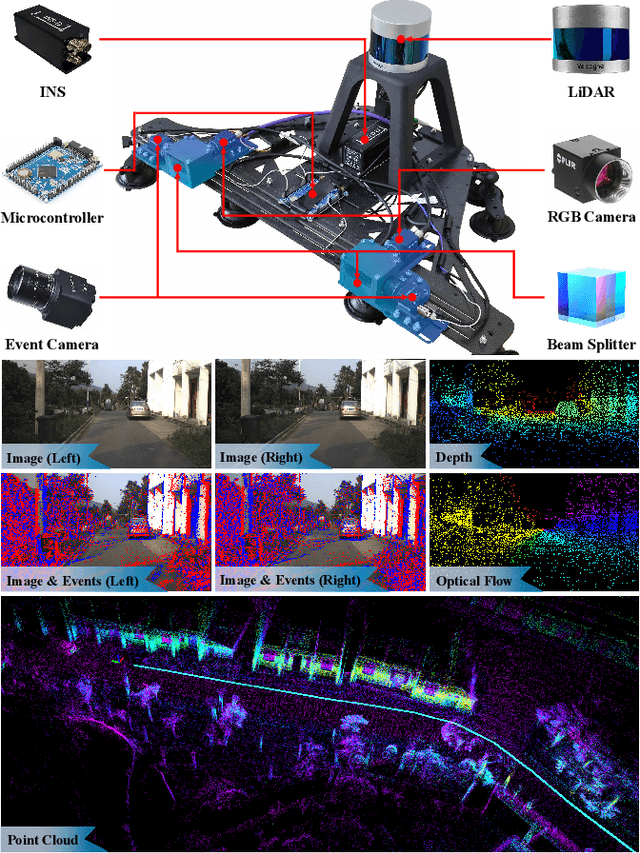
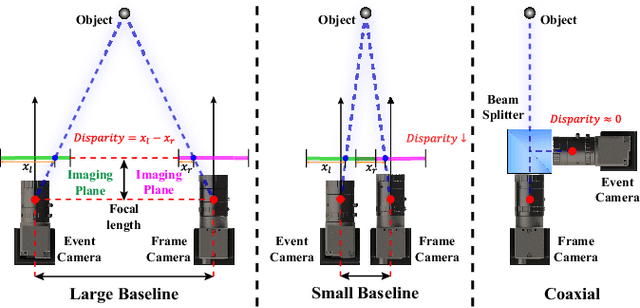
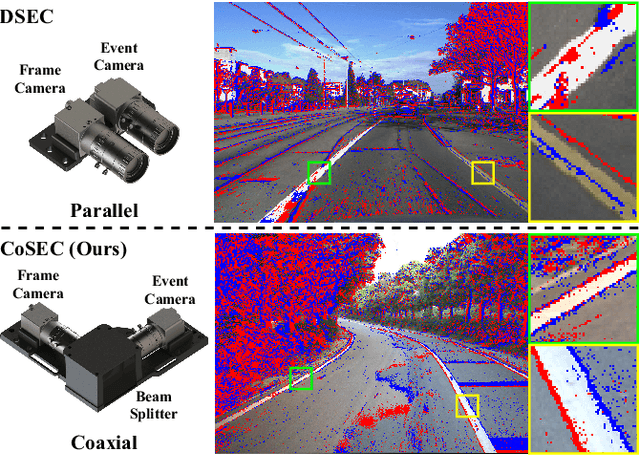
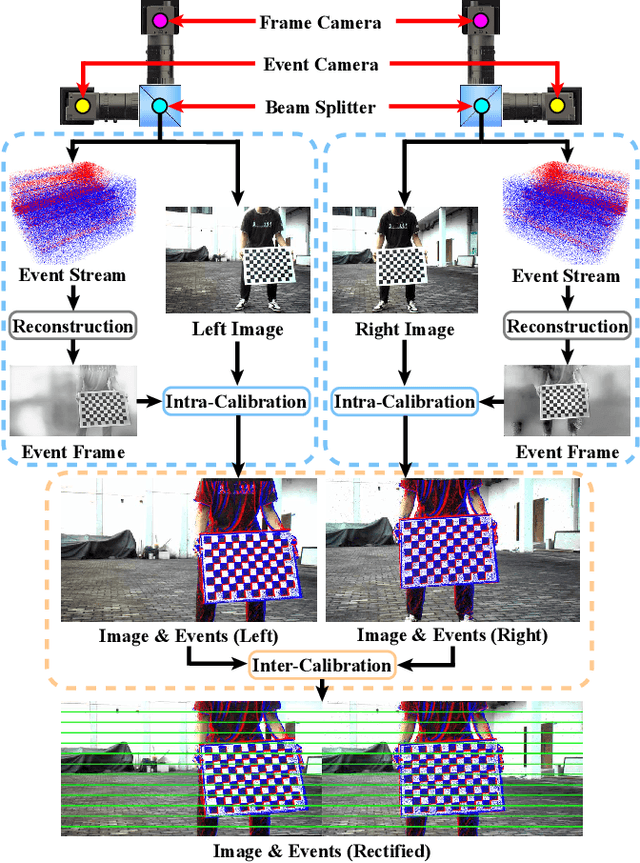
Conventional frame camera is the mainstream sensor of the autonomous driving scene perception, while it is limited in adverse conditions, such as low light. Event camera with high dynamic range has been applied in assisting frame camera for the multimodal fusion, which relies heavily on the pixel-level spatial alignment between various modalities. Typically, existing multimodal datasets mainly place event and frame cameras in parallel and directly align them spatially via warping operation. However, this parallel strategy is less effective for multimodal fusion, since the large disparity exacerbates spatial misalignment due to the large event-frame baseline. We argue that baseline minimization can reduce alignment error between event and frame cameras. In this work, we introduce hybrid coaxial event-frame devices to build the multimodal system, and propose a coaxial stereo event camera (CoSEC) dataset for autonomous driving. As for the multimodal system, we first utilize the microcontroller to achieve time synchronization, and then spatially calibrate different sensors, where we perform intra- and inter-calibration of stereo coaxial devices. As for the multimodal dataset, we filter LiDAR point clouds to generate depth and optical flow labels using reference depth, which is further improved by fusing aligned event and frame data in nighttime conditions. With the help of the coaxial device, the proposed dataset can promote the all-day pixel-level multimodal fusion. Moreover, we also conduct experiments to demonstrate that the proposed dataset can improve the performance and generalization of the multimodal fusion.
LED: A Large-scale Real-world Paired Dataset for Event Camera Denoising
May 30, 2024



Event camera has significant advantages in capturing dynamic scene information while being prone to noise interference, particularly in challenging conditions like low threshold and low illumination. However, most existing research focuses on gentle situations, hindering event camera applications in realistic complex scenarios. To tackle this limitation and advance the field, we construct a new paired real-world event denoising dataset (LED), including 3K sequences with 18K seconds of high-resolution (1200*680) event streams and showing three notable distinctions compared to others: diverse noise levels and scenes, larger-scale with high-resolution, and high-quality GT. Specifically, it contains stepped parameters and varying illumination with diverse scenarios. Moreover, based on the property of noise events inconsistency and signal events consistency, we propose a novel effective denoising framework(DED) using homogeneous dual events to generate the GT with better separating noise from the raw. Furthermore, we design a bio-inspired baseline leveraging Leaky-Integrate-and-Fire (LIF) neurons with dynamic thresholds to realize accurate denoising. The experimental results demonstrate that the remarkable performance of the proposed approach on different datasets.The dataset and code are at https://github.com/Yee-Sing/led.
Exploring the Common Appearance-Boundary Adaptation for Nighttime Optical Flow
Jan 31, 2024



We investigate a challenging task of nighttime optical flow, which suffers from weakened texture and amplified noise. These degradations weaken discriminative visual features, thus causing invalid motion feature matching. Typically, existing methods employ domain adaptation to transfer knowledge from auxiliary domain to nighttime domain in either input visual space or output motion space. However, this direct adaptation is ineffective, since there exists a large domain gap due to the intrinsic heterogeneous nature of the feature representations between auxiliary and nighttime domains. To overcome this issue, we explore a common-latent space as the intermediate bridge to reinforce the feature alignment between auxiliary and nighttime domains. In this work, we exploit two auxiliary daytime and event domains, and propose a novel common appearance-boundary adaptation framework for nighttime optical flow. In appearance adaptation, we employ the intrinsic image decomposition to embed the auxiliary daytime image and the nighttime image into a reflectance-aligned common space. We discover that motion distributions of the two reflectance maps are very similar, benefiting us to consistently transfer motion appearance knowledge from daytime to nighttime domain. In boundary adaptation, we theoretically derive the motion correlation formula between nighttime image and accumulated events within a spatiotemporal gradient-aligned common space. We figure out that the correlation of the two spatiotemporal gradient maps shares significant discrepancy, benefitting us to contrastively transfer boundary knowledge from event to nighttime domain. Moreover, appearance adaptation and boundary adaptation are complementary to each other, since they could jointly transfer global motion and local boundary knowledge to the nighttime domain.