 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDF-3DRME: A Data-Friendly Learning Framework for 3D Radio Map Estimation based on Super-Resolution Technique
Apr 01, 2026High-Resolution three-dimensional (3D) radio maps (RMs) provide rich information about the radio landscape that is essential to a myriad of wireless applications in the future wireless networks. Although deep learning (DL) methods have shown their effectiveness in RM construction, existing approaches require massive high-resolution 3D RM samples in the training dataset, the acquisition of which is labor-intensive and time-consuming in practice. In this paper, our goal is to devise a data-friendly high-resolution 3D RM construction solution via training over a hybrid dataset, wherein the RMs associated with a small fraction of environment maps (EMs) are of high-resolution, while those corresponding to the majority of EMs are of low-resolution. To this end, we propose a Data-Friendly 3D Radio Map Estimator (DF-3DRME), which comprises two processing stages. Specifically, in the first stage, we leverage the abundant low-resolution 3D RM samples to train a neural network, termed the LR-Net, for predicting the low-resolution 3D RM from the input EM, which provides a coarse characterization of the spatial radio propagation. In the second stage, we employ an advanced super-resolution network, termed the SR-Net, to upscale the predicted low-resolution 3D RM to its high-resolution counterpart. Unlike the LR-Net, the SR-Net can be effectively trained with only the limited high-resolution 3D RM samples available in the hybrid dataset. Experimental results demonstrate that the proposed framework achieves compelling reconstruction performance with only 4% of the EMs in the dataset having high-resolution 3D RM labels, which significantly reduces data acquisition overhead and facilitates practical deployment.
Intern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
Mar 26, 2026We introduce Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model. Scaling to this unprecedented size, the model delivers a comprehensive enhancement across both general and scientific domains. Beyond stronger reasoning and image-text understanding capabilities, its intelligence is augmented with advanced agent capabilities. Simultaneously, its scientific expertise has been vastly expanded to master over 100 specialized tasks across critical science fields, including chemistry, materials, life sciences, and earth sciences. Achieving this massive scale is made possible by the robust infrastructure support of XTuner and LMDeploy, which facilitates highly efficient Reinforcement Learning (RL) training at the 1-trillion parameter level while ensuring strict precision consistency between training and inference. By seamlessly integrating these advancements, Intern-S1-Pro further fortifies the fusion of general and specialized intelligence, working as a Specializable Generalist, demonstrating its position in the top tier of open-source models for general capabilities, while outperforming proprietary models in the depth of specialized scientific tasks.
Axiomatic On-Manifold Shapley via Optimal Generative Flows
Mar 05, 2026Shapley-based attribution is critical for post-hoc XAI but suffers from off-manifold artifacts due to heuristic baselines. While generative methods attempt to address this, they often introduce geometric inefficiency and discretization drift. We propose a formal theory of on-manifold Aumann-Shapley attributions driven by optimal generative flows. We prove a representation theorem establishing the gradient line integral as the unique functional satisfying efficiency and geometric axioms, notably reparameterization invariance. To resolve path ambiguity, we select the kinetic-energy-minimizing Wasserstein-2 geodesic transporting a prior to the data distribution. This yields a canonical attribution family that recovers classical Shapley for additive models and admits provable stability bounds against flow approximation errors. By reframing baseline selection as a variational problem, our method experimentally outperforms baselines, achieving strict manifold adherence via vanishing Flow Consistency Error and superior semantic alignment characterized by Structure-Aware Total Variation. Our code is on https://github.com/cenweizhang/OTFlowSHAP.
xai-cola: A Python library for sparsifying counterfactual explanations
Feb 25, 2026Counterfactual explanation (CE) is an important domain within post-hoc explainability. However, the explanations generated by most CE generators are often highly redundant. This work introduces an open-source Python library xai-cola, which provides an end-to-end pipeline for sparsifying CEs produced by arbitrary generators, reducing superfluous feature changes while preserving their validity. It offers a documented API that takes as input raw tabular data in pandas DataFrame form, a preprocessing object (for standardization and encoding), and a trained scikit-learn or PyTorch model. On this basis, users can either employ the built-in or externally imported CE generators. The library also implements several sparsification policies and includes visualization routines for analysing and comparing sparsified counterfactuals. xai-cola is released under the MIT license and can be installed from PyPI. Empirical experiments indicate that xai-cola produces sparser counterfactuals across several CE generators, reducing the number of modified features by up to 50% in our setting. The source code is available at https://github.com/understanding-ml/COLA.
Just Noticeable Difference Modeling for Deep Visual Features
Jan 29, 2026Deep visual features are increasingly used as the interface in vision systems, motivating the need to describe feature characteristics and control feature quality for machine perception. Just noticeable difference (JND) characterizes the maximum imperceptible distortion for images under human or machine vision. Extending it to deep visual features naturally meets the above demand by providing a task-aligned tolerance boundary in feature space, offering a practical reference for controlling feature quality under constrained resources. We propose FeatJND, a task-aligned JND formulation that predicts the maximum tolerable per-feature perturbation map while preserving downstream task performance. We propose a FeatJND estimator at standardized split points and validate it across image classification, detection, and instance segmentation. Under matched distortion strength, FeatJND-based distortions consistently preserve higher task performance than unstructured Gaussian perturbations, and attribution visualizations suggest FeatJND can suppress non-critical feature regions. As an application, we further apply FeatJND to token-wise dynamic quantization and show that FeatJND-guided step-size allocation yields clear gains over random step-size permutation and global uniform step size under the same noise budget. Our code will be released after publication.
Seeing through Light and Darkness: Sensor-Physics Grounded Deblurring HDR NeRF from Single-Exposure Images and Events
Jan 21, 2026Novel view synthesis from low dynamic range (LDR) blurry images, which are common in the wild, struggles to recover high dynamic range (HDR) and sharp 3D representations in extreme lighting conditions. Although existing methods employ event data to address this issue, they ignore the sensor-physics mismatches between the camera output and physical world radiance, resulting in suboptimal HDR and deblurring results. To cope with this problem, we propose a unified sensor-physics grounded NeRF framework for sharp HDR novel view synthesis from single-exposure blurry LDR images and corresponding events. We employ NeRF to directly represent the actual radiance of the 3D scene in the HDR domain and model raw HDR scene rays hitting the sensor pixels as in the physical world. A pixel-wise RGB mapping field is introduced to align the above rendered pixel values with the sensor-recorded LDR pixel values of the input images. A novel event mapping field is also designed to bridge the physical scene dynamics and actual event sensor output. The two mapping fields are jointly optimized with the NeRF network, leveraging the spatial and temporal dynamic information in events to enhance the sharp HDR 3D representation learning. Experiments on the collected and public datasets demonstrate that our method can achieve state-of-the-art deblurring HDR novel view synthesis results with single-exposure blurry LDR images and corresponding events.
Decoupling Amplitude and Phase Attention in Frequency Domain for RGB-Event based Visual Object Tracking
Jan 03, 2026Existing RGB-Event visual object tracking approaches primarily rely on conventional feature-level fusion, failing to fully exploit the unique advantages of event cameras. In particular, the high dynamic range and motion-sensitive nature of event cameras are often overlooked, while low-information regions are processed uniformly, leading to unnecessary computational overhead for the backbone network. To address these issues, we propose a novel tracking framework that performs early fusion in the frequency domain, enabling effective aggregation of high-frequency information from the event modality. Specifically, RGB and event modalities are transformed from the spatial domain to the frequency domain via the Fast Fourier Transform, with their amplitude and phase components decoupled. High-frequency event information is selectively fused into RGB modality through amplitude and phase attention, enhancing feature representation while substantially reducing backbone computation. In addition, a motion-guided spatial sparsification module leverages the motion-sensitive nature of event cameras to capture the relationship between target motion cues and spatial probability distribution, filtering out low-information regions and enhancing target-relevant features. Finally, a sparse set of target-relevant features is fed into the backbone network for learning, and the tracking head predicts the final target position. Extensive experiments on three widely used RGB-Event tracking benchmark datasets, including FE108, FELT, and COESOT, demonstrate the high performance and efficiency of our method. The source code of this paper will be released on https://github.com/Event-AHU/OpenEvTracking
JoyVoice: Long-Context Conditioning for Anthropomorphic Multi-Speaker Conversational Synthesis
Dec 22, 2025Large speech generation models are evolving from single-speaker, short sentence synthesis to multi-speaker, long conversation geneartion. Current long-form speech generation models are predominately constrained to dyadic, turn-based interactions. To address this, we introduce JoyVoice, a novel anthropomorphic foundation model designed for flexible, boundary-free synthesis of up to eight speakers. Unlike conventional cascaded systems, JoyVoice employs a unified E2E-Transformer-DiT architecture that utilizes autoregressive hidden representations directly for diffusion inputs, enabling holistic end-to-end optimization. We further propose a MM-Tokenizer operating at a low bitrate of 12.5 Hz, which integrates multitask semantic and MMSE losses to effectively model both semantic and acoustic information. Additionally, the model incorporates robust text front-end processing via large-scale data perturbation. Experiments show that JoyVoice achieves state-of-the-art results in multilingual generation (Chinese, English, Japanese, Korean) and zero-shot voice cloning. JoyVoice achieves top-tier results on both the Seed-TTS-Eval Benchmark and multi-speaker long-form conversational voice cloning tasks, demonstrating superior audio quality and generalization. It achieves significant improvements in prosodic continuity for long-form speech, rhythm richness in multi-speaker conversations, paralinguistic naturalness, besides superior intelligibility. We encourage readers to listen to the demo at https://jea-speech.github.io/JoyVoice
Re-coding for Uncertainties: Edge-awareness Semantic Concordance for Resilient Event-RGB Segmentation
Nov 11, 2025Semantic segmentation has achieved great success in ideal conditions. However, when facing extreme conditions (e.g., insufficient light, fierce camera motion), most existing methods suffer from significant information loss of RGB, severely damaging segmentation results. Several researches exploit the high-speed and high-dynamic event modality as a complement, but event and RGB are naturally heterogeneous, which leads to feature-level mismatch and inferior optimization of existing multi-modality methods. Different from these researches, we delve into the edge secret of both modalities for resilient fusion and propose a novel Edge-awareness Semantic Concordance framework to unify the multi-modality heterogeneous features with latent edge cues. In this framework, we first propose Edge-awareness Latent Re-coding, which obtains uncertainty indicators while realigning event-RGB features into unified semantic space guided by re-coded distribution, and transfers event-RGB distributions into re-coded features by utilizing a pre-established edge dictionary as clues. We then propose Re-coded Consolidation and Uncertainty Optimization, which utilize re-coded edge features and uncertainty indicators to solve the heterogeneous event-RGB fusion issues under extreme conditions. We establish two synthetic and one real-world event-RGB semantic segmentation datasets for extreme scenario comparisons. Experimental results show that our method outperforms the state-of-the-art by a 2.55% mIoU on our proposed DERS-XS, and possesses superior resilience under spatial occlusion. Our code and datasets are publicly available at https://github.com/iCVTEAM/ESC.
Revealing Latent Information: A Physics-inspired Self-supervised Pre-training Framework for Noisy and Sparse Events
Aug 07, 2025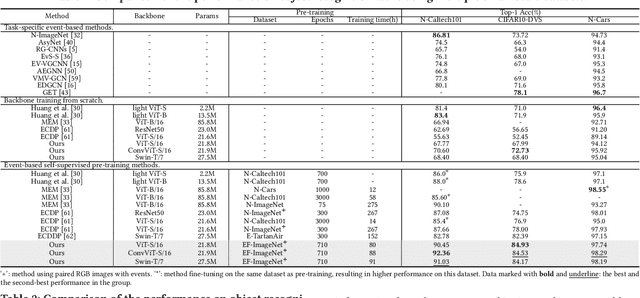

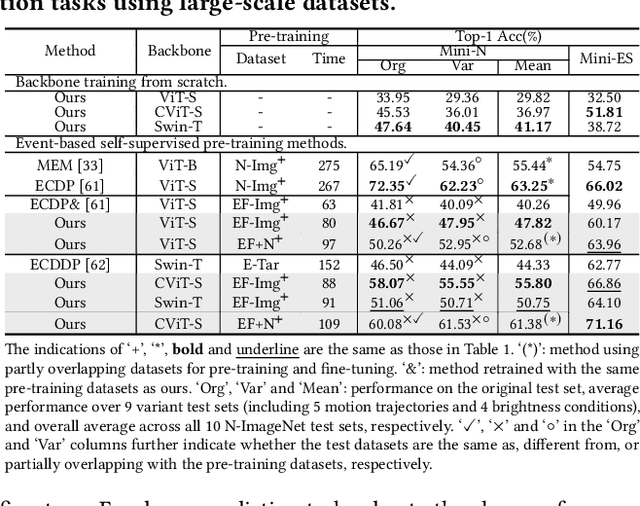
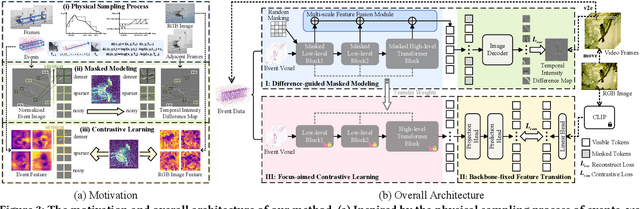
Event camera, a novel neuromorphic vision sensor, records data with high temporal resolution and wide dynamic range, offering new possibilities for accurate visual representation in challenging scenarios. However, event data is inherently sparse and noisy, mainly reflecting brightness changes, which complicates effective feature extraction. To address this, we propose a self-supervised pre-training framework to fully reveal latent information in event data, including edge information and texture cues. Our framework consists of three stages: Difference-guided Masked Modeling, inspired by the event physical sampling process, reconstructs temporal intensity difference maps to extract enhanced information from raw event data. Backbone-fixed Feature Transition contrasts event and image features without updating the backbone to preserve representations learned from masked modeling and stabilizing their effect on contrastive learning. Focus-aimed Contrastive Learning updates the entire model to improve semantic discrimination by focusing on high-value regions. Extensive experiments show our framework is robust and consistently outperforms state-of-the-art methods on various downstream tasks, including object recognition, semantic segmentation, and optical flow estimation. The code and dataset are available at https://github.com/BIT-Vision/EventPretrain.