 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIQuest-Coder-V1 Technical Report
Mar 17, 2026In this report, we introduce the IQuest-Coder-V1 series-(7B/14B/40B/40B-Loop), a new family of code large language models (LLMs). Moving beyond static code representations, we propose the code-flow multi-stage training paradigm, which captures the dynamic evolution of software logic through different phases of the pipeline. Our models are developed through the evolutionary pipeline, starting with the initial pre-training consisting of code facts, repository, and completion data. Following that, we implement a specialized mid-training stage that integrates reasoning and agentic trajectories in 32k-context and repository-scale in 128k-context to forge deep logical foundations. The models are then finalized with post-training of specialized coding capabilities, which is bifurcated into two specialized paths: the thinking path (utilizing reasoning-driven RL) and the instruct path (optimized for general assistance). IQuest-Coder-V1 achieves state-of-the-art performance among competitive models across critical dimensions of code intelligence: agentic software engineering, competitive programming, and complex tool use. To address deployment constraints, the IQuest-Coder-V1-Loop variant introduces a recurrent mechanism designed to optimize the trade-off between model capacity and deployment footprint, offering an architecturally enhanced path for efficacy-efficiency trade-off. We believe the release of the IQuest-Coder-V1 series, including the complete white-box chain of checkpoints from pre-training bases to the final thinking and instruction models, will advance research in autonomous code intelligence and real-world agentic systems.
InCoder-32B: Code Foundation Model for Industrial Scenarios
Mar 17, 2026Recent code large language models have achieved remarkable progress on general programming tasks. Nevertheless, their performance degrades significantly in industrial scenarios that require reasoning about hardware semantics, specialized language constructs, and strict resource constraints. To address these challenges, we introduce InCoder-32B (Industrial-Coder-32B), the first 32B-parameter code foundation model unifying code intelligence across chip design, GPU kernel optimization, embedded systems, compiler optimization, and 3D modeling. By adopting an efficient architecture, we train InCoder-32B from scratch with general code pre-training, curated industrial code annealing, mid-training that progressively extends context from 8K to 128K tokens with synthetic industrial reasoning data, and post-training with execution-grounded verification. We conduct extensive evaluation on 14 mainstream general code benchmarks and 9 industrial benchmarks spanning 4 specialized domains. Results show InCoder-32B achieves highly competitive performance on general tasks while establishing strong open-source baselines across industrial domains.
CodeSimpleQA: Scaling Factuality in Code Large Language Models
Dec 22, 2025Large language models (LLMs) have made significant strides in code generation, achieving impressive capabilities in synthesizing code snippets from natural language instructions. However, a critical challenge remains in ensuring LLMs generate factually accurate responses about programming concepts, technical implementations, etc. Most previous code-related benchmarks focus on code execution correctness, overlooking the factual accuracy of programming knowledge. To address this gap, we present CodeSimpleQA, a comprehensive bilingual benchmark designed to evaluate the factual accuracy of code LLMs in answering code-related questions, which contains carefully curated question-answer pairs in both English and Chinese, covering diverse programming languages and major computer science domains. Further, we create CodeSimpleQA-Instruct, a large-scale instruction corpus with 66M samples, and develop a post-training framework combining supervised fine-tuning and reinforcement learning. Our comprehensive evaluation of diverse LLMs reveals that even frontier LLMs struggle with code factuality. Our proposed framework demonstrates substantial improvements over the base model, underscoring the critical importance of factuality-aware alignment in developing reliable code LLMs.
AOMGen: Photoreal, Physics-Consistent Demonstration Generation for Articulated Object Manipulation
Dec 20, 2025
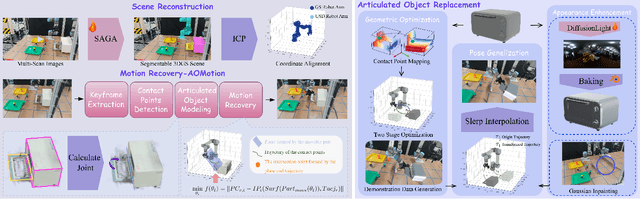


Recent advances in Vision-Language-Action (VLA) and world-model methods have improved generalization in tasks such as robotic manipulation and object interaction. However, Successful execution of such tasks depends on large, costly collections of real demonstrations, especially for fine-grained manipulation of articulated objects. To address this, we present AOMGen, a scalable data generation framework for articulated manipulation which is instantiated from a single real scan, demonstration and a library of readily available digital assets, yielding photoreal training data with verified physical states. The framework synthesizes synchronized multi-view RGB temporally aligned with action commands and state annotations for joints and contacts, and systematically varies camera viewpoints, object styles, and object poses to expand a single execution into a diverse corpus. Experimental results demonstrate that fine-tuning VLA policies on AOMGen data increases the success rate from 0% to 88.7%, and the policies are tested on unseen objects and layouts.
ArtGen: Conditional Generative Modeling of Articulated Objects in Arbitrary Part-Level States
Dec 13, 2025Generating articulated assets is crucial for robotics, digital twins, and embodied intelligence. Existing generative models often rely on single-view inputs representing closed states, resulting in ambiguous or unrealistic kinematic structures due to the entanglement between geometric shape and joint dynamics. To address these challenges, we introduce ArtGen, a conditional diffusion-based framework capable of generating articulated 3D objects with accurate geometry and coherent kinematics from single-view images or text descriptions at arbitrary part-level states. Specifically, ArtGen employs cross-state Monte Carlo sampling to explicitly enforce global kinematic consistency, reducing structural-motion entanglement. Additionally, we integrate a Chain-of-Thought reasoning module to infer robust structural priors, such as part semantics, joint types, and connectivity, guiding a sparse-expert Diffusion Transformer to specialize in diverse kinematic interactions. Furthermore, a compositional 3D-VAE latent prior enhanced with local-global attention effectively captures fine-grained geometry and global part-level relationships. Extensive experiments on the PartNet-Mobility benchmark demonstrate that ArtGen significantly outperforms state-of-the-art methods.
Learning to Align, Aligning to Learn: A Unified Approach for Self-Optimized Alignment
Aug 11, 2025



Alignment methodologies have emerged as a critical pathway for enhancing language model alignment capabilities. While SFT (supervised fine-tuning) accelerates convergence through direct token-level loss intervention, its efficacy is constrained by offline policy trajectory. In contrast, RL(reinforcement learning) facilitates exploratory policy optimization, but suffers from low sample efficiency and stringent dependency on high-quality base models. To address these dual challenges, we propose GRAO (Group Relative Alignment Optimization), a unified framework that synergizes the respective strengths of SFT and RL through three key innovations: 1) A multi-sample generation strategy enabling comparative quality assessment via reward feedback; 2) A novel Group Direct Alignment Loss formulation leveraging intra-group relative advantage weighting; 3) Reference-aware parameter updates guided by pairwise preference dynamics. Our theoretical analysis establishes GRAO's convergence guarantees and sample efficiency advantages over conventional approaches. Comprehensive evaluations across complex human alignment tasks demonstrate GRAO's superior performance, achieving 57.70\%,17.65\% 7.95\% and 5.18\% relative improvements over SFT, DPO, PPO and GRPO baselines respectively. This work provides both a theoretically grounded alignment framework and empirical evidence for efficient capability evolution in language models.
Self-Supervised Multi-Part Articulated Objects Modeling via Deformable Gaussian Splatting and Progressive Primitive Segmentation
Jun 11, 2025Articulated objects are ubiquitous in everyday life, and accurate 3D representations of their geometry and motion are critical for numerous applications. However, in the absence of human annotation, existing approaches still struggle to build a unified representation for objects that contain multiple movable parts. We introduce DeGSS, a unified framework that encodes articulated objects as deformable 3D Gaussian fields, embedding geometry, appearance, and motion in one compact representation. Each interaction state is modeled as a smooth deformation of a shared field, and the resulting deformation trajectories guide a progressive coarse-to-fine part segmentation that identifies distinct rigid components, all in an unsupervised manner. The refined field provides a spatially continuous, fully decoupled description of every part, supporting part-level reconstruction and precise modeling of their kinematic relationships. To evaluate generalization and realism, we enlarge the synthetic PartNet-Mobility benchmark and release RS-Art, a real-to-sim dataset that pairs RGB captures with accurately reverse-engineered 3D models. Extensive experiments demonstrate that our method outperforms existing methods in both accuracy and stability.
Adversarial Attack for RGB-Event based Visual Object Tracking
Apr 19, 2025Visual object tracking is a crucial research topic in the fields of computer vision and multi-modal fusion. Among various approaches, robust visual tracking that combines RGB frames with Event streams has attracted increasing attention from researchers. While striving for high accuracy and efficiency in tracking, it is also important to explore how to effectively conduct adversarial attacks and defenses on RGB-Event stream tracking algorithms, yet research in this area remains relatively scarce. To bridge this gap, in this paper, we propose a cross-modal adversarial attack algorithm for RGB-Event visual tracking. Because of the diverse representations of Event streams, and given that Event voxels and frames are more commonly used, this paper will focus on these two representations for an in-depth study. Specifically, for the RGB-Event voxel, we first optimize the perturbation by adversarial loss to generate RGB frame adversarial examples. For discrete Event voxel representations, we propose a two-step attack strategy, more in detail, we first inject Event voxels into the target region as initialized adversarial examples, then, conduct a gradient-guided optimization by perturbing the spatial location of the Event voxels. For the RGB-Event frame based tracking, we optimize the cross-modal universal perturbation by integrating the gradient information from multimodal data. We evaluate the proposed approach against attacks on three widely used RGB-Event Tracking datasets, i.e., COESOT, FE108, and VisEvent. Extensive experiments show that our method significantly reduces the performance of the tracker across numerous datasets in both unimodal and multimodal scenarios. The source code will be released on https://github.com/Event-AHU/Adversarial_Attack_Defense
Activating Associative Disease-Aware Vision Token Memory for LLM-Based X-ray Report Generation
Jan 07, 2025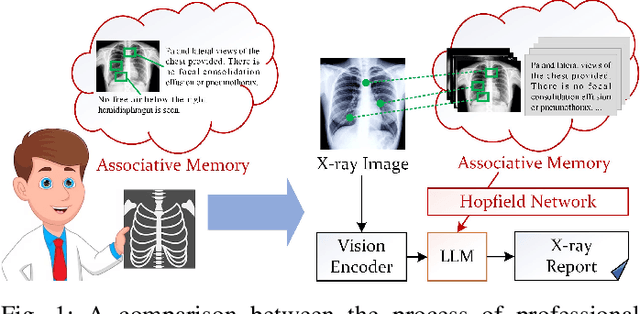



X-ray image based medical report generation achieves significant progress in recent years with the help of the large language model, however, these models have not fully exploited the effective information in visual image regions, resulting in reports that are linguistically sound but insufficient in describing key diseases. In this paper, we propose a novel associative memory-enhanced X-ray report generation model that effectively mimics the process of professional doctors writing medical reports. It considers both the mining of global and local visual information and associates historical report information to better complete the writing of the current report. Specifically, given an X-ray image, we first utilize a classification model along with its activation maps to accomplish the mining of visual regions highly associated with diseases and the learning of disease query tokens. Then, we employ a visual Hopfield network to establish memory associations for disease-related tokens, and a report Hopfield network to retrieve report memory information. This process facilitates the generation of high-quality reports based on a large language model and achieves state-of-the-art performance on multiple benchmark datasets, including the IU X-ray, MIMIC-CXR, and Chexpert Plus. The source code of this work is released on \url{https://github.com/Event-AHU/Medical_Image_Analysis}.
Unisolver: PDE-Conditional Transformers Are Universal PDE Solvers
May 27, 2024



Deep models have recently emerged as a promising tool to solve partial differential equations (PDEs), known as neural PDE solvers. While neural solvers trained from either simulation data or physics-informed loss can solve the PDEs reasonably well, they are mainly restricted to a specific set of PDEs, e.g. a certain equation or a finite set of coefficients. This bottleneck limits the generalizability of neural solvers, which is widely recognized as its major advantage over numerical solvers. In this paper, we present the Universal PDE solver (Unisolver) capable of solving a wide scope of PDEs by leveraging a Transformer pre-trained on diverse data and conditioned on diverse PDEs. Instead of simply scaling up data and parameters, Unisolver stems from the theoretical analysis of the PDE-solving process. Our key finding is that a PDE solution is fundamentally under the control of a series of PDE components, e.g. equation symbols, coefficients, and initial and boundary conditions. Inspired by the mathematical structure of PDEs, we define a complete set of PDE components and correspondingly embed them as domain-wise (e.g. equation symbols) and point-wise (e.g. boundaries) conditions for Transformer PDE solvers. Integrating physical insights with recent Transformer advances, Unisolver achieves consistent state-of-the-art results on three challenging large-scale benchmarks, showing impressive gains and endowing favorable generalizability and scalability.