 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Markov Multi-Round Conversational Image Generation with History-Conditioned MLLMs
Jan 28, 2026Conversational image generation requires a model to follow user instructions across multiple rounds of interaction, grounded in interleaved text and images that accumulate as chat history. While recent multimodal large language models (MLLMs) can generate and edit images, most existing multi-turn benchmarks and training recipes are effectively Markov: the next output depends primarily on the most recent image, enabling shortcut solutions that ignore long-range history. In this work we formalize and target the more challenging non-Markov setting, where a user may refer back to earlier states, undo changes, or reference entities introduced several rounds ago. We present (i) non-Markov multi-round data construction strategies, including rollback-style editing that forces retrieval of earlier visual states and name-based multi-round personalization that binds names to appearances across rounds; (ii) a history-conditioned training and inference framework with token-level caching to prevent multi-round identity drift; and (iii) enabling improvements for high-fidelity image reconstruction and editable personalization, including a reconstruction-based DiT detokenizer and a multi-stage fine-tuning curriculum. We demonstrate that explicitly training for non-Markov interactions yields substantial improvements in multi-round consistency and instruction compliance, while maintaining strong single-round editing and personalization.
Exploring MLLM-Diffusion Information Transfer with MetaCanvas
Dec 12, 2025Multimodal learning has rapidly advanced visual understanding, largely via multimodal large language models (MLLMs) that use powerful LLMs as cognitive cores. In visual generation, however, these powerful core models are typically reduced to global text encoders for diffusion models, leaving most of their reasoning and planning ability unused. This creates a gap: current multimodal LLMs can parse complex layouts, attributes, and knowledge-intensive scenes, yet struggle to generate images or videos with equally precise and structured control. We propose MetaCanvas, a lightweight framework that lets MLLMs reason and plan directly in spatial and spatiotemporal latent spaces and interface tightly with diffusion generators. We empirically implement MetaCanvas on three different diffusion backbones and evaluate it across six tasks, including text-to-image generation, text/image-to-video generation, image/video editing, and in-context video generation, each requiring precise layouts, robust attribute binding, and reasoning-intensive control. MetaCanvas consistently outperforms global-conditioning baselines, suggesting that treating MLLMs as latent-space planners is a promising direction for narrowing the gap between multimodal understanding and generation.
SM$^3$: Self-Supervised Multi-task Modeling with Multi-view 2D Images for Articulated Objects
Jan 17, 2024



Reconstructing real-world objects and estimating their movable joint structures are pivotal technologies within the field of robotics. Previous research has predominantly focused on supervised approaches, relying on extensively annotated datasets to model articulated objects within limited categories. However, this approach falls short of effectively addressing the diversity present in the real world. To tackle this issue, we propose a self-supervised interaction perception method, referred to as SM$^3$, which leverages multi-view RGB images captured before and after interaction to model articulated objects, identify the movable parts, and infer the parameters of their rotating joints. By constructing 3D geometries and textures from the captured 2D images, SM$^3$ achieves integrated optimization of movable part and joint parameters during the reconstruction process, obviating the need for annotations. Furthermore, we introduce the MMArt dataset, an extension of PartNet-Mobility, encompassing multi-view and multi-modal data of articulated objects spanning diverse categories. Evaluations demonstrate that SM$^3$ surpasses existing benchmarks across various categories and objects, while its adaptability in real-world scenarios has been thoroughly validated.
MaskINT: Video Editing via Interpolative Non-autoregressive Masked Transformers
Dec 19, 2023



Recent advances in generative AI have significantly enhanced image and video editing, particularly in the context of text prompt control. State-of-the-art approaches predominantly rely on diffusion models to accomplish these tasks. However, the computational demands of diffusion-based methods are substantial, often necessitating large-scale paired datasets for training, and therefore challenging the deployment in practical applications. This study addresses this challenge by breaking down the text-based video editing process into two separate stages. In the first stage, we leverage an existing text-to-image diffusion model to simultaneously edit a few keyframes without additional fine-tuning. In the second stage, we introduce an efficient model called MaskINT, which is built on non-autoregressive masked generative transformers and specializes in frame interpolation between the keyframes, benefiting from structural guidance provided by intermediate frames. Our comprehensive set of experiments illustrates the efficacy and efficiency of MaskINT when compared to other diffusion-based methodologies. This research offers a practical solution for text-based video editing and showcases the potential of non-autoregressive masked generative transformers in this domain.
DTF-Net: Category-Level Pose Estimation and Shape Reconstruction via Deformable Template Field
Aug 04, 2023
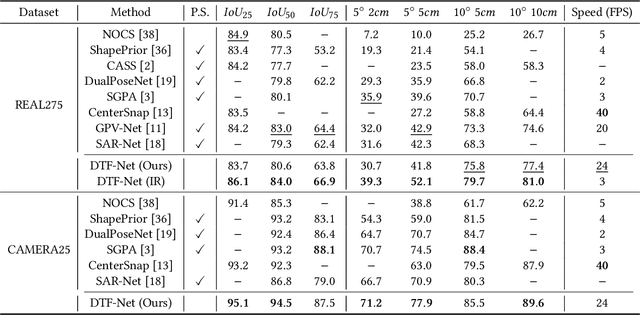


Estimating 6D poses and reconstructing 3D shapes of objects in open-world scenes from RGB-depth image pairs is challenging. Many existing methods rely on learning geometric features that correspond to specific templates while disregarding shape variations and pose differences among objects in the same category. As a result, these methods underperform when handling unseen object instances in complex environments. In contrast, other approaches aim to achieve category-level estimation and reconstruction by leveraging normalized geometric structure priors, but the static prior-based reconstruction struggles with substantial intra-class variations. To solve these problems, we propose the DTF-Net, a novel framework for pose estimation and shape reconstruction based on implicit neural fields of object categories. In DTF-Net, we design a deformable template field to represent the general category-wise shape latent features and intra-category geometric deformation features. The field establishes continuous shape correspondences, deforming the category template into arbitrary observed instances to accomplish shape reconstruction. We introduce a pose regression module that shares the deformation features and template codes from the fields to estimate the accurate 6D pose of each object in the scene. We integrate a multi-modal representation extraction module to extract object features and semantic masks, enabling end-to-end inference. Moreover, during training, we implement a shape-invariant training strategy and a viewpoint sampling method to further enhance the model's capability to extract object pose features. Extensive experiments on the REAL275 and CAMERA25 datasets demonstrate the superiority of DTF-Net in both synthetic and real scenes. Furthermore, we show that DTF-Net effectively supports grasping tasks with a real robot arm.
System-status-aware Adaptive Network for Online Streaming Video Understanding
Apr 09, 2023Recent years have witnessed great progress in deep neural networks for real-time applications. However, most existing works do not explicitly consider the general case where the device's state and the available resources fluctuate over time, and none of them investigate or address the impact of varying computational resources for online video understanding tasks. This paper proposes a System-status-aware Adaptive Network (SAN) that considers the device's real-time state to provide high-quality predictions with low delay. Usage of our agent's policy improves efficiency and robustness to fluctuations of the system status. On two widely used video understanding tasks, SAN obtains state-of-the-art performance while constantly keeping processing delays low. Moreover, training such an agent on various types of hardware configurations is not easy as the labeled training data might not be available, or can be computationally prohibitive. To address this challenging problem, we propose a Meta Self-supervised Adaptation (MSA) method that adapts the agent's policy to new hardware configurations at test-time, allowing for easy deployment of the model onto other unseen hardware platforms.
GradMDM: Adversarial Attack on Dynamic Networks
Apr 01, 2023



Dynamic neural networks can greatly reduce computation redundancy without compromising accuracy by adapting their structures based on the input. In this paper, we explore the robustness of dynamic neural networks against energy-oriented attacks targeted at reducing their efficiency. Specifically, we attack dynamic models with our novel algorithm GradMDM. GradMDM is a technique that adjusts the direction and the magnitude of the gradients to effectively find a small perturbation for each input, that will activate more computational units of dynamic models during inference. We evaluate GradMDM on multiple datasets and dynamic models, where it outperforms previous energy-oriented attack techniques, significantly increasing computation complexity while reducing the perceptibility of the perturbations.
Progressive Channel-Shrinking Network
Apr 01, 2023



Currently, salience-based channel pruning makes continuous breakthroughs in network compression. In the realization, the salience mechanism is used as a metric of channel salience to guide pruning. Therefore, salience-based channel pruning can dynamically adjust the channel width at run-time, which provides a flexible pruning scheme. However, there are two problems emerging: a gating function is often needed to truncate the specific salience entries to zero, which destabilizes the forward propagation; dynamic architecture brings more cost for indexing in inference which bottlenecks the inference speed. In this paper, we propose a Progressive Channel-Shrinking (PCS) method to compress the selected salience entries at run-time instead of roughly approximating them to zero. We also propose a Running Shrinking Policy to provide a testing-static pruning scheme that can reduce the memory access cost for filter indexing. We evaluate our method on ImageNet and CIFAR10 datasets over two prevalent networks: ResNet and VGG, and demonstrate that our PCS outperforms all baselines and achieves state-of-the-art in terms of compression-performance tradeoff. Moreover, we observe a significant and practical acceleration of inference.
Lightweight Estimation of Hand Mesh and Biomechanically Feasible Kinematic Parameters
Mar 26, 2023



3D hand pose estimation is a long-standing challenge in both robotics and computer vision communities due to its implicit depth ambiguity and often strong self-occlusion. Recently, in addition to the hand skeleton, jointly estimating hand pose and shape has gained more attraction. State-of-the-art methods adopt a model-free approach, estimating the vertices of the hand mesh directly and providing superior accuracy compared to traditional model-based methods directly regressing the parameters of the parametric hand mesh. However, with the large number of mesh vertices to estimate, these methods are often slow in inference. We propose an efficient variation of the previously proposed image-to-lixel approach to efficiently estimate hand meshes from the images. Leveraging recent developments in efficient neural architectures, we significantly reduce the computation complexity without sacrificing the estimation accuracy. Furthermore, we introduce an inverted kinematic(IK) network to translate the estimated hand mesh to a biomechanically feasible set of joint rotation parameters, which is necessary for applications that leverage pose estimation for controlling robotic hands. Finally, an optional post-processing module is proposed to refine the rotation and shape parameters to compensate for the error introduced by the IK net. Our Lite I2L Mesh Net achieves state-of-the-art joint and mesh estimation accuracy with less than $13\%$ of the total computational complexity of the original I2L hand mesh estimator. Adding the IK net and post-optimization modules can improve the accuracy slightly at a small computation cost, but more importantly, provide the kinematic parameters required for robotic applications.
DiffPose: Toward More Reliable 3D Pose Estimation
Nov 30, 2022



Monocular 3D human pose estimation is quite challenging due to the inherent ambiguity and occlusion, which often lead to high uncertainty and indeterminacy. On the other hand, diffusion models have recently emerged as an effective tool for generating high-quality images from noise. Inspired by their capability, we explore a novel pose estimation framework (DiffPose) that formulates 3D pose estimation as a reverse diffusion process. We incorporate novel designs into our DiffPose that facilitate the diffusion process for 3D pose estimation: a pose-specific initialization of pose uncertainty distributions, a Gaussian Mixture Model-based forward diffusion process, and a context-conditioned reverse diffusion process. Our proposed DiffPose significantly outperforms existing methods on the widely used pose estimation benchmarks Human3.6M and MPI-INF-3DHP.