 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing the Intrinsic Ethical Vulnerability of Aligned Large Language Models
Apr 07, 2025Large language models (LLMs) are foundational explorations to artificial general intelligence, yet their alignment with human values via instruction tuning and preference learning achieves only superficial compliance. Here, we demonstrate that harmful knowledge embedded during pretraining persists as indelible "dark patterns" in LLMs' parametric memory, evading alignment safeguards and resurfacing under adversarial inducement at distributional shifts. In this study, we first theoretically analyze the intrinsic ethical vulnerability of aligned LLMs by proving that current alignment methods yield only local "safety regions" in the knowledge manifold. In contrast, pretrained knowledge remains globally connected to harmful concepts via high-likelihood adversarial trajectories. Building on this theoretical insight, we empirically validate our findings by employing semantic coherence inducement under distributional shifts--a method that systematically bypasses alignment constraints through optimized adversarial prompts. This combined theoretical and empirical approach achieves a 100% attack success rate across 19 out of 23 state-of-the-art aligned LLMs, including DeepSeek-R1 and LLaMA-3, revealing their universal vulnerabilities.
PADetBench: Towards Benchmarking Physical Attacks against Object Detection
Aug 17, 2024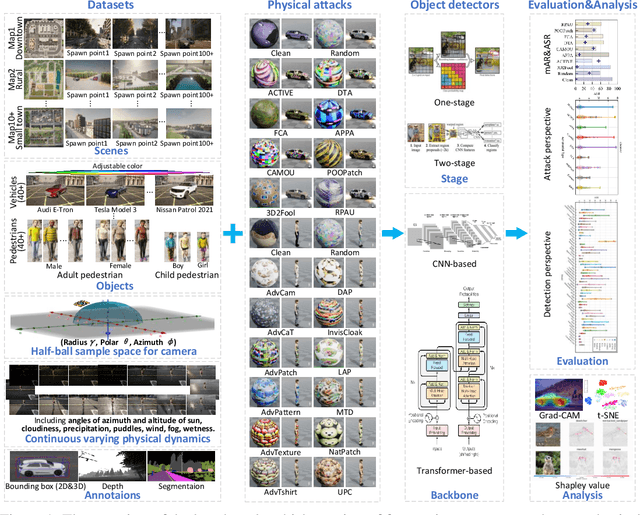



Physical attacks against object detection have gained increasing attention due to their significant practical implications. However, conducting physical experiments is extremely time-consuming and labor-intensive. Moreover, physical dynamics and cross-domain transformation are challenging to strictly regulate in the real world, leading to unaligned evaluation and comparison, severely hindering the development of physically robust models. To accommodate these challenges, we explore utilizing realistic simulation to thoroughly and rigorously benchmark physical attacks with fairness under controlled physical dynamics and cross-domain transformation. This resolves the problem of capturing identical adversarial images that cannot be achieved in the real world. Our benchmark includes 20 physical attack methods, 48 object detectors, comprehensive physical dynamics, and evaluation metrics. We also provide end-to-end pipelines for dataset generation, detection, evaluation, and further analysis. In addition, we perform 8064 groups of evaluation based on our benchmark, which includes both overall evaluation and further detailed ablation studies for controlled physical dynamics. Through these experiments, we provide in-depth analyses of physical attack performance and physical adversarial robustness, draw valuable observations, and discuss potential directions for future research. Codebase: https://github.com/JiaweiLian/Benchmarking_Physical_Attack
Progressive Channel-Shrinking Network
Apr 01, 2023



Currently, salience-based channel pruning makes continuous breakthroughs in network compression. In the realization, the salience mechanism is used as a metric of channel salience to guide pruning. Therefore, salience-based channel pruning can dynamically adjust the channel width at run-time, which provides a flexible pruning scheme. However, there are two problems emerging: a gating function is often needed to truncate the specific salience entries to zero, which destabilizes the forward propagation; dynamic architecture brings more cost for indexing in inference which bottlenecks the inference speed. In this paper, we propose a Progressive Channel-Shrinking (PCS) method to compress the selected salience entries at run-time instead of roughly approximating them to zero. We also propose a Running Shrinking Policy to provide a testing-static pruning scheme that can reduce the memory access cost for filter indexing. We evaluate our method on ImageNet and CIFAR10 datasets over two prevalent networks: ResNet and VGG, and demonstrate that our PCS outperforms all baselines and achieves state-of-the-art in terms of compression-performance tradeoff. Moreover, we observe a significant and practical acceleration of inference.
GradMDM: Adversarial Attack on Dynamic Networks
Apr 01, 2023



Dynamic neural networks can greatly reduce computation redundancy without compromising accuracy by adapting their structures based on the input. In this paper, we explore the robustness of dynamic neural networks against energy-oriented attacks targeted at reducing their efficiency. Specifically, we attack dynamic models with our novel algorithm GradMDM. GradMDM is a technique that adjusts the direction and the magnitude of the gradients to effectively find a small perturbation for each input, that will activate more computational units of dynamic models during inference. We evaluate GradMDM on multiple datasets and dynamic models, where it outperforms previous energy-oriented attack techniques, significantly increasing computation complexity while reducing the perceptibility of the perturbations.
Privacy-preserving household load forecasting based on non-intrusive load monitoring: A federated deep learning approach
Jun 30, 2022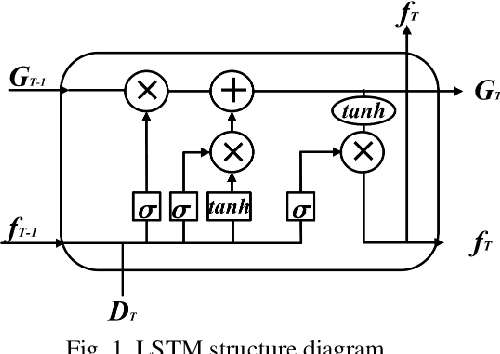
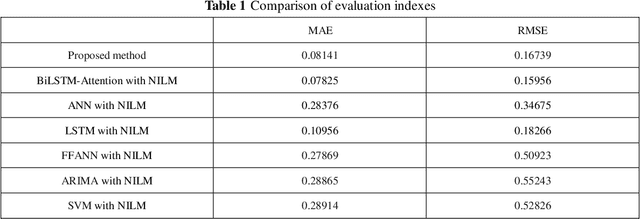


Load forecasting is very essential in the analysis and grid planning of power systems. For this reason, we first propose a household load forecasting method based on federated deep learning and non-intrusive load monitoring (NILM). For all we know, this is the first research on federated learning (FL) in household load forecasting based on NILM. In this method, the integrated power is decomposed into individual device power by non-intrusive load monitoring, and the power of individual appliances is predicted separately using a federated deep learning model. Finally, the predicted power values of individual appliances are aggregated to form the total power prediction. Specifically, by separately predicting the electrical equipment to obtain the predicted power, it avoids the error caused by the strong time dependence in the power signal of a single device. And in the federated deep learning prediction model, the household owners with the power data share the parameters of the local model instead of the local power data, guaranteeing the privacy of the household user data. The case results demonstrate that the proposed approach provides a better prediction effect than the traditional methodology that directly predicts the aggregated signal as a whole. In addition, experiments in various federated learning environments are designed and implemented to validate the validity of this methodology.