 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing the Intrinsic Ethical Vulnerability of Aligned Large Language Models
Apr 07, 2025Large language models (LLMs) are foundational explorations to artificial general intelligence, yet their alignment with human values via instruction tuning and preference learning achieves only superficial compliance. Here, we demonstrate that harmful knowledge embedded during pretraining persists as indelible "dark patterns" in LLMs' parametric memory, evading alignment safeguards and resurfacing under adversarial inducement at distributional shifts. In this study, we first theoretically analyze the intrinsic ethical vulnerability of aligned LLMs by proving that current alignment methods yield only local "safety regions" in the knowledge manifold. In contrast, pretrained knowledge remains globally connected to harmful concepts via high-likelihood adversarial trajectories. Building on this theoretical insight, we empirically validate our findings by employing semantic coherence inducement under distributional shifts--a method that systematically bypasses alignment constraints through optimized adversarial prompts. This combined theoretical and empirical approach achieves a 100% attack success rate across 19 out of 23 state-of-the-art aligned LLMs, including DeepSeek-R1 and LLaMA-3, revealing their universal vulnerabilities.
MotionBench: Benchmarking and Improving Fine-grained Video Motion Understanding for Vision Language Models
Jan 06, 2025
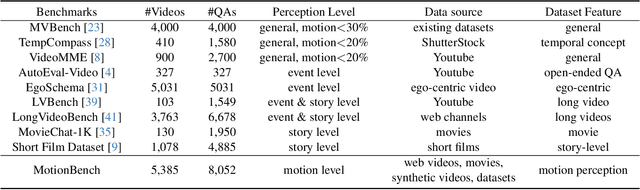


In recent years, vision language models (VLMs) have made significant advancements in video understanding. However, a crucial capability - fine-grained motion comprehension - remains under-explored in current benchmarks. To address this gap, we propose MotionBench, a comprehensive evaluation benchmark designed to assess the fine-grained motion comprehension of video understanding models. MotionBench evaluates models' motion-level perception through six primary categories of motion-oriented question types and includes data collected from diverse sources, ensuring a broad representation of real-world video content. Experimental results reveal that existing VLMs perform poorly in understanding fine-grained motions. To enhance VLM's ability to perceive fine-grained motion within a limited sequence length of LLM, we conduct extensive experiments reviewing VLM architectures optimized for video feature compression and propose a novel and efficient Through-Encoder (TE) Fusion method. Experiments show that higher frame rate inputs and TE Fusion yield improvements in motion understanding, yet there is still substantial room for enhancement. Our benchmark aims to guide and motivate the development of more capable video understanding models, emphasizing the importance of fine-grained motion comprehension. Project page: https://motion-bench.github.io .
PADetBench: Towards Benchmarking Physical Attacks against Object Detection
Aug 17, 2024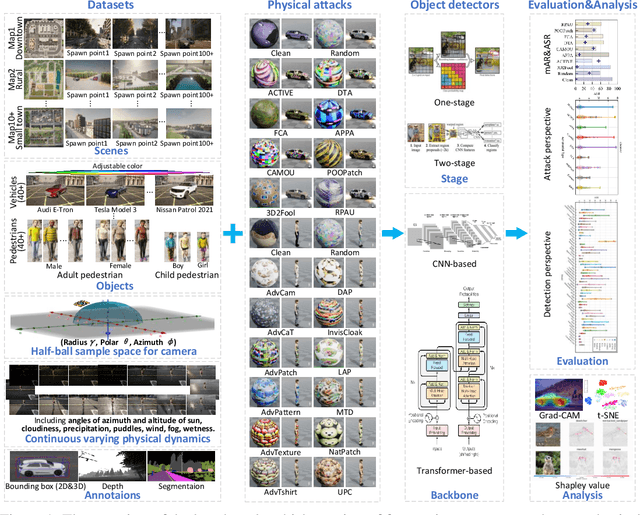



Physical attacks against object detection have gained increasing attention due to their significant practical implications. However, conducting physical experiments is extremely time-consuming and labor-intensive. Moreover, physical dynamics and cross-domain transformation are challenging to strictly regulate in the real world, leading to unaligned evaluation and comparison, severely hindering the development of physically robust models. To accommodate these challenges, we explore utilizing realistic simulation to thoroughly and rigorously benchmark physical attacks with fairness under controlled physical dynamics and cross-domain transformation. This resolves the problem of capturing identical adversarial images that cannot be achieved in the real world. Our benchmark includes 20 physical attack methods, 48 object detectors, comprehensive physical dynamics, and evaluation metrics. We also provide end-to-end pipelines for dataset generation, detection, evaluation, and further analysis. In addition, we perform 8064 groups of evaluation based on our benchmark, which includes both overall evaluation and further detailed ablation studies for controlled physical dynamics. Through these experiments, we provide in-depth analyses of physical attack performance and physical adversarial robustness, draw valuable observations, and discuss potential directions for future research. Codebase: https://github.com/JiaweiLian/Benchmarking_Physical_Attack