 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
TDRM: Smooth Reward Models with Temporal Difference for LLM RL and Inference
Sep 18, 2025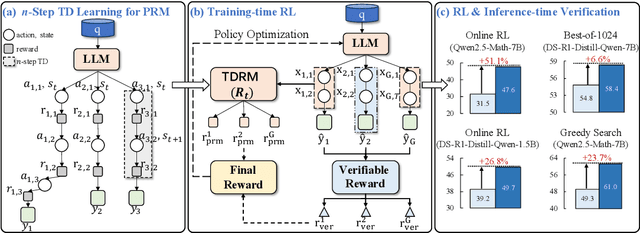
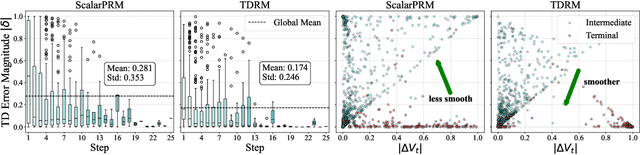

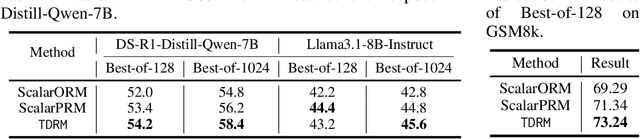
Reward models are central to both reinforcement learning (RL) with language models and inference-time verification. However, existing reward models often lack temporal consistency, leading to ineffective policy updates and unstable RL training. We introduce TDRM, a method for learning smoother and more reliable reward models by minimizing temporal differences during training. This temporal-difference (TD) regularization produces smooth rewards and improves alignment with long-term objectives. Incorporating TDRM into the actor-critic style online RL loop yields consistent empirical gains. It is worth noting that TDRM is a supplement to verifiable reward methods, and both can be used in series. Experiments show that TD-trained process reward models (PRMs) improve performance across Best-of-N (up to 6.6%) and tree-search (up to 23.7%) settings. When combined with Reinforcement Learning with Verifiable Rewards (RLVR), TD-trained PRMs lead to more data-efficient RL -- achieving comparable performance with just 2.5k data to what baseline methods require 50.1k data to attain -- and yield higher-quality language model policies on 8 model variants (5 series), e.g., Qwen2.5-(0.5B, 1,5B), GLM4-9B-0414, GLM-Z1-9B-0414, Qwen2.5-Math-(1.5B, 7B), and DeepSeek-R1-Distill-Qwen-(1.5B, 7B). We release all code at https://github.com/THUDM/TDRM.
ReST-RL: Achieving Accurate Code Reasoning of LLMs with Optimized Self-Training and Decoding
Aug 27, 2025With respect to improving the reasoning accuracy of LLMs, the representative reinforcement learning (RL) method GRPO faces failure due to insignificant reward variance, while verification methods based on process reward models (PRMs) suffer from difficulties with training data acquisition and verification effectiveness. To tackle these problems, this paper introduces ReST-RL, a unified LLM RL paradigm that significantly improves LLM's code reasoning ability by combining an improved GRPO algorithm with a meticulously designed test time decoding method assisted by a value model (VM). As the first stage of policy reinforcement, ReST-GRPO adopts an optimized ReST algorithm to filter and assemble high-value training data, increasing the reward variance of GRPO sampling, thus improving the effectiveness and efficiency of training. After the basic reasoning ability of LLM policy has been improved, we further propose a test time decoding optimization method called VM-MCTS. Through Monte-Carlo Tree Search (MCTS), we collect accurate value targets with no annotation required, on which VM training is based. When decoding, the VM is deployed by an adapted MCTS algorithm to provide precise process signals as well as verification scores, assisting the LLM policy to achieve high reasoning accuracy. We validate the effectiveness of the proposed RL paradigm through extensive experiments on coding problems. Upon comparison, our approach significantly outperforms other reinforcement training baselines (e.g., naive GRPO and ReST-DPO), as well as decoding and verification baselines (e.g., PRM-BoN and ORM-MCTS) on well-known coding benchmarks of various levels (e.g., APPS, BigCodeBench, and HumanEval), indicating its power to strengthen the reasoning ability of LLM policies. Codes for our project can be found at https://github.com/THUDM/ReST-RL.
ComputerRL: Scaling End-to-End Online Reinforcement Learning for Computer Use Agents
Aug 19, 2025We introduce ComputerRL, a framework for autonomous desktop intelligence that enables agents to operate complex digital workspaces skillfully. ComputerRL features the API-GUI paradigm, which unifies programmatic API calls and direct GUI interaction to address the inherent mismatch between machine agents and human-centric desktop environments. Scaling end-to-end RL training is crucial for improvement and generalization across diverse desktop tasks, yet remains challenging due to environmental inefficiency and instability in extended training. To support scalable and robust training, we develop a distributed RL infrastructure capable of orchestrating thousands of parallel virtual desktop environments to accelerate large-scale online RL. Furthermore, we propose Entropulse, a training strategy that alternates reinforcement learning with supervised fine-tuning, effectively mitigating entropy collapse during extended training runs. We employ ComputerRL on open models GLM-4-9B-0414 and Qwen2.5-14B, and evaluate them on the OSWorld benchmark. The AutoGLM-OS-9B based on GLM-4-9B-0414 achieves a new state-of-the-art accuracy of 48.1%, demonstrating significant improvements for general agents in desktop automation. The algorithm and framework are adopted in building AutoGLM (Liu et al., 2024a)
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Jul 02, 2025



We present GLM-4.1V-Thinking, a vision-language model (VLM) designed to advance general-purpose multimodal understanding and reasoning. In this report, we share our key findings in the development of the reasoning-centric training framework. We first develop a capable vision foundation model with significant potential through large-scale pre-training, which arguably sets the upper bound for the final performance. We then propose Reinforcement Learning with Curriculum Sampling (RLCS) to unlock the full potential of the model, leading to comprehensive capability enhancement across a diverse range of tasks, including STEM problem solving, video understanding, content recognition, coding, grounding, GUI-based agents, and long document understanding. We open-source GLM-4.1V-9B-Thinking, which achieves state-of-the-art performance among models of comparable size. In a comprehensive evaluation across 28 public benchmarks, our model outperforms Qwen2.5-VL-7B on nearly all tasks and achieves comparable or even superior performance on 18 benchmarks relative to the significantly larger Qwen2.5-VL-72B. Notably, GLM-4.1V-9B-Thinking also demonstrates competitive or superior performance compared to closed-source models such as GPT-4o on challenging tasks including long document understanding and STEM reasoning, further underscoring its strong capabilities. Code, models and more information are released at https://github.com/THUDM/GLM-4.1V-Thinking.
TreeRL: LLM Reinforcement Learning with On-Policy Tree Search
Jun 13, 2025Reinforcement learning (RL) with tree search has demonstrated superior performance in traditional reasoning tasks. Compared to conventional independent chain sampling strategies with outcome supervision, tree search enables better exploration of the reasoning space and provides dense, on-policy process rewards during RL training but remains under-explored in On-Policy LLM RL. We propose TreeRL, a reinforcement learning framework that directly incorporates on-policy tree search for RL training. Our approach includes intermediate supervision and eliminates the need for a separate reward model training. Existing approaches typically train a separate process reward model, which can suffer from distribution mismatch and reward hacking. We also introduce a cost-effective tree search approach that achieves higher search efficiency under the same generation token budget by strategically branching from high-uncertainty intermediate steps rather than using random branching. Experiments on challenging math and code reasoning benchmarks demonstrate that TreeRL achieves superior performance compared to traditional ChainRL, highlighting the potential of tree search for LLM. TreeRL is open-sourced at https://github.com/THUDM/TreeRL.
SWE-Dev: Building Software Engineering Agents with Training and Inference Scaling
Jun 09, 2025
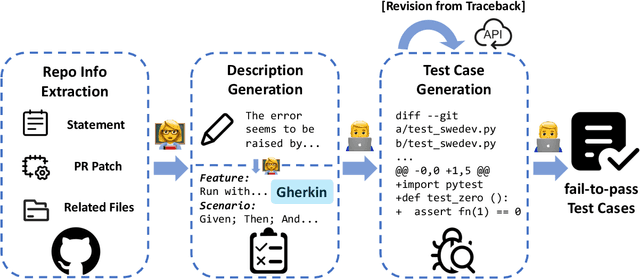

Large language models (LLMs) have advanced rapidly from conversational problem solving to addressing real-world tasks involving tool use, such as software engineering (SWE). Recent LLM-powered toolkits, such as OpenAI Codex and Cursor, have offered end-to-end automation of the software development process. However, building effective SWE agents remains challenging due to the lack of high-quality training data and effective test cases. To address this issue, we present SWE-Dev, an SWE agent built upon open-source LLMs. First, we develop a robust pipeline to synthesize test cases for patch evaluation. Second, we scale up agent trajectories to construct the training data for building SWE-Dev. Experiments on the SWE-bench-Verified benchmark show that the SWE-Dev models can achieve top performance among all open SWE agents. Specifically, the success rates of the SWE-Dev 7B and 32B parameter models reach 23.4% and 36.6%, respectively, outperforming state-of-the-art open-source models. All code, models, and datasets are publicly available at https://github.com/THUDM/SWE-Dev.
AndroidGen: Building an Android Language Agent under Data Scarcity
Apr 27, 2025

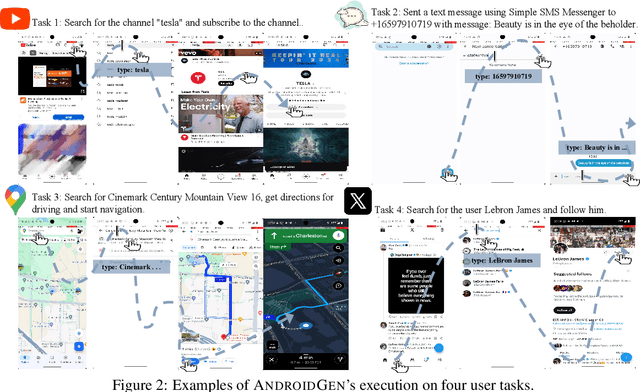
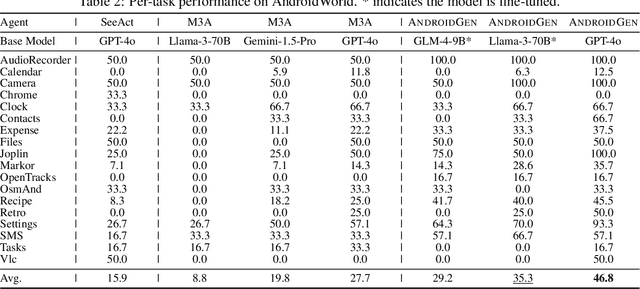
Large language models have opened up a world of possibilities for various NLP tasks, sparking optimism for the future. Despite their potential, LLMs have yet to be widely used as agents on real mobile devices. The main challenge is the need for high-quality data sources. Time constraints and labor intensity often hinder human annotation. On the other hand, existing LLMs exhibit inadequate completion rates and need a robust data filtration strategy. Given these challenges, we develop a framework called AndroidGen to enhance the capabilities of LLM-based agents under data scarcity. In addition, we leverage AndroidGen to collect trajectories given human tasks and train open-source LLMs on these trajectories to develop an open-source mobile agent without manually labeled trajectories. We extensively evaluate AndroidGen with AndroidWorld, AitW, and various popular applications, demonstrating its improvements and revealing potential areas for future improvement. Code, model, and data are available at https://github.com/THUDM/AndroidGen.
Controlling Large Language Model with Latent Actions
Mar 27, 2025Adapting Large Language Models (LLMs) to downstream tasks using Reinforcement Learning (RL) has proven to be an effective approach. However, LLMs do not inherently define the structure of an agent for RL training, particularly in terms of defining the action space. This paper studies learning a compact latent action space to enhance the controllability and exploration of RL for LLMs. We propose Controlling Large Language Models with Latent Actions (CoLA), a framework that integrates a latent action space into pre-trained LLMs. We apply CoLA to the Llama-3.1-8B model. Our experiments demonstrate that, compared to RL with token-level actions, CoLA's latent action enables greater semantic diversity in text generation. For enhancing downstream tasks, we show that CoLA with RL achieves a score of 42.4 on the math500 benchmark, surpassing the baseline score of 38.2, and reaches 68.2 when augmented with a Monte Carlo Tree Search variant. Furthermore, CoLA with RL consistently improves performance on agent-based tasks without degrading the pre-trained LLM's capabilities, unlike the baseline. Finally, CoLA reduces computation time by half in tasks involving enhanced thinking prompts for LLMs by RL. These results highlight CoLA's potential to advance RL-based adaptation of LLMs for downstream applications.