 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Large Language Model with Latent Actions
Mar 27, 2025Adapting Large Language Models (LLMs) to downstream tasks using Reinforcement Learning (RL) has proven to be an effective approach. However, LLMs do not inherently define the structure of an agent for RL training, particularly in terms of defining the action space. This paper studies learning a compact latent action space to enhance the controllability and exploration of RL for LLMs. We propose Controlling Large Language Models with Latent Actions (CoLA), a framework that integrates a latent action space into pre-trained LLMs. We apply CoLA to the Llama-3.1-8B model. Our experiments demonstrate that, compared to RL with token-level actions, CoLA's latent action enables greater semantic diversity in text generation. For enhancing downstream tasks, we show that CoLA with RL achieves a score of 42.4 on the math500 benchmark, surpassing the baseline score of 38.2, and reaches 68.2 when augmented with a Monte Carlo Tree Search variant. Furthermore, CoLA with RL consistently improves performance on agent-based tasks without degrading the pre-trained LLM's capabilities, unlike the baseline. Finally, CoLA reduces computation time by half in tasks involving enhanced thinking prompts for LLMs by RL. These results highlight CoLA's potential to advance RL-based adaptation of LLMs for downstream applications.
Q-Adapter: Training Your LLM Adapter as a Residual Q-Function
Jul 04, 2024We consider the problem of adapting Large Language Models (LLMs) pre-trained with Reinforcement Learning from Human Feedback (RLHF) to downstream preference data. Naive approaches to achieve this could be supervised fine-tuning on preferred responses or reinforcement learning with a learned reward model. However, the LLM runs the risk of forgetting its initial knowledge as the fine-tuning progresses. To customize the LLM while preserving its existing capabilities, this paper proposes a novel method, named as Q-Adapter. We start by formalizing LLM adaptation as a problem of maximizing the linear combination of two rewards, one of which corresponds to the reward optimized by the pre-trained LLM and the other to the downstream preference data. Although both rewards are unknown, we show that this can be solved by directly learning a new module from the preference data that approximates the \emph{residual Q-function}. We consider this module to be an adapter because the original pre-trained LLM, together with it, can form the optimal customised LLM. Empirically, experiments on a range of domain-specific tasks and safety alignment tasks illustrate the superiority of Q-Adapter in both anti-forgetting and learning from new preferences.
Any-step Dynamics Model Improves Future Predictions for Online and Offline Reinforcement Learning
May 27, 2024



Model-based methods in reinforcement learning offer a promising approach to enhance data efficiency by facilitating policy exploration within a dynamics model. However, accurately predicting sequential steps in the dynamics model remains a challenge due to the bootstrapping prediction, which attributes the next state to the prediction of the current state. This leads to accumulated errors during model roll-out. In this paper, we propose the Any-step Dynamics Model (ADM) to mitigate the compounding error by reducing bootstrapping prediction to direct prediction. ADM allows for the use of variable-length plans as inputs for predicting future states without frequent bootstrapping. We design two algorithms, ADMPO-ON and ADMPO-OFF, which apply ADM in online and offline model-based frameworks, respectively. In the online setting, ADMPO-ON demonstrates improved sample efficiency compared to previous state-of-the-art methods. In the offline setting, ADMPO-OFF not only demonstrates superior performance compared to recent state-of-the-art offline approaches but also offers better quantification of model uncertainty using only a single ADM.
BWArea Model: Learning World Model, Inverse Dynamics, and Policy for Controllable Language Generation
May 27, 2024



Large language models (LLMs) have catalyzed a paradigm shift in natural language processing, yet their limited controllability poses a significant challenge for downstream applications. We aim to address this by drawing inspiration from the neural mechanisms of the human brain, specifically Broca's and Wernicke's areas, which are crucial for language generation and comprehension, respectively. In particular, Broca's area receives cognitive decision signals from Wernicke's area, treating the language generation as an intricate decision-making process, which differs from the fully auto-regressive language generation of existing LLMs. In a similar vein, our proposed system, the BWArea model, conceptualizes language generation as a decision-making task. This model has three components: a language world model, an inverse dynamics model, and a cognitive policy. Like Wernicke's area, the inverse dynamics model is designed to deduce the underlying cognitive intentions, or latent actions, behind each token. The BWArea model is amenable to both pre-training and fine-tuning like existing LLMs. With 30B clean pre-training tokens, we have trained a BWArea model, which achieves competitive performance with LLMs of equal size (1B parameters). Unlike fully auto-regressive LLMs, its pre-training performance does not degenerate if dirty data unintentionally appears. This shows the advantage of a decomposed structure of BWArea model in reducing efforts in laborious data selection and labeling. Finally, we reveal that the BWArea model offers enhanced controllability via fine-tuning the cognitive policy with downstream reward metrics, thereby facilitating alignment with greater simplicity. On 9 out of 10 tasks from two suites, TextWorld and BigBench Hard, our method shows superior performance to auto-regressive LLMs.
Disentangling Policy from Offline Task Representation Learning via Adversarial Data Augmentation
Mar 12, 2024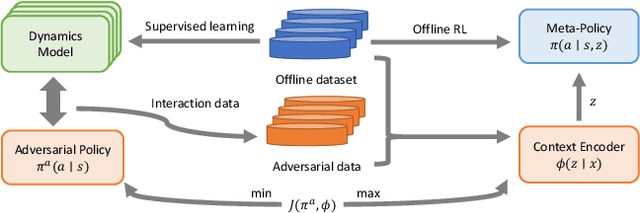
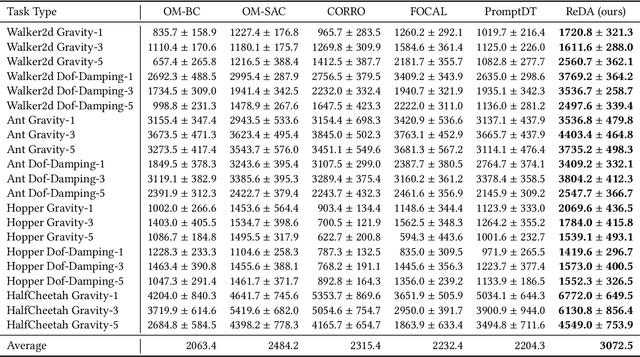
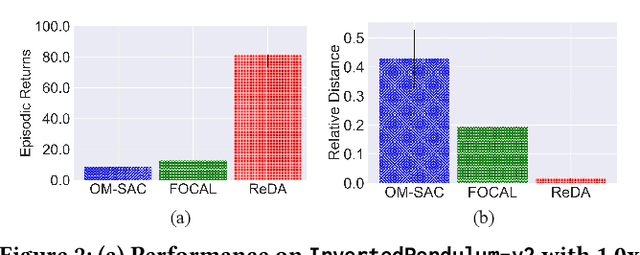
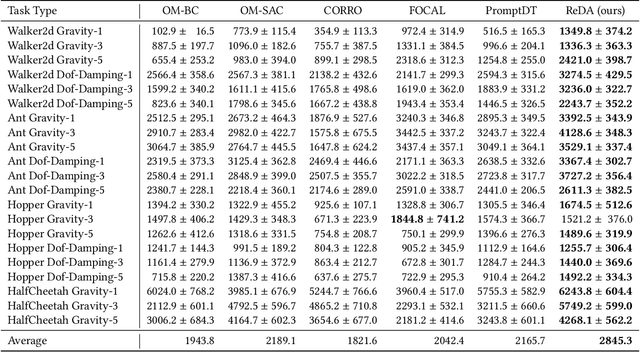
Offline meta-reinforcement learning (OMRL) proficiently allows an agent to tackle novel tasks while solely relying on a static dataset. For precise and efficient task identification, existing OMRL research suggests learning separate task representations that be incorporated with policy input, thus forming a context-based meta-policy. A major approach to train task representations is to adopt contrastive learning using multi-task offline data. The dataset typically encompasses interactions from various policies (i.e., the behavior policies), thus providing a plethora of contextual information regarding different tasks. Nonetheless, amassing data from a substantial number of policies is not only impractical but also often unattainable in realistic settings. Instead, we resort to a more constrained yet practical scenario, where multi-task data collection occurs with a limited number of policies. We observed that learned task representations from previous OMRL methods tend to correlate spuriously with the behavior policy instead of reflecting the essential characteristics of the task, resulting in unfavorable out-of-distribution generalization. To alleviate this issue, we introduce a novel algorithm to disentangle the impact of behavior policy from task representation learning through a process called adversarial data augmentation. Specifically, the objective of adversarial data augmentation is not merely to generate data analogous to offline data distribution; instead, it aims to create adversarial examples designed to confound learned task representations and lead to incorrect task identification. Our experiments show that learning from such adversarial samples significantly enhances the robustness and effectiveness of the task identification process and realizes satisfactory out-of-distribution generalization.
Debiased Offline Representation Learning for Fast Online Adaptation in Non-stationary Dynamics
Feb 17, 2024



Developing policies that can adjust to non-stationary environments is essential for real-world reinforcement learning applications. However, learning such adaptable policies in offline settings, with only a limited set of pre-collected trajectories, presents significant challenges. A key difficulty arises because the limited offline data makes it hard for the context encoder to differentiate between changes in the environment dynamics and shifts in the behavior policy, often leading to context misassociations. To address this issue, we introduce a novel approach called Debiased Offline Representation for fast online Adaptation (DORA). DORA incorporates an information bottleneck principle that maximizes mutual information between the dynamics encoding and the environmental data, while minimizing mutual information between the dynamics encoding and the actions of the behavior policy. We present a practical implementation of DORA, leveraging tractable bounds of the information bottleneck principle. Our experimental evaluation across six benchmark MuJoCo tasks with variable parameters demonstrates that DORA not only achieves a more precise dynamics encoding but also significantly outperforms existing baselines in terms of performance.
Empowering Language Models with Active Inquiry for Deeper Understanding
Feb 06, 2024The rise of large language models (LLMs) has revolutionized the way that we interact with artificial intelligence systems through natural language. However, LLMs often misinterpret user queries because of their uncertain intention, leading to less helpful responses. In natural human interactions, clarification is sought through targeted questioning to uncover obscure information. Thus, in this paper, we introduce LaMAI (Language Model with Active Inquiry), designed to endow LLMs with this same level of interactive engagement. LaMAI leverages active learning techniques to raise the most informative questions, fostering a dynamic bidirectional dialogue. This approach not only narrows the contextual gap but also refines the output of the LLMs, aligning it more closely with user expectations. Our empirical studies, across a variety of complex datasets where LLMs have limited conversational context, demonstrate the effectiveness of LaMAI. The method improves answer accuracy from 31.9% to 50.9%, outperforming other leading question-answering frameworks. Moreover, in scenarios involving human participants, LaMAI consistently generates responses that are superior or comparable to baseline methods in more than 82% of the cases. The applicability of LaMAI is further evidenced by its successful integration with various LLMs, highlighting its potential for the future of interactive language models.
Model Generation with Provable Coverability for Offline Reinforcement Learning
Jun 08, 2022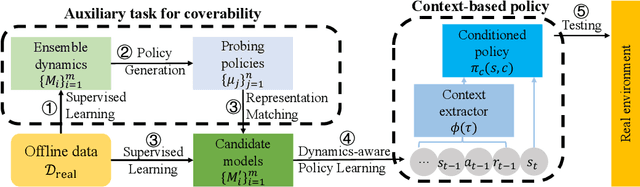
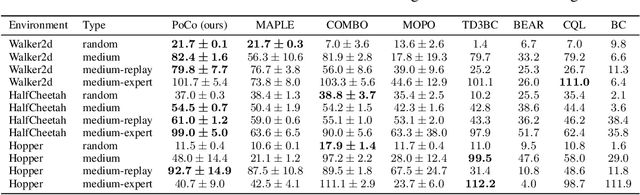
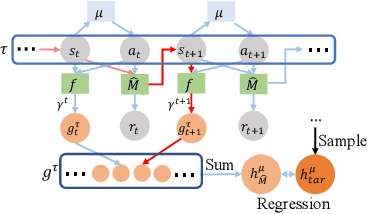
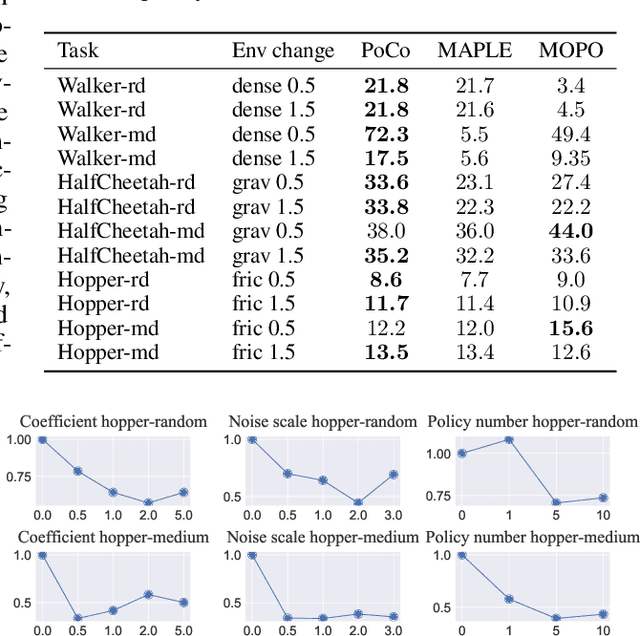
Model-based offline optimization with dynamics-aware policy provides a new perspective for policy learning and out-of-distribution generalization, where the learned policy could adapt to different dynamics enumerated at the training stage. But due to the limitation under the offline setting, the learned model could not mimic real dynamics well enough to support reliable out-of-distribution exploration, which still hinders policy to generalize well. To narrow the gap, previous works roughly ensemble randomly initialized models to better approximate the real dynamics. However, such practice is costly and inefficient, and provides no guarantee on how well the real dynamics could be approximated by the learned models, which we name coverability in this paper. We actively address this issue by generating models with provable ability to cover real dynamics in an efficient and controllable way. To that end, we design a distance metric for dynamic models based on the occupancy of policies under the dynamics, and propose an algorithm to generate models optimizing their coverage for the real dynamics. We give a theoretical analysis on the model generation process and proves that our algorithm could provide enhanced coverability. As a downstream task, we train a dynamics-aware policy with minor or no conservative penalty, and experiments demonstrate that our algorithm outperforms prior offline methods on existing offline RL benchmarks. We also discover that policies learned by our method have better zero-shot transfer performance, implying their better generalization.