 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Learning-Based Cooperative Coevolution Framework for Heterogeneous Large-Scale Global Optimization
Mar 30, 2026Cooperative Coevolution (CC) effectively addresses Large-Scale Global Optimization (LSGO) via decomposition but struggles with the emerging class of Heterogeneous LSGO (H-LSGO) problems arising from real-world applications, where subproblems exhibit diverse dimensions and distinct landscapes. The prevailing CC paradigm, relying on a fixed low-dimensional optimizer, often fails to navigate this heterogeneity. To address this limitation, we propose the Learning-Based Heterogeneous Cooperative Coevolution Framework (LH-CC). By formulating the optimization process as a Markov Decision Process, LH-CC employs a meta-agent to adaptively select the most suitable optimizer for each subproblem. We also introduce a flexible benchmark suite to generate diverse H-LSGO problem instances. Extensive experiments on 3000-dimensional problems with complex coupling relationships demonstrate that LH-CC achieves superior solution quality and computational efficiency compared to state-of-the-art baselines. Furthermore, the framework exhibits robust generalization across varying problem instances, optimization horizons, and optimizers. Our findings reveal that dynamic optimizer selection is a pivotal strategy for solving complex H-LSGO problems.
Learning from Demonstrations via Capability-Aware Goal Sampling
Jan 13, 2026Despite its promise, imitation learning often fails in long-horizon environments where perfect replication of demonstrations is unrealistic and small errors can accumulate catastrophically. We introduce Cago (Capability-Aware Goal Sampling), a novel learning-from-demonstrations method that mitigates the brittle dependence on expert trajectories for direct imitation. Unlike prior methods that rely on demonstrations only for policy initialization or reward shaping, Cago dynamically tracks the agent's competence along expert trajectories and uses this signal to select intermediate steps--goals that are just beyond the agent's current reach--to guide learning. This results in an adaptive curriculum that enables steady progress toward solving the full task. Empirical results demonstrate that Cago significantly improves sample efficiency and final performance across a range of sparse-reward, goal-conditioned tasks, consistently outperforming existing learning from-demonstrations baselines.
* 39th Conference on Neural Information Processing Systems (NeurIPS 2025)
Explainable reinforcement learning from human feedback to improve alignment
Dec 15, 2025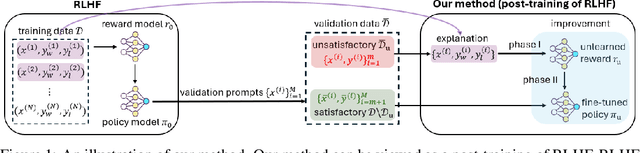
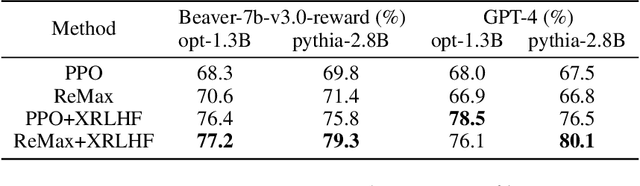

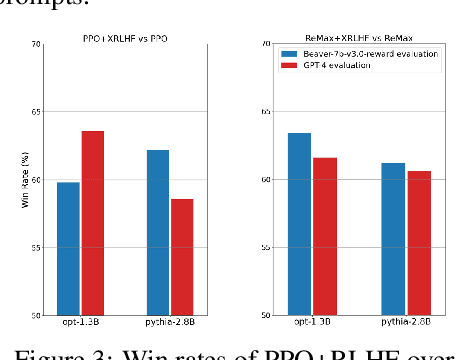
A common and effective strategy for humans to improve an unsatisfactory outcome in daily life is to find a cause of this outcome and correct the cause. In this paper, we investigate whether this human improvement strategy can be applied to improving reinforcement learning from human feedback (RLHF) for alignment of language models (LMs). In particular, it is observed in the literature that LMs tuned by RLHF can still output unsatisfactory responses. This paper proposes a method to improve the unsatisfactory responses by correcting their causes. Our method has two parts. The first part proposes a post-hoc explanation method to explain why an unsatisfactory response is generated to a prompt by identifying the training data that lead to this response. We formulate this problem as a constrained combinatorial optimization problem where the objective is to find a set of training data closest to this prompt-response pair in a feature representation space, and the constraint is that the prompt-response pair can be decomposed as a convex combination of this set of training data in the feature space. We propose an efficient iterative data selection algorithm to solve this problem. The second part proposes an unlearning method that improves unsatisfactory responses to some prompts by unlearning the training data that lead to these unsatisfactory responses and, meanwhile, does not significantly degrade satisfactory responses to other prompts. Experimental results demonstrate that our algorithm can improve RLHF.
MetaBox-v2: A Unified Benchmark Platform for Meta-Black-Box Optimization
May 23, 2025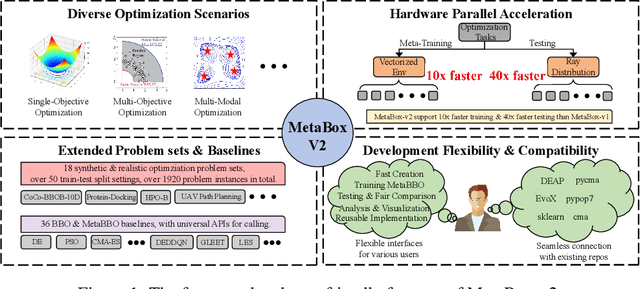
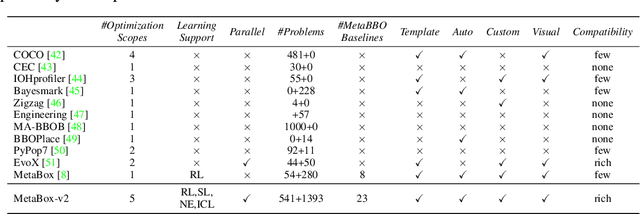
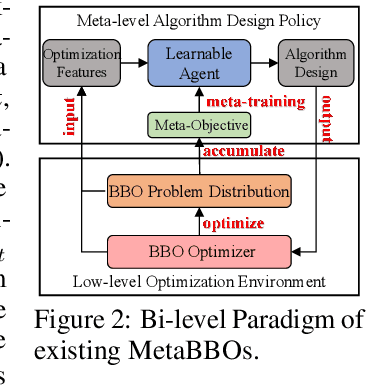
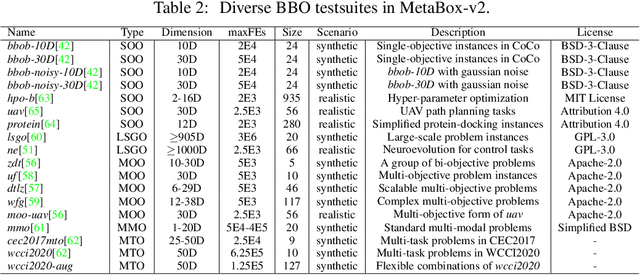
Meta-Black-Box Optimization (MetaBBO) streamlines the automation of optimization algorithm design through meta-learning. It typically employs a bi-level structure: the meta-level policy undergoes meta-training to reduce the manual effort required in developing algorithms for low-level optimization tasks. The original MetaBox (2023) provided the first open-source framework for reinforcement learning-based single-objective MetaBBO. However, its relatively narrow scope no longer keep pace with the swift advancement in this field. In this paper, we introduce MetaBox-v2 (https://github.com/MetaEvo/MetaBox) as a milestone upgrade with four novel features: 1) a unified architecture supporting RL, evolutionary, and gradient-based approaches, by which we reproduce 23 up-to-date baselines; 2) efficient parallelization schemes, which reduce the training/testing time by 10-40x; 3) a comprehensive benchmark suite of 18 synthetic/realistic tasks (1900+ instances) spanning single-objective, multi-objective, multi-model, and multi-task optimization scenarios; 4) plentiful and extensible interfaces for custom analysis/visualization and integrating to external optimization tools/benchmarks. To show the utility of MetaBox-v2, we carry out a systematic case study that evaluates the built-in baselines in terms of the optimization performance, generalization ability and learning efficiency. Valuable insights are concluded from thorough and detailed analysis for practitioners and those new to the field.
Advancing CMA-ES with Learning-Based Cooperative Coevolution for Scalable Optimization
Apr 24, 2025Recent research in Cooperative Coevolution~(CC) have achieved promising progress in solving large-scale global optimization problems. However, existing CC paradigms have a primary limitation in that they require deep expertise for selecting or designing effective variable decomposition strategies. Inspired by advancements in Meta-Black-Box Optimization, this paper introduces LCC, a pioneering learning-based cooperative coevolution framework that dynamically schedules decomposition strategies during optimization processes. The decomposition strategy selector is parameterized through a neural network, which processes a meticulously crafted set of optimization status features to determine the optimal strategy for each optimization step. The network is trained via the Proximal Policy Optimization method in a reinforcement learning manner across a collection of representative problems, aiming to maximize the expected optimization performance. Extensive experimental results demonstrate that LCC not only offers certain advantages over state-of-the-art baselines in terms of optimization effectiveness and resource consumption, but it also exhibits promising transferability towards unseen problems.
Q-Adapter: Training Your LLM Adapter as a Residual Q-Function
Jul 04, 2024We consider the problem of adapting Large Language Models (LLMs) pre-trained with Reinforcement Learning from Human Feedback (RLHF) to downstream preference data. Naive approaches to achieve this could be supervised fine-tuning on preferred responses or reinforcement learning with a learned reward model. However, the LLM runs the risk of forgetting its initial knowledge as the fine-tuning progresses. To customize the LLM while preserving its existing capabilities, this paper proposes a novel method, named as Q-Adapter. We start by formalizing LLM adaptation as a problem of maximizing the linear combination of two rewards, one of which corresponds to the reward optimized by the pre-trained LLM and the other to the downstream preference data. Although both rewards are unknown, we show that this can be solved by directly learning a new module from the preference data that approximates the \emph{residual Q-function}. We consider this module to be an adapter because the original pre-trained LLM, together with it, can form the optimal customised LLM. Empirically, experiments on a range of domain-specific tasks and safety alignment tasks illustrate the superiority of Q-Adapter in both anti-forgetting and learning from new preferences.
Debiased Offline Representation Learning for Fast Online Adaptation in Non-stationary Dynamics
Feb 17, 2024



Developing policies that can adjust to non-stationary environments is essential for real-world reinforcement learning applications. However, learning such adaptable policies in offline settings, with only a limited set of pre-collected trajectories, presents significant challenges. A key difficulty arises because the limited offline data makes it hard for the context encoder to differentiate between changes in the environment dynamics and shifts in the behavior policy, often leading to context misassociations. To address this issue, we introduce a novel approach called Debiased Offline Representation for fast online Adaptation (DORA). DORA incorporates an information bottleneck principle that maximizes mutual information between the dynamics encoding and the environmental data, while minimizing mutual information between the dynamics encoding and the actions of the behavior policy. We present a practical implementation of DORA, leveraging tractable bounds of the information bottleneck principle. Our experimental evaluation across six benchmark MuJoCo tasks with variable parameters demonstrates that DORA not only achieves a more precise dynamics encoding but also significantly outperforms existing baselines in terms of performance.