 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeedup Patch: Learning a Plug-and-Play Policy to Accelerate Embodied Manipulation
Mar 21, 2026While current embodied policies exhibit remarkable manipulation skills, their execution remains unsatisfactorily slow as they inherit the tardy pacing of human demonstrations. Existing acceleration methods typically require policy retraining or costly online interactions, limiting their scalability for large-scale foundation models. In this paper, we propose Speedup Patch (SuP), a lightweight, policy-agnostic framework that enables plug-and-play acceleration using solely offline data. SuP introduces an external scheduler that adaptively downsamples action chunks provided by embodied policies to eliminate redundancies. Specifically, we formalize the optimization of our scheduler as a Constrained Markov Decision Process (CMDP) aimed at maximizing efficiency without compromising task performance. Since direct success evaluation is infeasible in offline settings, SuP introduces World Model based state deviation as a surrogate metric to enforce safety constraints. By leveraging a learned world model as a virtual evaluator to predict counterfactual trajectories, the scheduler can be optimized via offline reinforcement learning. Empirical results on simulation benchmarks (Libero, Bigym) and real-world tasks validate that SuP achieves an overall 1.8x execution speedup for diverse policies while maintaining their original success rates.
MBD: A Model-Based Debiasing Framework Across User, Content, and Model Dimensions
Mar 15, 2026Modern recommendation systems rank candidates by aggregating multiple behavioral signals through a value model. However, many commonly used signals are inherently affected by heterogeneous biases. For example, watch time naturally favors long-form content, loop rate favors short - form content, and comment probability favors videos over images. Such biases introduce two critical issues: (1) value model scores may be systematically misaligned with users' relative preferences - for instance, a seemingly low absolute like probability may represent exceptionally strong interest for a user who rarely engages; and (2) changes in value modeling rules can trigger abrupt and undesirable ecosystem shifts. In this work, we ask a fundamental question: can biased behavioral signals be systematically transformed into unbiased signals, under a user - defined notion of ``unbiasedness'', that are both personalized and adaptive? We propose a general, model-based debiasing (MBD) framework that addresses this challenge by augmenting it with distributional modeling. By conditioning on a flexible subset of features (partial feature set), we explicitly estimate the contextual mean and variance of the engagement distribution for arbitrary cohorts (e.g., specific video lengths or user regions) directly alongside the main prediction. This integration allows the framework to convert biased raw signals into unbiased representations, enabling the construction of higher-level, calibrated signals (such as percentiles or z - scores) suitable for the value model. Importantly, the definition of unbiasedness is flexible and controllable, allowing the system to adapt to different personalization objectives and modeling preferences. Crucially, this is implemented as a lightweight, built-in branch of the existing MTML ranking model, requiring no separate serving infrastructure.
Multi-agent In-context Coordination via Decentralized Memory Retrieval
Nov 13, 2025



Large transformer models, trained on diverse datasets, have demonstrated impressive few-shot performance on previously unseen tasks without requiring parameter updates. This capability has also been explored in Reinforcement Learning (RL), where agents interact with the environment to retrieve context and maximize cumulative rewards, showcasing strong adaptability in complex settings. However, in cooperative Multi-Agent Reinforcement Learning (MARL), where agents must coordinate toward a shared goal, decentralized policy deployment can lead to mismatches in task alignment and reward assignment, limiting the efficiency of policy adaptation. To address this challenge, we introduce Multi-agent In-context Coordination via Decentralized Memory Retrieval (MAICC), a novel approach designed to enhance coordination by fast adaptation. Our method involves training a centralized embedding model to capture fine-grained trajectory representations, followed by decentralized models that approximate the centralized one to obtain team-level task information. Based on the learned embeddings, relevant trajectories are retrieved as context, which, combined with the agents' current sub-trajectories, inform decision-making. During decentralized execution, we introduce a novel memory mechanism that effectively balances test-time online data with offline memory. Based on the constructed memory, we propose a hybrid utility score that incorporates both individual- and team-level returns, ensuring credit assignment across agents. Extensive experiments on cooperative MARL benchmarks, including Level-Based Foraging (LBF) and SMAC (v1/v2), show that MAICC enables faster adaptation to unseen tasks compared to existing methods. Code is available at https://github.com/LAMDA-RL/MAICC.
Multi-agent Embodied AI: Advances and Future Directions
May 08, 2025Embodied artificial intelligence (Embodied AI) plays a pivotal role in the application of advanced technologies in the intelligent era, where AI systems are integrated with physical bodies that enable them to perceive, reason, and interact with their environments. Through the use of sensors for input and actuators for action, these systems can learn and adapt based on real-world feedback, allowing them to perform tasks effectively in dynamic and unpredictable environments. As techniques such as deep learning (DL), reinforcement learning (RL), and large language models (LLMs) mature, embodied AI has become a leading field in both academia and industry, with applications spanning robotics, healthcare, transportation, and manufacturing. However, most research has focused on single-agent systems that often assume static, closed environments, whereas real-world embodied AI must navigate far more complex scenarios. In such settings, agents must not only interact with their surroundings but also collaborate with other agents, necessitating sophisticated mechanisms for adaptation, real-time learning, and collaborative problem-solving. Despite increasing interest in multi-agent systems, existing research remains narrow in scope, often relying on simplified models that fail to capture the full complexity of dynamic, open environments for multi-agent embodied AI. Moreover, no comprehensive survey has systematically reviewed the advancements in this area. As embodied AI rapidly evolves, it is crucial to deepen our understanding of multi-agent embodied AI to address the challenges presented by real-world applications. To fill this gap and foster further development in the field, this paper reviews the current state of research, analyzes key contributions, and identifies challenges and future directions, providing insights to guide innovation and progress in this field.
HyperZero: A Customized End-to-End Auto-Tuning System for Recommendation with Hourly Feedback
Jan 30, 2025



Modern recommendation systems can be broadly divided into two key stages: the ranking stage, where the system predicts various user engagements (e.g., click-through rate, like rate, follow rate, watch time), and the value model stage, which aggregates these predictive scores through a function (e.g., a linear combination defined by a weight vector) to measure the value of each content by a single numerical score. Both stages play roughly equally important roles in real industrial systems; however, how to optimize the model weights for the second stage still lacks systematic study. This paper focuses on optimizing the second stage through auto-tuning technology. Although general auto-tuning systems and solutions - both from established production practices and open-source solutions - can address this problem, they typically require weeks or even months to identify a feasible solution. Such prolonged tuning processes are unacceptable in production environments for recommendation systems, as suboptimal value models can severely degrade user experience. An effective auto-tuning solution is required to identify a viable model within 2-3 days, rather than the extended timelines typically associated with existing approaches. In this paper, we introduce a practical auto-tuning system named HyperZero that addresses these time constraints while effectively solving the unique challenges inherent in modern recommendation systems. Moreover, this framework has the potential to be expanded to broader tuning tasks within recommendation systems.
SkillTree: Explainable Skill-Based Deep Reinforcement Learning for Long-Horizon Control Tasks
Nov 19, 2024



Deep reinforcement learning (DRL) has achieved remarkable success in various research domains. However, its reliance on neural networks results in a lack of transparency, which limits its practical applications. To achieve explainability, decision trees have emerged as a popular and promising alternative to neural networks. Nonetheless, due to their limited expressiveness, traditional decision trees struggle with high-dimensional long-horizon continuous control tasks. In this paper, we proposes SkillTree, a novel framework that reduces complex continuous action spaces into discrete skill spaces. Our hierarchical approach integrates a differentiable decision tree within the high-level policy to generate skill embeddings, which subsequently guide the low-level policy in executing skills. By making skill decisions explainable, we achieve skill-level explainability, enhancing the understanding of the decision-making process in complex tasks. Experimental results demonstrate that our method achieves performance comparable to skill-based neural networks in complex robotic arm control domains. Furthermore, SkillTree offers explanations at the skill level, thereby increasing the transparency of the decision-making process.
Stable Continual Reinforcement Learning via Diffusion-based Trajectory Replay
Nov 16, 2024



Given the inherent non-stationarity prevalent in real-world applications, continual Reinforcement Learning (RL) aims to equip the agent with the capability to address a series of sequentially presented decision-making tasks. Within this problem setting, a pivotal challenge revolves around \textit{catastrophic forgetting} issue, wherein the agent is prone to effortlessly erode the decisional knowledge associated with past encountered tasks when learning the new one. In recent progresses, the \textit{generative replay} methods have showcased substantial potential by employing generative models to replay data distribution of past tasks. Compared to storing the data from past tasks directly, this category of methods circumvents the growing storage overhead and possible data privacy concerns. However, constrained by the expressive capacity of generative models, existing \textit{generative replay} methods face challenges in faithfully reconstructing the data distribution of past tasks, particularly in scenarios with a myriad of tasks or high-dimensional data. Inspired by the success of diffusion models in various generative tasks, this paper introduces a novel continual RL algorithm DISTR (Diffusion-based Trajectory Replay) that employs a diffusion model to memorize the high-return trajectory distribution of each encountered task and wakeups these distributions during the policy learning on new tasks. Besides, considering the impracticality of replaying all past data each time, a prioritization mechanism is proposed to prioritize the trajectory replay of pivotal tasks in our method. Empirical experiments on the popular continual RL benchmark \texttt{Continual World} demonstrate that our proposed method obtains a favorable balance between \textit{stability} and \textit{plasticity}, surpassing various existing continual RL baselines in average success rate.
Q-Adapter: Training Your LLM Adapter as a Residual Q-Function
Jul 04, 2024We consider the problem of adapting Large Language Models (LLMs) pre-trained with Reinforcement Learning from Human Feedback (RLHF) to downstream preference data. Naive approaches to achieve this could be supervised fine-tuning on preferred responses or reinforcement learning with a learned reward model. However, the LLM runs the risk of forgetting its initial knowledge as the fine-tuning progresses. To customize the LLM while preserving its existing capabilities, this paper proposes a novel method, named as Q-Adapter. We start by formalizing LLM adaptation as a problem of maximizing the linear combination of two rewards, one of which corresponds to the reward optimized by the pre-trained LLM and the other to the downstream preference data. Although both rewards are unknown, we show that this can be solved by directly learning a new module from the preference data that approximates the \emph{residual Q-function}. We consider this module to be an adapter because the original pre-trained LLM, together with it, can form the optimal customised LLM. Empirically, experiments on a range of domain-specific tasks and safety alignment tasks illustrate the superiority of Q-Adapter in both anti-forgetting and learning from new preferences.
Disentangling Policy from Offline Task Representation Learning via Adversarial Data Augmentation
Mar 12, 2024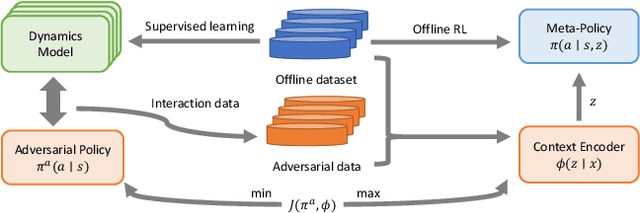
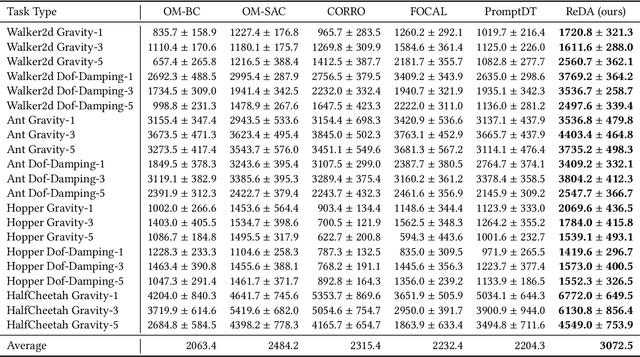
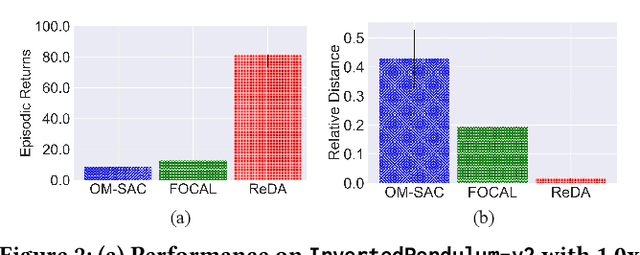
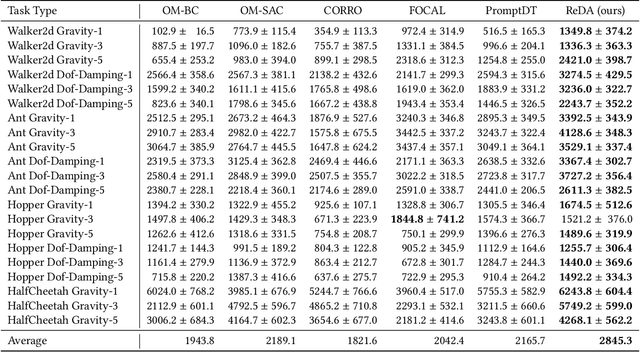
Offline meta-reinforcement learning (OMRL) proficiently allows an agent to tackle novel tasks while solely relying on a static dataset. For precise and efficient task identification, existing OMRL research suggests learning separate task representations that be incorporated with policy input, thus forming a context-based meta-policy. A major approach to train task representations is to adopt contrastive learning using multi-task offline data. The dataset typically encompasses interactions from various policies (i.e., the behavior policies), thus providing a plethora of contextual information regarding different tasks. Nonetheless, amassing data from a substantial number of policies is not only impractical but also often unattainable in realistic settings. Instead, we resort to a more constrained yet practical scenario, where multi-task data collection occurs with a limited number of policies. We observed that learned task representations from previous OMRL methods tend to correlate spuriously with the behavior policy instead of reflecting the essential characteristics of the task, resulting in unfavorable out-of-distribution generalization. To alleviate this issue, we introduce a novel algorithm to disentangle the impact of behavior policy from task representation learning through a process called adversarial data augmentation. Specifically, the objective of adversarial data augmentation is not merely to generate data analogous to offline data distribution; instead, it aims to create adversarial examples designed to confound learned task representations and lead to incorrect task identification. Our experiments show that learning from such adversarial samples significantly enhances the robustness and effectiveness of the task identification process and realizes satisfactory out-of-distribution generalization.
Debiased Offline Representation Learning for Fast Online Adaptation in Non-stationary Dynamics
Feb 17, 2024



Developing policies that can adjust to non-stationary environments is essential for real-world reinforcement learning applications. However, learning such adaptable policies in offline settings, with only a limited set of pre-collected trajectories, presents significant challenges. A key difficulty arises because the limited offline data makes it hard for the context encoder to differentiate between changes in the environment dynamics and shifts in the behavior policy, often leading to context misassociations. To address this issue, we introduce a novel approach called Debiased Offline Representation for fast online Adaptation (DORA). DORA incorporates an information bottleneck principle that maximizes mutual information between the dynamics encoding and the environmental data, while minimizing mutual information between the dynamics encoding and the actions of the behavior policy. We present a practical implementation of DORA, leveraging tractable bounds of the information bottleneck principle. Our experimental evaluation across six benchmark MuJoCo tasks with variable parameters demonstrates that DORA not only achieves a more precise dynamics encoding but also significantly outperforms existing baselines in terms of performance.