 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillTree: Explainable Skill-Based Deep Reinforcement Learning for Long-Horizon Control Tasks
Nov 19, 2024



Deep reinforcement learning (DRL) has achieved remarkable success in various research domains. However, its reliance on neural networks results in a lack of transparency, which limits its practical applications. To achieve explainability, decision trees have emerged as a popular and promising alternative to neural networks. Nonetheless, due to their limited expressiveness, traditional decision trees struggle with high-dimensional long-horizon continuous control tasks. In this paper, we proposes SkillTree, a novel framework that reduces complex continuous action spaces into discrete skill spaces. Our hierarchical approach integrates a differentiable decision tree within the high-level policy to generate skill embeddings, which subsequently guide the low-level policy in executing skills. By making skill decisions explainable, we achieve skill-level explainability, enhancing the understanding of the decision-making process in complex tasks. Experimental results demonstrate that our method achieves performance comparable to skill-based neural networks in complex robotic arm control domains. Furthermore, SkillTree offers explanations at the skill level, thereby increasing the transparency of the decision-making process.
An Imitative Reinforcement Learning Framework for Autonomous Dogfight
Jun 17, 2024Unmanned Combat Aerial Vehicle (UCAV) dogfight, which refers to a fight between two or more UCAVs usually at close quarters, plays a decisive role on the aerial battlefields. With the evolution of artificial intelligence, dogfight progressively transits towards intelligent and autonomous modes. However, the development of autonomous dogfight policy learning is hindered by challenges such as weak exploration capabilities, low learning efficiency, and unrealistic simulated environments. To overcome these challenges, this paper proposes a novel imitative reinforcement learning framework, which efficiently leverages expert data while enabling autonomous exploration. The proposed framework not only enhances learning efficiency through expert imitation, but also ensures adaptability to dynamic environments via autonomous exploration with reinforcement learning. Therefore, the proposed framework can learn a successful dogfight policy of 'pursuit-lock-launch' for UCAVs. To support data-driven learning, we establish a dogfight environment based on the Harfang3D sandbox, where we conduct extensive experiments. The results indicate that the proposed framework excels in multistage dogfight, significantly outperforms state-of-the-art reinforcement learning and imitation learning methods. Thanks to the ability of imitating experts and autonomous exploration, our framework can quickly learn the critical knowledge in complex aerial combat tasks, achieving up to a 100% success rate and demonstrating excellent robustness.
Robust Visual Imitation Learning with Inverse Dynamics Representations
Oct 22, 2023
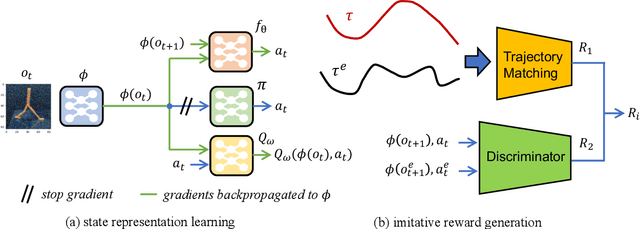


Imitation learning (IL) has achieved considerable success in solving complex sequential decision-making problems. However, current IL methods mainly assume that the environment for learning policies is the same as the environment for collecting expert datasets. Therefore, these methods may fail to work when there are slight differences between the learning and expert environments, especially for challenging problems with high-dimensional image observations. However, in real-world scenarios, it is rare to have the chance to collect expert trajectories precisely in the target learning environment. To address this challenge, we propose a novel robust imitation learning approach, where we develop an inverse dynamics state representation learning objective to align the expert environment and the learning environment. With the abstract state representation, we design an effective reward function, which thoroughly measures the similarity between behavior data and expert data not only element-wise, but also from the trajectory level. We conduct extensive experiments to evaluate the proposed approach under various visual perturbations and in diverse visual control tasks. Our approach can achieve a near-expert performance in most environments, and significantly outperforms the state-of-the-art visual IL methods and robust IL methods.