 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Planner: Empowering Safety Awareness in Large Pre-Trained Models for Robot Task Planning
Nov 11, 2024
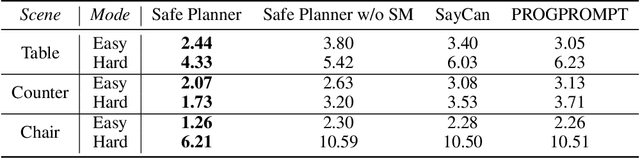
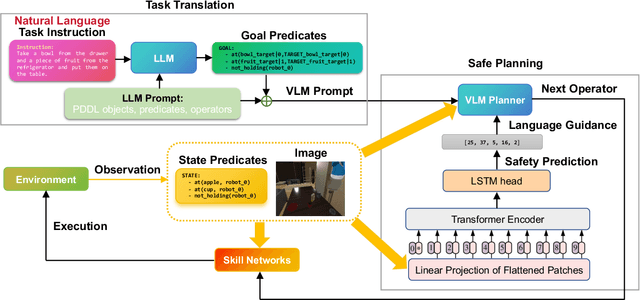
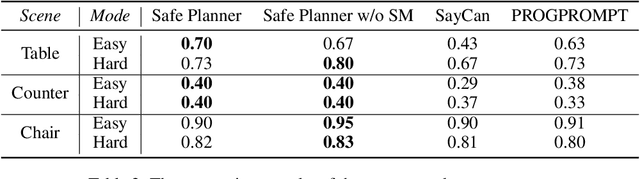
Robot task planning is an important problem for autonomous robots in long-horizon challenging tasks. As large pre-trained models have demonstrated superior planning ability, recent research investigates utilizing large models to achieve autonomous planning for robots in diverse tasks. However, since the large models are pre-trained with Internet data and lack the knowledge of real task scenes, large models as planners may make unsafe decisions that hurt the robots and the surrounding environments. To solve this challenge, we propose a novel Safe Planner framework, which empowers safety awareness in large pre-trained models to accomplish safe and executable planning. In this framework, we develop a safety prediction module to guide the high-level large model planner, and this safety module trained in a simulator can be effectively transferred to real-world tasks. The proposed Safe Planner framework is evaluated on both simulated environments and real robots. The experiment results demonstrate that Safe Planner not only achieves state-of-the-art task success rates, but also substantially improves safety during task execution. The experiment videos are shown in https://sites.google.com/view/safeplanner .
Robust Visual Imitation Learning with Inverse Dynamics Representations
Oct 22, 2023
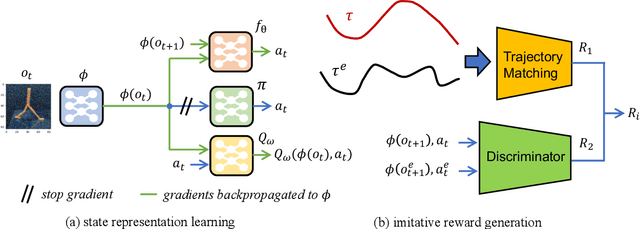


Imitation learning (IL) has achieved considerable success in solving complex sequential decision-making problems. However, current IL methods mainly assume that the environment for learning policies is the same as the environment for collecting expert datasets. Therefore, these methods may fail to work when there are slight differences between the learning and expert environments, especially for challenging problems with high-dimensional image observations. However, in real-world scenarios, it is rare to have the chance to collect expert trajectories precisely in the target learning environment. To address this challenge, we propose a novel robust imitation learning approach, where we develop an inverse dynamics state representation learning objective to align the expert environment and the learning environment. With the abstract state representation, we design an effective reward function, which thoroughly measures the similarity between behavior data and expert data not only element-wise, but also from the trajectory level. We conduct extensive experiments to evaluate the proposed approach under various visual perturbations and in diverse visual control tasks. Our approach can achieve a near-expert performance in most environments, and significantly outperforms the state-of-the-art visual IL methods and robust IL methods.