 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Delayed-Update Cyclic Algorithm for Variational Inequalities
Mar 31, 2026Cyclic block coordinate methods are a fundamental class of first-order algorithms, widely used in practice for their simplicity and strong empirical performance. Yet, their theoretical behavior remains challenging to explain, and setting their step sizes -- beyond classical coordinate descent for minimization -- typically requires careful tuning or line-search machinery. In this work, we develop $\texttt{ADUCA}$ (Adaptive Delayed-Update Cyclic Algorithm), a cyclic algorithm addressing a broad class of Minty variational inequalities with monotone Lipschitz operators. $\texttt{ADUCA}$ is parameter-free: it requires no global or block-wise Lipschitz constants and uses no per-epoch line search, except at initialization. A key feature of the algorithm is using operator information delayed by a full cycle, which makes the algorithm compatible with parallel and distributed implementations, and attractive due to weakened synchronization requirements across blocks. We prove that $\texttt{ADUCA}$ attains (near) optimal global oracle complexity as a function of target error $ε>0,$ scaling with $1/ε$ for monotone operators, or with $\log^2(1/ε)$ for operators that are strongly monotone.
HyperZero: A Customized End-to-End Auto-Tuning System for Recommendation with Hourly Feedback
Jan 30, 2025



Modern recommendation systems can be broadly divided into two key stages: the ranking stage, where the system predicts various user engagements (e.g., click-through rate, like rate, follow rate, watch time), and the value model stage, which aggregates these predictive scores through a function (e.g., a linear combination defined by a weight vector) to measure the value of each content by a single numerical score. Both stages play roughly equally important roles in real industrial systems; however, how to optimize the model weights for the second stage still lacks systematic study. This paper focuses on optimizing the second stage through auto-tuning technology. Although general auto-tuning systems and solutions - both from established production practices and open-source solutions - can address this problem, they typically require weeks or even months to identify a feasible solution. Such prolonged tuning processes are unacceptable in production environments for recommendation systems, as suboptimal value models can severely degrade user experience. An effective auto-tuning solution is required to identify a viable model within 2-3 days, rather than the extended timelines typically associated with existing approaches. In this paper, we introduce a practical auto-tuning system named HyperZero that addresses these time constraints while effectively solving the unique challenges inherent in modern recommendation systems. Moreover, this framework has the potential to be expanded to broader tuning tasks within recommendation systems.
Last Iterate Convergence of Incremental Methods and Applications in Continual Learning
Mar 11, 2024Incremental gradient methods and incremental proximal methods are a fundamental class of optimization algorithms used for solving finite sum problems, broadly studied in the literature. Yet, when it comes to their convergence guarantees, nonasymptotic (first-order or proximal) oracle complexity bounds have been obtained fairly recently, almost exclusively applying to the average iterate. Motivated by applications in continual learning, we obtain the first convergence guarantees for the last iterate of both incremental gradient and incremental proximal methods, in general convex smooth (for both) and convex Lipschitz (for the proximal variants) settings. Our oracle complexity bounds for the last iterate nearly match (i.e., match up to a square-root-log or a log factor) the best known oracle complexity bounds for the average iterate, for both classes of methods. We further obtain generalizations of our results to weighted averaging of the iterates with increasing weights, which can be seen as interpolating between the last iterate and the average iterate guarantees. Additionally, we discuss how our results can be generalized to variants of studied incremental methods with permuted ordering of updates. Our results generalize last iterate guarantees for incremental methods compared to state of the art, as such results were previously known only for overparameterized linear models, which correspond to convex quadratic problems with infinitely many solutions.
Variance Reduced Halpern Iteration for Finite-Sum Monotone Inclusions
Oct 04, 2023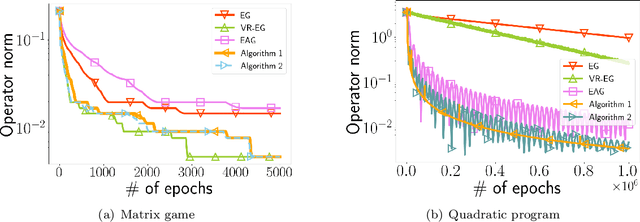
Machine learning approaches relying on such criteria as adversarial robustness or multi-agent settings have raised the need for solving game-theoretic equilibrium problems. Of particular relevance to these applications are methods targeting finite-sum structure, which generically arises in empirical variants of learning problems in these contexts. Further, methods with computable approximation errors are highly desirable, as they provide verifiable exit criteria. Motivated by these applications, we study finite-sum monotone inclusion problems, which model broad classes of equilibrium problems. Our main contributions are variants of the classical Halpern iteration that employ variance reduction to obtain improved complexity guarantees in which $n$ component operators in the finite sum are ``on average'' either cocoercive or Lipschitz continuous and monotone, with parameter $L$. The resulting oracle complexity of our methods, which provide guarantees for the last iterate and for a (computable) operator norm residual, is $\widetilde{\mathcal{O}}( n + \sqrt{n}L\varepsilon^{-1})$, which improves upon existing methods by a factor up to $\sqrt{n}$. This constitutes the first variance reduction-type result for general finite-sum monotone inclusions and for more specific problems such as convex-concave optimization when operator norm residual is the optimality measure. We further argue that, up to poly-logarithmic factors, this complexity is unimprovable in the monotone Lipschitz setting; i.e., the provided result is near-optimal.
Empirical Risk Minimization with Shuffled SGD: A Primal-Dual Perspective and Improved Bounds
Jun 21, 2023Stochastic gradient descent (SGD) is perhaps the most prevalent optimization method in modern machine learning. Contrary to the empirical practice of sampling from the datasets without replacement and with (possible) reshuffling at each epoch, the theoretical counterpart of SGD usually relies on the assumption of sampling with replacement. It is only very recently that SGD with sampling without replacement -- shuffled SGD -- has been analyzed. For convex finite sum problems with $n$ components and under the $L$-smoothness assumption for each component function, there are matching upper and lower bounds, under sufficiently small -- $\mathcal{O}(\frac{1}{nL})$ -- step sizes. Yet those bounds appear too pessimistic -- in fact, the predicted performance is generally no better than for full gradient descent -- and do not agree with the empirical observations. In this work, to narrow the gap between the theory and practice of shuffled SGD, we sharpen the focus from general finite sum problems to empirical risk minimization with linear predictors. This allows us to take a primal-dual perspective and interpret shuffled SGD as a primal-dual method with cyclic coordinate updates on the dual side. Leveraging this perspective, we prove a fine-grained complexity bound that depends on the data matrix and is never worse than what is predicted by the existing bounds. Notably, our bound can predict much faster convergence than the existing analyses -- by a factor of the order of $\sqrt{n}$ in some cases. We empirically demonstrate that on common machine learning datasets our bound is indeed much tighter. We further show how to extend our analysis to convex nonsmooth problems, with similar improvements.
Cyclic Block Coordinate Descent With Variance Reduction for Composite Nonconvex Optimization
Dec 09, 2022Nonconvex optimization is central in solving many machine learning problems, in which block-wise structure is commonly encountered. In this work, we propose cyclic block coordinate methods for nonconvex optimization problems with non-asymptotic gradient norm guarantees. Our convergence analysis is based on a gradient Lipschitz condition with respect to a Mahalanobis norm, inspired by a recent progress on cyclic block coordinate methods. In deterministic settings, our convergence guarantee matches the guarantee of (full-gradient) gradient descent, but with the gradient Lipschitz constant being defined w.r.t.~the Mahalanobis norm. In stochastic settings, we use recursive variance reduction to decrease the per-iteration cost and match the arithmetic operation complexity of current optimal stochastic full-gradient methods, with a unified analysis for both finite-sum and infinite-sum cases. We further prove the faster, linear convergence of our methods when a Polyak-{\L}ojasiewicz (P{\L}) condition holds for the objective function. To the best of our knowledge, our work is the first to provide variance-reduced convergence guarantees for a cyclic block coordinate method. Our experimental results demonstrate the efficacy of the proposed variance-reduced cyclic scheme in training deep neural nets.
A Stochastic Halpern Iteration with Variance Reduction for Stochastic Monotone Inclusion Problems
Mar 21, 2022We study stochastic monotone inclusion problems, which widely appear in machine learning applications, including robust regression and adversarial learning. We propose novel variants of stochastic Halpern iteration with recursive variance reduction. In the cocoercive -- and more generally Lipschitz-monotone -- setup, our algorithm attains $\epsilon$ norm of the operator with $\mathcal{O}(\frac{1}{\epsilon^3})$ stochastic operator evaluations, which significantly improves over state of the art $\mathcal{O}(\frac{1}{\epsilon^4})$ stochastic operator evaluations required for existing monotone inclusion solvers applied to the same problem classes. We further show how to couple one of the proposed variants of stochastic Halpern iteration with a scheduled restart scheme to solve stochastic monotone inclusion problems with ${\mathcal{O}}(\frac{\log(1/\epsilon)}{\epsilon^2})$ stochastic operator evaluations under additional sharpness or strong monotonicity assumptions. Finally, we argue via reductions between different problem classes that our stochastic oracle complexity bounds are tight up to logarithmic factors in terms of their $\epsilon$-dependence.