 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMBD: A Model-Based Debiasing Framework Across User, Content, and Model Dimensions
Mar 15, 2026Modern recommendation systems rank candidates by aggregating multiple behavioral signals through a value model. However, many commonly used signals are inherently affected by heterogeneous biases. For example, watch time naturally favors long-form content, loop rate favors short - form content, and comment probability favors videos over images. Such biases introduce two critical issues: (1) value model scores may be systematically misaligned with users' relative preferences - for instance, a seemingly low absolute like probability may represent exceptionally strong interest for a user who rarely engages; and (2) changes in value modeling rules can trigger abrupt and undesirable ecosystem shifts. In this work, we ask a fundamental question: can biased behavioral signals be systematically transformed into unbiased signals, under a user - defined notion of ``unbiasedness'', that are both personalized and adaptive? We propose a general, model-based debiasing (MBD) framework that addresses this challenge by augmenting it with distributional modeling. By conditioning on a flexible subset of features (partial feature set), we explicitly estimate the contextual mean and variance of the engagement distribution for arbitrary cohorts (e.g., specific video lengths or user regions) directly alongside the main prediction. This integration allows the framework to convert biased raw signals into unbiased representations, enabling the construction of higher-level, calibrated signals (such as percentiles or z - scores) suitable for the value model. Importantly, the definition of unbiasedness is flexible and controllable, allowing the system to adapt to different personalization objectives and modeling preferences. Crucially, this is implemented as a lightweight, built-in branch of the existing MTML ranking model, requiring no separate serving infrastructure.
HyperZero: A Customized End-to-End Auto-Tuning System for Recommendation with Hourly Feedback
Jan 30, 2025



Modern recommendation systems can be broadly divided into two key stages: the ranking stage, where the system predicts various user engagements (e.g., click-through rate, like rate, follow rate, watch time), and the value model stage, which aggregates these predictive scores through a function (e.g., a linear combination defined by a weight vector) to measure the value of each content by a single numerical score. Both stages play roughly equally important roles in real industrial systems; however, how to optimize the model weights for the second stage still lacks systematic study. This paper focuses on optimizing the second stage through auto-tuning technology. Although general auto-tuning systems and solutions - both from established production practices and open-source solutions - can address this problem, they typically require weeks or even months to identify a feasible solution. Such prolonged tuning processes are unacceptable in production environments for recommendation systems, as suboptimal value models can severely degrade user experience. An effective auto-tuning solution is required to identify a viable model within 2-3 days, rather than the extended timelines typically associated with existing approaches. In this paper, we introduce a practical auto-tuning system named HyperZero that addresses these time constraints while effectively solving the unique challenges inherent in modern recommendation systems. Moreover, this framework has the potential to be expanded to broader tuning tasks within recommendation systems.
KML: Using Machine Learning to Improve Storage Systems
Nov 22, 2021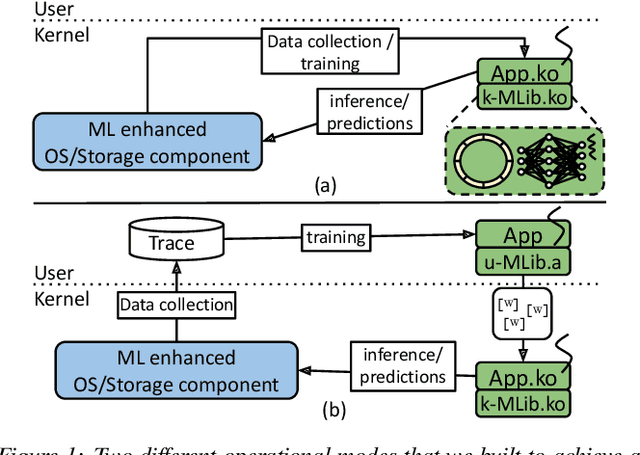
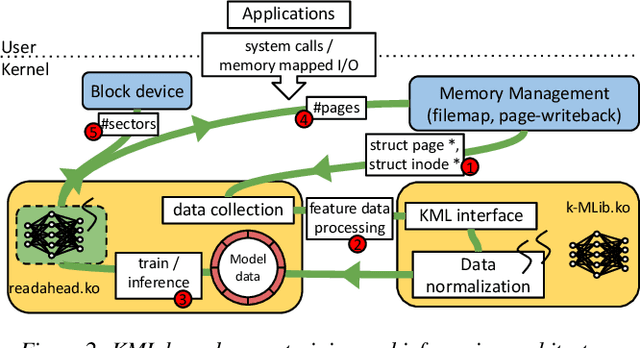

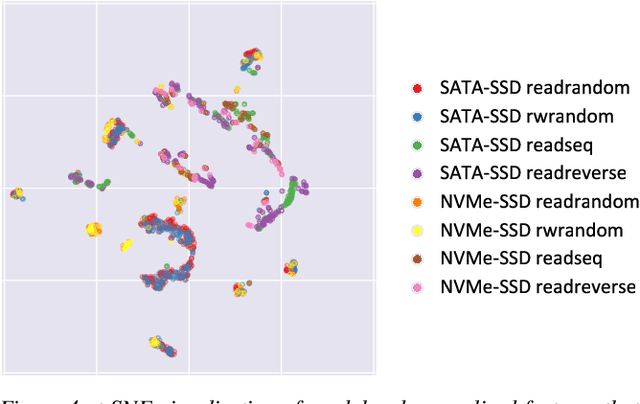
Operating systems include many heuristic algorithms designed to improve overall storage performance and throughput. Because such heuristics cannot work well for all conditions and workloads, system designers resorted to exposing numerous tunable parameters to users -- essentially burdening users with continually optimizing their own storage systems and applications. Storage systems are usually responsible for most latency in I/O heavy applications, so even a small overall latency improvement can be significant. Machine learning (ML) techniques promise to learn patterns, generalize from them, and enable optimal solutions that adapt to changing workloads. We propose that ML solutions become a first-class component in OSs and replace manual heuristics to optimize storage systems dynamically. In this paper, we describe our proposed ML architecture, called KML. We developed a prototype KML architecture and applied it to two problems: optimal readahead and NFS read-size values. Our experiments show that KML consumes little OS resources, adds negligible latency, and yet can learn patterns that can improve I/O throughput by as much as 2.3x or 15x for the two use cases respectively -- even for complex, never-before-seen, concurrently running mixed workloads on different storage devices.