 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Stochastic Variational Inequalities without the Bounded Variance Assumption
Feb 05, 2026We analyze algorithms for solving stochastic variational inequalities (VI) without the bounded variance or bounded domain assumptions, where our main focus is min-max optimization with possibly unbounded constraint sets. We focus on two classes of problems: monotone VIs; and structured nonmonotone VIs that admit a solution to the weak Minty VI. The latter assumption allows us to solve structured nonconvex-nonconcave min-max problems. For both classes of VIs, to make the expected residual norm less than $\varepsilon$, we show an oracle complexity of $\widetilde{O}(\varepsilon^{-4})$, which is the best-known for constrained VIs. In our setting, this complexity had been obtained with the bounded variance assumption in the literature, which is not even satisfied for bilinear min-max problems with an unbounded domain. We obtain this complexity for stochastic oracles whose variance can grow as fast as the squared norm of the optimization variable.
Convergence Rate of the Last Iterate of Stochastic Proximal Algorithms
Feb 05, 2026We analyze two classical algorithms for solving additively composite convex optimization problems where the objective is the sum of a smooth term and a nonsmooth regularizer: proximal stochastic gradient method for a single regularizer; and the randomized incremental proximal method, which uses the proximal operator of a randomly selected function when the regularizer is given as the sum of many nonsmooth functions. We focus on relaxing the bounded variance assumption that is common, yet stringent, for getting last iterate convergence rates. We prove the $\widetilde{O}(1/\sqrt{T})$ rate of convergence for the last iterate of both algorithms under componentwise convexity and smoothness, which is optimal up to log terms. Our results apply directly to graph-guided regularizers that arise in multi-task and federated learning, where the regularizer decomposes as a sum over edges of a collaboration graph.
Decentralized Optimization with Topology-Independent Communication
Sep 17, 2025Distributed optimization requires nodes to coordinate, yet full synchronization scales poorly. When $n$ nodes collaborate through $m$ pairwise regularizers, standard methods demand $\mathcal{O}(m)$ communications per iteration. This paper proposes randomized local coordination: each node independently samples one regularizer uniformly and coordinates only with nodes sharing that term. This exploits partial separability, where each regularizer $G_j$ depends on a subset $S_j \subseteq \{1,\ldots,n\}$ of nodes. For graph-guided regularizers where $|S_j|=2$, expected communication drops to exactly 2 messages per iteration. This method achieves $\tilde{\mathcal{O}}(\varepsilon^{-2})$ iterations for convex objectives and under strong convexity, $\mathcal{O}(\varepsilon^{-1})$ to an $\varepsilon$-solution and $\mathcal{O}(\log(1/\varepsilon))$ to a neighborhood. Replacing the proximal map of the sum $\sum_j G_j$ with the proximal map of a single randomly selected regularizer $G_j$ preserves convergence while eliminating global coordination. Experiments validate both convergence rates and communication efficiency across synthetic and real-world datasets.
Towards Weaker Variance Assumptions for Stochastic Optimization
Apr 14, 2025We revisit a classical assumption for analyzing stochastic gradient algorithms where the squared norm of the stochastic subgradient (or the variance for smooth problems) is allowed to grow as fast as the squared norm of the optimization variable. We contextualize this assumption in view of its inception in the 1960s, its seemingly independent appearance in the recent literature, its relationship to weakest-known variance assumptions for analyzing stochastic gradient algorithms, and its relevance in deterministic problems for non-Lipschitz nonsmooth convex optimization. We build on and extend a connection recently made between this assumption and the Halpern iteration. For convex nonsmooth, and potentially stochastic, optimization, we analyze horizon-free, anytime algorithms with last-iterate rates. For problems beyond simple constrained optimization, such as convex problems with functional constraints or regularized convex-concave min-max problems, we obtain rates for optimality measures that do not require boundedness of the feasible set.
Stochastic Smoothed Primal-Dual Algorithms for Nonconvex Optimization with Linear Inequality Constraints
Apr 10, 2025
We propose smoothed primal-dual algorithms for solving stochastic and smooth nonconvex optimization problems with linear inequality constraints. Our algorithms are single-loop and only require a single stochastic gradient based on one sample at each iteration. A distinguishing feature of our algorithm is that it is based on an inexact gradient descent framework for the Moreau envelope, where the gradient of the Moreau envelope is estimated using one step of a stochastic primal-dual augmented Lagrangian method. To handle inequality constraints and stochasticity, we combine the recently established global error bounds in constrained optimization with a Moreau envelope-based analysis of stochastic proximal algorithms. For obtaining $\varepsilon$-stationary points, we establish the optimal $O(\varepsilon^{-4})$ sample complexity guarantee for our algorithms and provide extensions to stochastic linear constraints. We also show how to improve this complexity to $O(\varepsilon^{-3})$ by using variance reduction and the expected smoothness assumption. Unlike existing methods, the iterations of our algorithms are free of subproblems, large batch sizes or increasing penalty parameters and use dual variable updates to ensure feasibility.
Extending the Reach of First-Order Algorithms for Nonconvex Min-Max Problems with Cohypomonotonicity
Feb 07, 2024We focus on constrained, $L$-smooth, nonconvex-nonconcave min-max problems either satisfying $\rho$-cohypomonotonicity or admitting a solution to the $\rho$-weakly Minty Variational Inequality (MVI), where larger values of the parameter $\rho>0$ correspond to a greater degree of nonconvexity. These problem classes include examples in two player reinforcement learning, interaction dominant min-max problems, and certain synthetic test problems on which classical min-max algorithms fail. It has been conjectured that first-order methods can tolerate value of $\rho$ no larger than $\frac{1}{L}$, but existing results in the literature have stagnated at the tighter requirement $\rho < \frac{1}{2L}$. With a simple argument, we obtain optimal or best-known complexity guarantees with cohypomonotonicity or weak MVI conditions for $\rho < \frac{1}{L}$. The algorithms we analyze are inexact variants of Halpern and Krasnosel'ski\u{\i}-Mann (KM) iterations. We also provide algorithms and complexity guarantees in the stochastic case with the same range on $\rho$. Our main insight for the improvements in the convergence analyses is to harness the recently proposed "conic nonexpansiveness" property of operators. As byproducts, we provide a refined analysis for inexact Halpern iteration and propose a stochastic KM iteration with a multilevel Monte Carlo estimator.
Complexity of Single Loop Algorithms for Nonlinear Programming with Stochastic Objective and Constraints
Nov 01, 2023We analyze the complexity of single-loop quadratic penalty and augmented Lagrangian algorithms for solving nonconvex optimization problems with functional equality constraints. We consider three cases, in all of which the objective is stochastic and smooth, that is, an expectation over an unknown distribution that is accessed by sampling. The nature of the equality constraints differs among the three cases: deterministic and linear in the first case, deterministic, smooth and nonlinear in the second case, and stochastic, smooth and nonlinear in the third case. Variance reduction techniques are used to improve the complexity. To find a point that satisfies $\varepsilon$-approximate first-order conditions, we require $\widetilde{O}(\varepsilon^{-3})$ complexity in the first case, $\widetilde{O}(\varepsilon^{-4})$ in the second case, and $\widetilde{O}(\varepsilon^{-5})$ in the third case. For the first and third cases, they are the first algorithms of "single loop" type (that also use $O(1)$ samples at each iteration) that still achieve the best-known complexity guarantees.
Variance Reduced Halpern Iteration for Finite-Sum Monotone Inclusions
Oct 04, 2023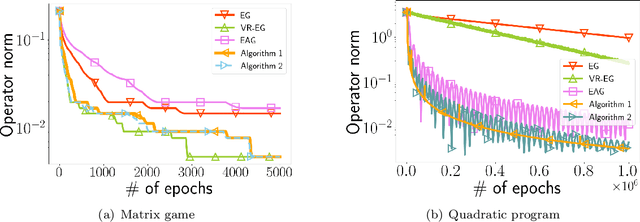
Machine learning approaches relying on such criteria as adversarial robustness or multi-agent settings have raised the need for solving game-theoretic equilibrium problems. Of particular relevance to these applications are methods targeting finite-sum structure, which generically arises in empirical variants of learning problems in these contexts. Further, methods with computable approximation errors are highly desirable, as they provide verifiable exit criteria. Motivated by these applications, we study finite-sum monotone inclusion problems, which model broad classes of equilibrium problems. Our main contributions are variants of the classical Halpern iteration that employ variance reduction to obtain improved complexity guarantees in which $n$ component operators in the finite sum are ``on average'' either cocoercive or Lipschitz continuous and monotone, with parameter $L$. The resulting oracle complexity of our methods, which provide guarantees for the last iterate and for a (computable) operator norm residual, is $\widetilde{\mathcal{O}}( n + \sqrt{n}L\varepsilon^{-1})$, which improves upon existing methods by a factor up to $\sqrt{n}$. This constitutes the first variance reduction-type result for general finite-sum monotone inclusions and for more specific problems such as convex-concave optimization when operator norm residual is the optimality measure. We further argue that, up to poly-logarithmic factors, this complexity is unimprovable in the monotone Lipschitz setting; i.e., the provided result is near-optimal.
Beyond the Golden Ratio for Variational Inequality Algorithms
Dec 28, 2022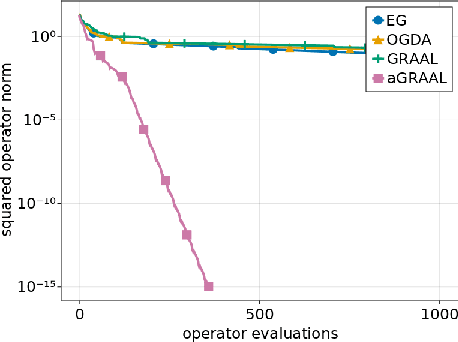
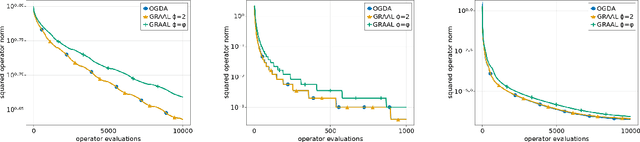
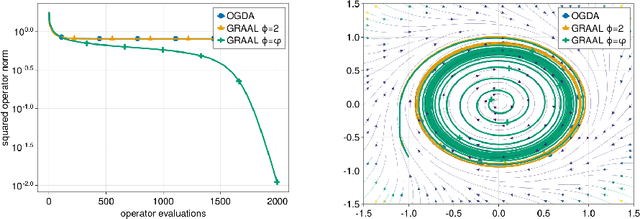
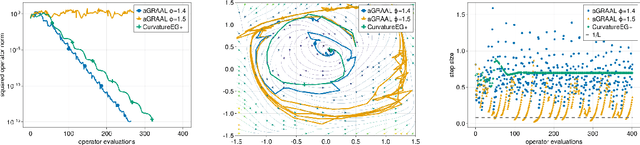
We improve the understanding of the $\textit{golden ratio algorithm}$, which solves monotone variational inequalities (VI) and convex-concave min-max problems via the distinctive feature of adapting the step sizes to the local Lipschitz constants. Adaptive step sizes not only eliminate the need to pick hyperparameters, but they also remove the necessity of global Lipschitz continuity and can increase from one iteration to the next. We first establish the equivalence of this algorithm with popular VI methods such as reflected gradient, Popov or optimistic gradient descent-ascent in the unconstrained case with constant step sizes. We then move on to the constrained setting and introduce a new analysis that allows to use larger step sizes, to complete the bridge between the golden ratio algorithm and the existing algorithms in the literature. Doing so, we actually eliminate the link between the golden ratio $\frac{1+\sqrt{5}}{2}$ and the algorithm. Moreover, we improve the adaptive version of the algorithm, first by removing the maximum step size hyperparameter (an artifact from the analysis) to improve the complexity bound, and second by adjusting it to nonmonotone problems with weak Minty solutions, with superior empirical performance.
Convergence and Complexity of Stochastic Subgradient Methods with Dependent Data for Nonconvex Optimization
Mar 29, 2022
We show that under a general dependent data sampling scheme, the classical stochastic projected and proximal subgradient methods for weakly convex functions have worst-case rate of convergence $\tilde{O}(n^{-1/4})$ and complexity $\tilde{O}(\varepsilon^{-4})$ for achieving an $\varepsilon$-near stationary point in terms of the norm of the gradient of Moreau envelope. While classical convergence guarantee requires i.i.d. data sampling from the target distribution, we only require a mild mixing condition of the conditional distribution, which holds for a wide class of Markov chain sampling algorithms. This improves the existing complexity for the specific case of constrained smooth nonconvex optimization with dependent data from $\tilde{O}(\varepsilon^{-8})$ to $\tilde{O}(\varepsilon^{-4})$ with a significantly simpler analysis. We illustrate the generality of our approach by deriving convergence results with dependent data for adaptive stochastic subgradient algorithm AdaGrad and stochastic subgradient algorithm with heavy ball momentum. As an application, we obtain first online nonnegative matrix factorization algorithms for dependent data based on stochastic projected gradient methods with adaptive step sizes with optimal rate of convergence guarantee.