 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASTER: Agentic Scaling with Tool-integrated Extended Reasoning
Feb 01, 2026Reinforcement learning (RL) has emerged as a dominant paradigm for eliciting long-horizon reasoning in Large Language Models (LLMs). However, scaling Tool-Integrated Reasoning (TIR) via RL remains challenging due to interaction collapse: a pathological state where models fail to sustain multi-turn tool usage, instead degenerating into heavy internal reasoning with only trivial, post-hoc code verification. We systematically study three questions: (i) how cold-start SFT induces an agentic, tool-using behavioral prior, (ii) how the interaction density of cold-start trajectories shapes exploration and downstream RL outcomes, and (iii) how the RL interaction budget affects learning dynamics and generalization under varying inference-time budgets. We then introduce ASTER (Agentic Scaling with Tool-integrated Extended Reasoning), a framework that circumvents this collapse through a targeted cold-start strategy prioritizing interaction-dense trajectories. We find that a small expert cold-start set of just 4K interaction-dense trajectories yields the strongest downstream performance, establishing a robust prior that enables superior exploration during extended RL training. Extensive evaluations demonstrate that ASTER-4B achieves state-of-the-art results on competitive mathematical benchmarks, reaching 90.0% on AIME 2025, surpassing leading frontier open-source models, including DeepSeek-V3.2-Exp.
Multi-agent In-context Coordination via Decentralized Memory Retrieval
Nov 13, 2025



Large transformer models, trained on diverse datasets, have demonstrated impressive few-shot performance on previously unseen tasks without requiring parameter updates. This capability has also been explored in Reinforcement Learning (RL), where agents interact with the environment to retrieve context and maximize cumulative rewards, showcasing strong adaptability in complex settings. However, in cooperative Multi-Agent Reinforcement Learning (MARL), where agents must coordinate toward a shared goal, decentralized policy deployment can lead to mismatches in task alignment and reward assignment, limiting the efficiency of policy adaptation. To address this challenge, we introduce Multi-agent In-context Coordination via Decentralized Memory Retrieval (MAICC), a novel approach designed to enhance coordination by fast adaptation. Our method involves training a centralized embedding model to capture fine-grained trajectory representations, followed by decentralized models that approximate the centralized one to obtain team-level task information. Based on the learned embeddings, relevant trajectories are retrieved as context, which, combined with the agents' current sub-trajectories, inform decision-making. During decentralized execution, we introduce a novel memory mechanism that effectively balances test-time online data with offline memory. Based on the constructed memory, we propose a hybrid utility score that incorporates both individual- and team-level returns, ensuring credit assignment across agents. Extensive experiments on cooperative MARL benchmarks, including Level-Based Foraging (LBF) and SMAC (v1/v2), show that MAICC enables faster adaptation to unseen tasks compared to existing methods. Code is available at https://github.com/LAMDA-RL/MAICC.
Reward Models in Deep Reinforcement Learning: A Survey
Jun 18, 2025In reinforcement learning (RL), agents continually interact with the environment and use the feedback to refine their behavior. To guide policy optimization, reward models are introduced as proxies of the desired objectives, such that when the agent maximizes the accumulated reward, it also fulfills the task designer's intentions. Recently, significant attention from both academic and industrial researchers has focused on developing reward models that not only align closely with the true objectives but also facilitate policy optimization. In this survey, we provide a comprehensive review of reward modeling techniques within the deep RL literature. We begin by outlining the background and preliminaries in reward modeling. Next, we present an overview of recent reward modeling approaches, categorizing them based on the source, the mechanism, and the learning paradigm. Building on this understanding, we discuss various applications of these reward modeling techniques and review methods for evaluating reward models. Finally, we conclude by highlighting promising research directions in reward modeling. Altogether, this survey includes both established and emerging methods, filling the vacancy of a systematic review of reward models in current literature.
Unleashing Humanoid Reaching Potential via Real-world-Ready Skill Space
May 16, 2025Humans possess a large reachable space in the 3D world, enabling interaction with objects at varying heights and distances. However, realizing such large-space reaching on humanoids is a complex whole-body control problem and requires the robot to master diverse skills simultaneously-including base positioning and reorientation, height and body posture adjustments, and end-effector pose control. Learning from scratch often leads to optimization difficulty and poor sim2real transferability. To address this challenge, we propose Real-world-Ready Skill Space (R2S2). Our approach begins with a carefully designed skill library consisting of real-world-ready primitive skills. We ensure optimal performance and robust sim2real transfer through individual skill tuning and sim2real evaluation. These skills are then ensembled into a unified latent space, serving as a structured prior that helps task execution in an efficient and sim2real transferable manner. A high-level planner, trained to sample skills from this space, enables the robot to accomplish real-world goal-reaching tasks. We demonstrate zero-shot sim2real transfer and validate R2S2 in multiple challenging goal-reaching scenarios.
Behavior-Regularized Diffusion Policy Optimization for Offline Reinforcement Learning
Feb 07, 2025
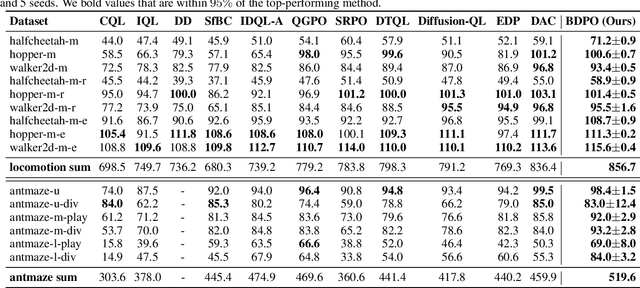
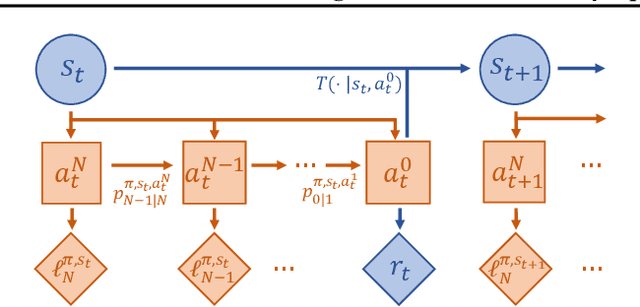
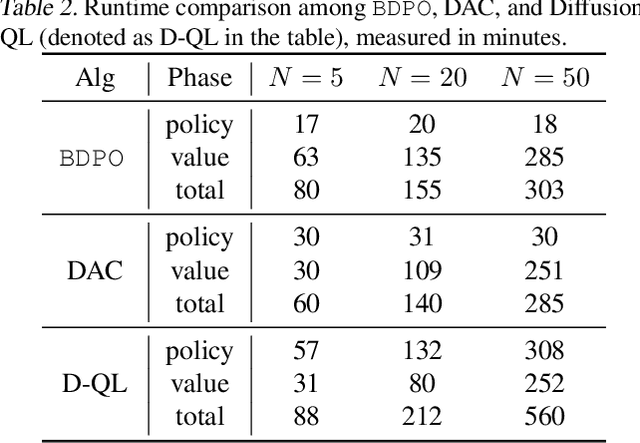
The primary focus of offline reinforcement learning (RL) is to manage the risk of hazardous exploitation of out-of-distribution actions. An effective approach to achieve this goal is through behavior regularization, which augments conventional RL objectives by incorporating constraints that enforce the policy to remain close to the behavior policy. Nevertheless, existing literature on behavior-regularized RL primarily focuses on explicit policy parameterizations, such as Gaussian policies. Consequently, it remains unclear how to extend this framework to more advanced policy parameterizations, such as diffusion models. In this paper, we introduce BDPO, a principled behavior-regularized RL framework tailored for diffusion-based policies, thereby combining the expressive power of diffusion policies and the robustness provided by regularization. The key ingredient of our method is to calculate the Kullback-Leibler (KL) regularization analytically as the accumulated discrepancies in reverse-time transition kernels along the diffusion trajectory. By integrating the regularization, we develop an efficient two-time-scale actor-critic RL algorithm that produces the optimal policy while respecting the behavior constraint. Comprehensive evaluations conducted on synthetic 2D tasks and continuous control tasks from the D4RL benchmark validate its effectiveness and superior performance.
Stable Continual Reinforcement Learning via Diffusion-based Trajectory Replay
Nov 16, 2024



Given the inherent non-stationarity prevalent in real-world applications, continual Reinforcement Learning (RL) aims to equip the agent with the capability to address a series of sequentially presented decision-making tasks. Within this problem setting, a pivotal challenge revolves around \textit{catastrophic forgetting} issue, wherein the agent is prone to effortlessly erode the decisional knowledge associated with past encountered tasks when learning the new one. In recent progresses, the \textit{generative replay} methods have showcased substantial potential by employing generative models to replay data distribution of past tasks. Compared to storing the data from past tasks directly, this category of methods circumvents the growing storage overhead and possible data privacy concerns. However, constrained by the expressive capacity of generative models, existing \textit{generative replay} methods face challenges in faithfully reconstructing the data distribution of past tasks, particularly in scenarios with a myriad of tasks or high-dimensional data. Inspired by the success of diffusion models in various generative tasks, this paper introduces a novel continual RL algorithm DISTR (Diffusion-based Trajectory Replay) that employs a diffusion model to memorize the high-return trajectory distribution of each encountered task and wakeups these distributions during the policy learning on new tasks. Besides, considering the impracticality of replaying all past data each time, a prioritization mechanism is proposed to prioritize the trajectory replay of pivotal tasks in our method. Empirical experiments on the popular continual RL benchmark \texttt{Continual World} demonstrate that our proposed method obtains a favorable balance between \textit{stability} and \textit{plasticity}, surpassing various existing continual RL baselines in average success rate.
ODRL: A Benchmark for Off-Dynamics Reinforcement Learning
Oct 28, 2024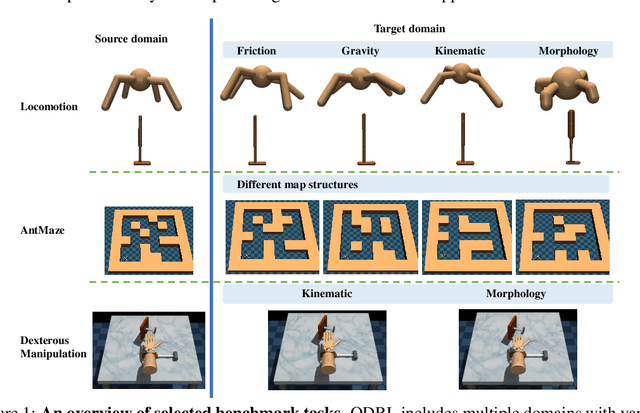

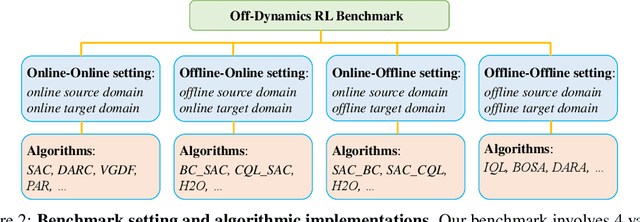

We consider off-dynamics reinforcement learning (RL) where one needs to transfer policies across different domains with dynamics mismatch. Despite the focus on developing dynamics-aware algorithms, this field is hindered due to the lack of a standard benchmark. To bridge this gap, we introduce ODRL, the first benchmark tailored for evaluating off-dynamics RL methods. ODRL contains four experimental settings where the source and target domains can be either online or offline, and provides diverse tasks and a broad spectrum of dynamics shifts, making it a reliable platform to comprehensively evaluate the agent's adaptation ability to the target domain. Furthermore, ODRL includes recent off-dynamics RL algorithms in a unified framework and introduces some extra baselines for different settings, all implemented in a single-file manner. To unpack the true adaptation capability of existing methods, we conduct extensive benchmarking experiments, which show that no method has universal advantages across varied dynamics shifts. We hope this benchmark can serve as a cornerstone for future research endeavors. Our code is publicly available at https://github.com/OffDynamicsRL/off-dynamics-rl.
Hindsight Preference Learning for Offline Preference-based Reinforcement Learning
Jul 05, 2024



Offline preference-based reinforcement learning (RL), which focuses on optimizing policies using human preferences between pairs of trajectory segments selected from an offline dataset, has emerged as a practical avenue for RL applications. Existing works rely on extracting step-wise reward signals from trajectory-wise preference annotations, assuming that preferences correlate with the cumulative Markovian rewards. However, such methods fail to capture the holistic perspective of data annotation: Humans often assess the desirability of a sequence of actions by considering the overall outcome rather than the immediate rewards. To address this challenge, we propose to model human preferences using rewards conditioned on future outcomes of the trajectory segments, i.e. the hindsight information. For downstream RL optimization, the reward of each step is calculated by marginalizing over possible future outcomes, the distribution of which is approximated by a variational auto-encoder trained using the offline dataset. Our proposed method, Hindsight Preference Learning (HPL), can facilitate credit assignment by taking full advantage of vast trajectory data available in massive unlabeled datasets. Comprehensive empirical studies demonstrate the benefits of HPL in delivering robust and advantageous rewards across various domains. Our code is publicly released at https://github.com/typoverflow/WiseRL.
Improving Sample Efficiency of Reinforcement Learning with Background Knowledge from Large Language Models
Jul 04, 2024



Low sample efficiency is an enduring challenge of reinforcement learning (RL). With the advent of versatile large language models (LLMs), recent works impart common-sense knowledge to accelerate policy learning for RL processes. However, we note that such guidance is often tailored for one specific task but loses generalizability. In this paper, we introduce a framework that harnesses LLMs to extract background knowledge of an environment, which contains general understandings of the entire environment, making various downstream RL tasks benefit from one-time knowledge representation. We ground LLMs by feeding a few pre-collected experiences and requesting them to delineate background knowledge of the environment. Afterward, we represent the output knowledge as potential functions for potential-based reward shaping, which has a good property for maintaining policy optimality from task rewards. We instantiate three variants to prompt LLMs for background knowledge, including writing code, annotating preferences, and assigning goals. Our experiments show that these methods achieve significant sample efficiency improvements in a spectrum of downstream tasks from Minigrid and Crafter domains.
Q-Adapter: Training Your LLM Adapter as a Residual Q-Function
Jul 04, 2024We consider the problem of adapting Large Language Models (LLMs) pre-trained with Reinforcement Learning from Human Feedback (RLHF) to downstream preference data. Naive approaches to achieve this could be supervised fine-tuning on preferred responses or reinforcement learning with a learned reward model. However, the LLM runs the risk of forgetting its initial knowledge as the fine-tuning progresses. To customize the LLM while preserving its existing capabilities, this paper proposes a novel method, named as Q-Adapter. We start by formalizing LLM adaptation as a problem of maximizing the linear combination of two rewards, one of which corresponds to the reward optimized by the pre-trained LLM and the other to the downstream preference data. Although both rewards are unknown, we show that this can be solved by directly learning a new module from the preference data that approximates the \emph{residual Q-function}. We consider this module to be an adapter because the original pre-trained LLM, together with it, can form the optimal customised LLM. Empirically, experiments on a range of domain-specific tasks and safety alignment tasks illustrate the superiority of Q-Adapter in both anti-forgetting and learning from new preferences.