 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\text{Alpha}^2$: Discovering Logical Formulaic Alphas using Deep Reinforcement Learning
Jun 26, 2024



Alphas are pivotal in providing signals for quantitative trading. The industry highly values the discovery of formulaic alphas for their interpretability and ease of analysis, compared with the expressive yet overfitting-prone black-box alphas. In this work, we focus on discovering formulaic alphas. Prior studies on automatically generating a collection of formulaic alphas were mostly based on genetic programming (GP), which is known to suffer from the problems of being sensitive to the initial population, converting to local optima, and slow computation speed. Recent efforts employing deep reinforcement learning (DRL) for alpha discovery have not fully addressed key practical considerations such as alpha correlations and validity, which are crucial for their effectiveness. In this work, we propose a novel framework for alpha discovery using DRL by formulating the alpha discovery process as program construction. Our agent, $\text{Alpha}^2$, assembles an alpha program optimized for an evaluation metric. A search algorithm guided by DRL navigates through the search space based on value estimates for potential alpha outcomes. The evaluation metric encourages both the performance and the diversity of alphas for a better final trading strategy. Our formulation of searching alphas also brings the advantage of pre-calculation dimensional analysis, ensuring the logical soundness of alphas, and pruning the vast search space to a large extent. Empirical experiments on real-world stock markets demonstrates $\text{Alpha}^2$'s capability to identify a diverse set of logical and effective alphas, which significantly improves the performance of the final trading strategy. The code of our method is available at https://github.com/x35f/alpha2.
Attention-based Transducer for Online Speech Recognition
May 18, 2020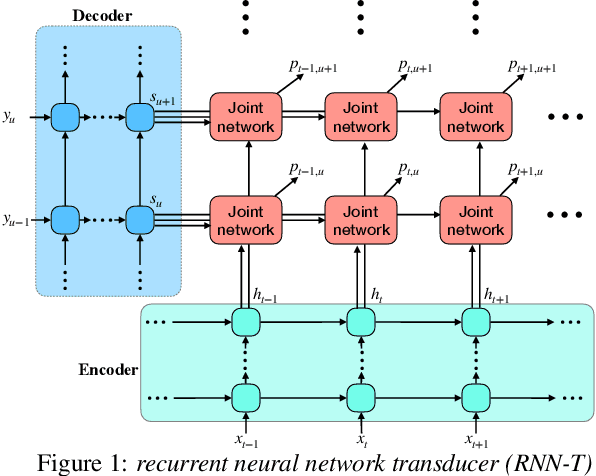
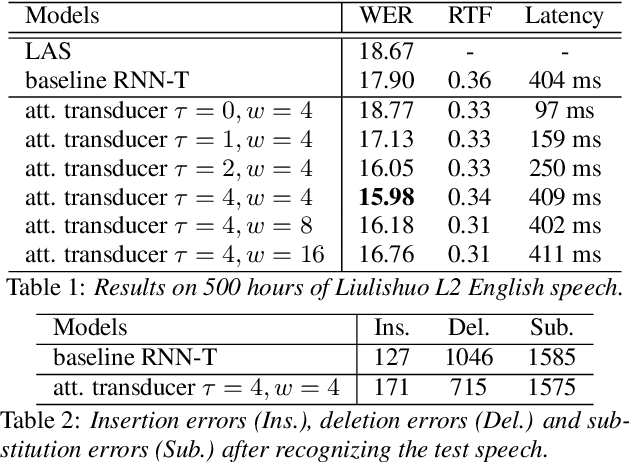


Recent studies reveal the potential of recurrent neural network transducer (RNN-T) for end-to-end (E2E) speech recognition. Among some most popular E2E systems including RNN-T, Attention Encoder-Decoder (AED), and Connectionist Temporal Classification (CTC), RNN-T has some clear advantages given that it supports streaming recognition and does not have frame-independency assumption. Although significant progresses have been made for RNN-T research, it is still facing performance challenges in terms of training speed and accuracy. We propose attention-based transducer with modification over RNN-T in two aspects. First, we introduce chunk-wise attention in the joint network. Second, self-attention is introduced in the encoder. Our proposed model outperforms RNN-T for both training speed and accuracy. For training, we achieves over 1.7x speedup. With 500 hours LAIX non-native English training data, attention-based transducer yields ~10.6% WER reduction over baseline RNN-T. Trained with full set of over 10K hours data, our final system achieves ~5.5% WER reduction over that trained with the best Kaldi TDNN-f recipe. After 8-bit weight quantization without WER degradation, RTF and latency drop to 0.34~0.36 and 268~409 milliseconds respectively on a single CPU core of a production server.
MIDI-Sandwich: Multi-model Multi-task Hierarchical Conditional VAE-GAN networks for Symbolic Single-track Music Generation
Jul 04, 2019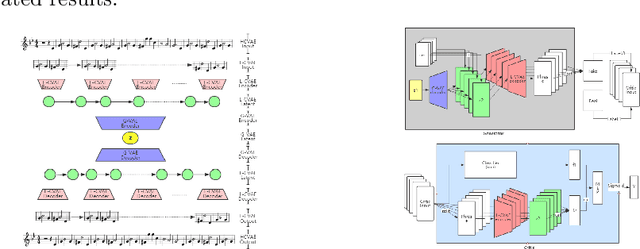
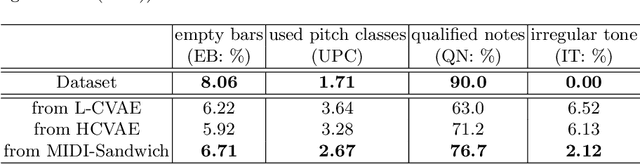
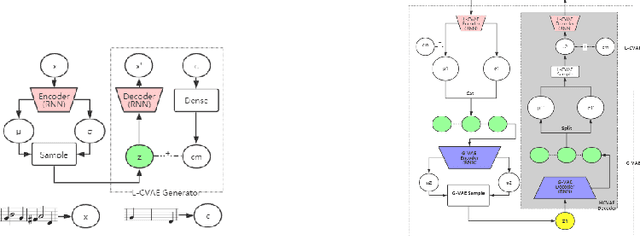
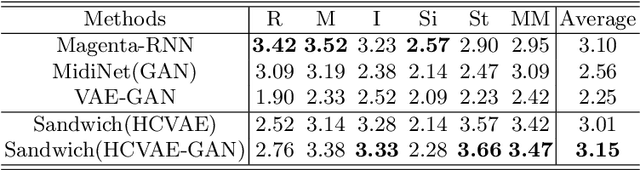
Most existing neural network models for music generation explore how to generate music bars, then directly splice the music bars into a song. However, these methods do not explore the relationship between the bars, and the connected song as a whole has no musical form structure and sense of musical direction. To address this issue, we propose a Multi-model Multi-task Hierarchical Conditional VAE-GAN (Variational Autoencoder-Generative adversarial networks) networks, named MIDI-Sandwich, which combines musical knowledge, such as musical form, tonic, and melodic motion. The MIDI-Sandwich has two submodels: Hierarchical Conditional Variational Autoencoder (HCVAE) and Hierarchical Conditional Generative Adversarial Network (HCGAN). The HCVAE uses hierarchical structure. The underlying layer of HCVAE uses Local Conditional Variational Autoencoder (L-CVAE) to generate a music bar which is pre-specified by the First and Last Notes (FLN). The upper layer of HCVAE uses Global Variational Autoencoder(G-VAE) to analyze the latent vector sequence generated by the L-CVAE encoder, to explore the musical relationship between the bars, and to produce the song pieced together by multiple music bars generated by the L-CVAE decoder, which makes the song both have musical structure and sense of direction. At the same time, the HCVAE shares a part of itself with the HCGAN to further improve the performance of the generated music. The MIDI-Sandwich is validated on the Nottingham dataset and is able to generate a single-track melody sequence (17x8 beats), which is superior to the length of most of the generated models (8 to 32 beats). Meanwhile, by referring to the experimental methods of many classical kinds of literature, the quality evaluation of the generated music is performed. The above experiments prove the validity of the model.
Attention-based sequence-to-sequence model for speech recognition: development of state-of-the-art system on LibriSpeech and its application to non-native English
Nov 05, 2018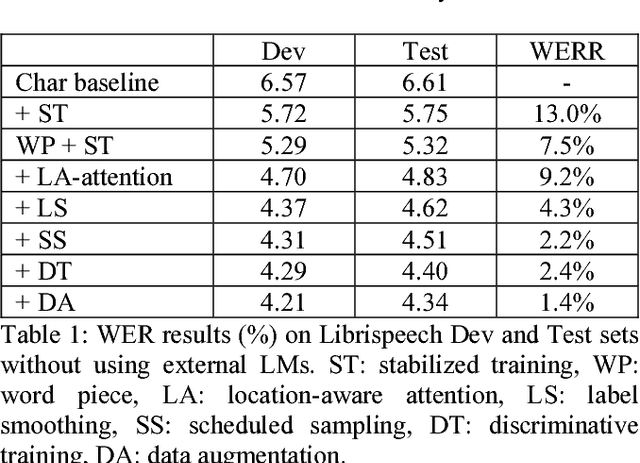
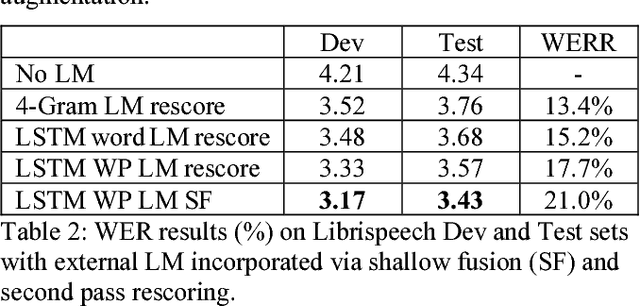
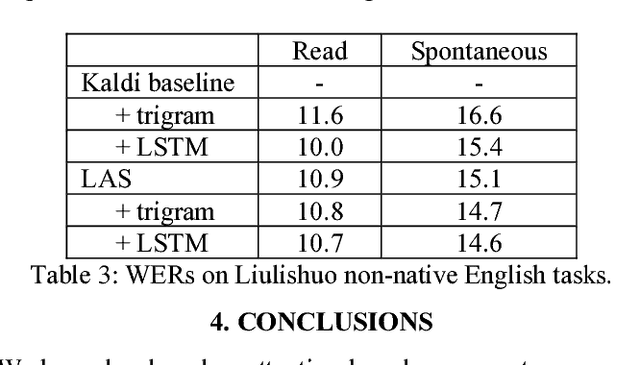
Recent research has shown that attention-based sequence-to-sequence models such as Listen, Attend, and Spell (LAS) yield comparable results to state-of-the-art ASR systems on various tasks. In this paper, we describe the development of such a system and demonstrate its performance on two tasks: first we achieve a new state-of-the-art word error rate of 3.43% on the test clean subset of LibriSpeech English data; second on non-native English speech, including both read speech and spontaneous speech, we obtain very competitive results compared to a conventional system built with the most updated Kaldi recipe.