 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-based Transducer for Online Speech Recognition
Paper and Code
May 18, 2020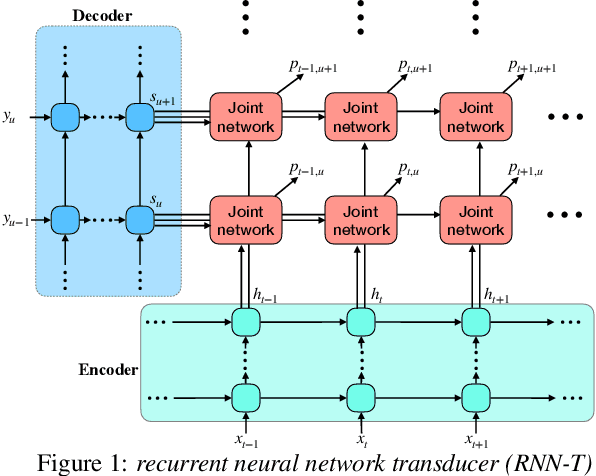
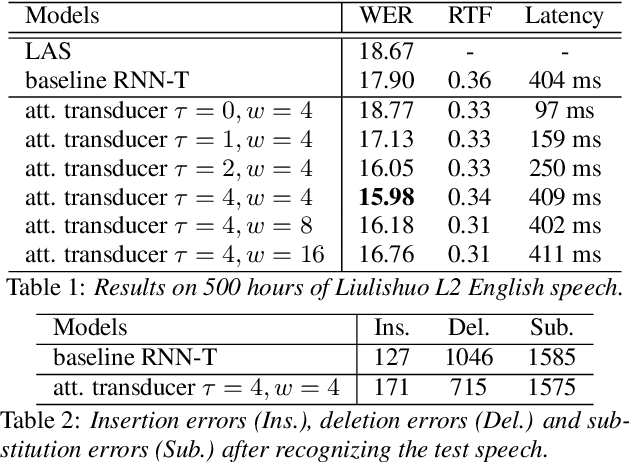


Recent studies reveal the potential of recurrent neural network transducer (RNN-T) for end-to-end (E2E) speech recognition. Among some most popular E2E systems including RNN-T, Attention Encoder-Decoder (AED), and Connectionist Temporal Classification (CTC), RNN-T has some clear advantages given that it supports streaming recognition and does not have frame-independency assumption. Although significant progresses have been made for RNN-T research, it is still facing performance challenges in terms of training speed and accuracy. We propose attention-based transducer with modification over RNN-T in two aspects. First, we introduce chunk-wise attention in the joint network. Second, self-attention is introduced in the encoder. Our proposed model outperforms RNN-T for both training speed and accuracy. For training, we achieves over 1.7x speedup. With 500 hours LAIX non-native English training data, attention-based transducer yields ~10.6% WER reduction over baseline RNN-T. Trained with full set of over 10K hours data, our final system achieves ~5.5% WER reduction over that trained with the best Kaldi TDNN-f recipe. After 8-bit weight quantization without WER degradation, RTF and latency drop to 0.34~0.36 and 268~409 milliseconds respectively on a single CPU core of a production server.