 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState-of-the-Art Speech Recognition Using Multi-Stream Self-Attention With Dilated 1D Convolutions
Oct 01, 2019


Self-attention has been a huge success for many downstream tasks in NLP, which led to exploration of applying self-attention to speech problems as well. The efficacy of self-attention in speech applications, however, seems not fully blown yet since it is challenging to handle highly correlated speech frames in the context of self-attention. In this paper we propose a new neural network model architecture, namely multi-stream self-attention, to address the issue thus make the self-attention mechanism more effective for speech recognition. The proposed model architecture consists of parallel streams of self-attention encoders, and each stream has layers of 1D convolutions with dilated kernels whose dilation rates are unique given stream, followed by a self-attention layer. The self-attention mechanism in each stream pays attention to only one resolution of input speech frames and the attentive computation can be more efficient. In a later stage, outputs from all the streams are concatenated then linearly projected to the final embedding. By stacking the proposed multi-stream self-attention encoder blocks and rescoring the resultant lattices with neural network language models, we achieve the word error rate of 2.2% on the test-clean dataset of the LibriSpeech corpus, the best number reported thus far on the dataset.
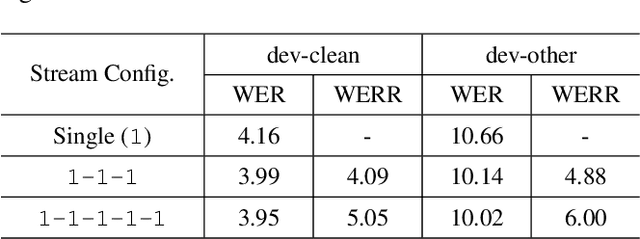
Attention-based sequence-to-sequence model for speech recognition: development of state-of-the-art system on LibriSpeech and its application to non-native English
Nov 05, 2018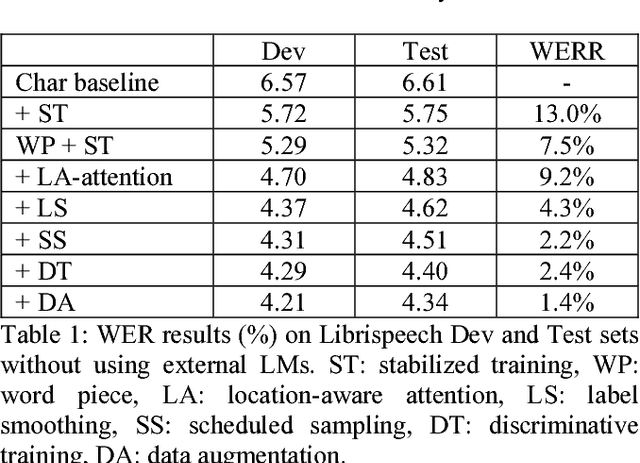
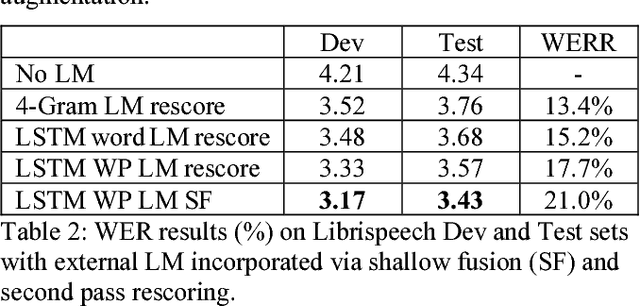
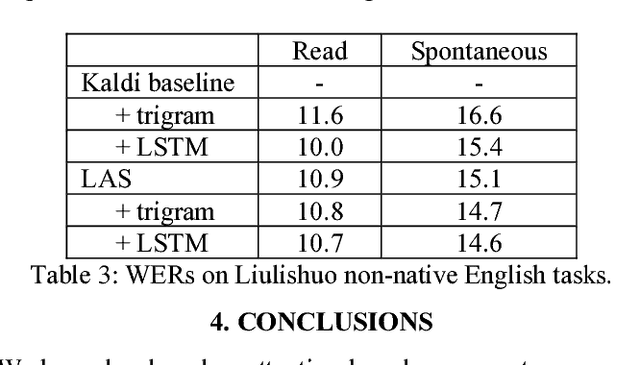
Recent research has shown that attention-based sequence-to-sequence models such as Listen, Attend, and Spell (LAS) yield comparable results to state-of-the-art ASR systems on various tasks. In this paper, we describe the development of such a system and demonstrate its performance on two tasks: first we achieve a new state-of-the-art word error rate of 3.43% on the test clean subset of LibriSpeech English data; second on non-native English speech, including both read speech and spontaneous speech, we obtain very competitive results compared to a conventional system built with the most updated Kaldi recipe.