 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Gaussian Splatting SLAM
May 15, 2025The recently developed Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have shown encouraging and impressive results for visual SLAM. However, most representative methods require RGBD sensors and are only available for indoor environments. The robustness of reconstruction in large-scale outdoor scenarios remains unexplored. This paper introduces a large-scale 3DGS-based visual SLAM with stereo cameras, termed LSG-SLAM. The proposed LSG-SLAM employs a multi-modality strategy to estimate prior poses under large view changes. In tracking, we introduce feature-alignment warping constraints to alleviate the adverse effects of appearance similarity in rendering losses. For the scalability of large-scale scenarios, we introduce continuous Gaussian Splatting submaps to tackle unbounded scenes with limited memory. Loops are detected between GS submaps by place recognition and the relative pose between looped keyframes is optimized utilizing rendering and feature warping losses. After the global optimization of camera poses and Gaussian points, a structure refinement module enhances the reconstruction quality. With extensive evaluations on the EuRoc and KITTI datasets, LSG-SLAM achieves superior performance over existing Neural, 3DGS-based, and even traditional approaches. Project page: https://lsg-slam.github.io.
Behavior-Regularized Diffusion Policy Optimization for Offline Reinforcement Learning
Feb 07, 2025
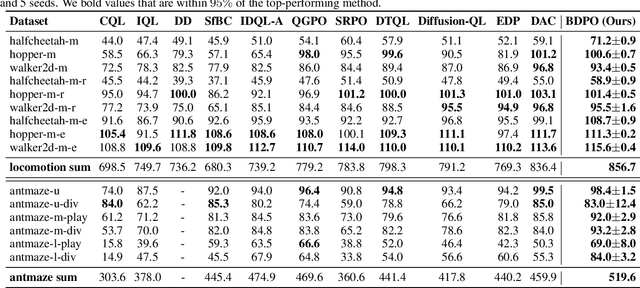
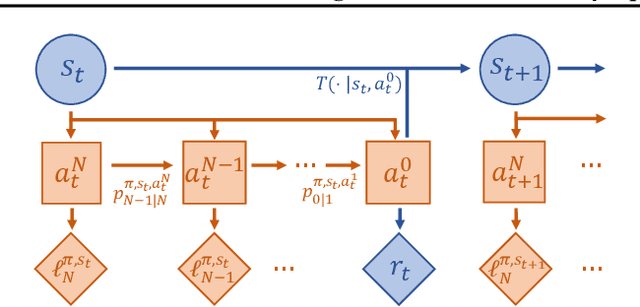
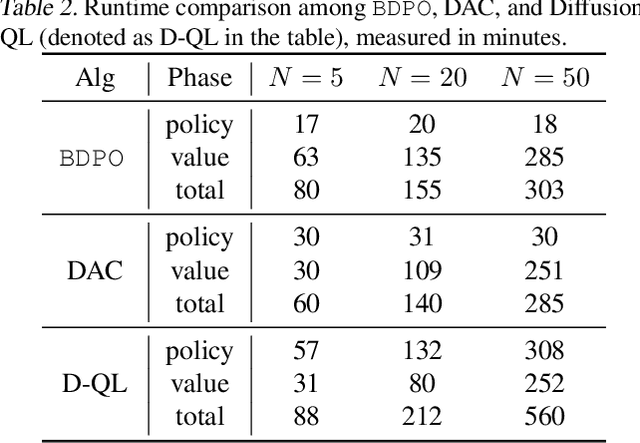
The primary focus of offline reinforcement learning (RL) is to manage the risk of hazardous exploitation of out-of-distribution actions. An effective approach to achieve this goal is through behavior regularization, which augments conventional RL objectives by incorporating constraints that enforce the policy to remain close to the behavior policy. Nevertheless, existing literature on behavior-regularized RL primarily focuses on explicit policy parameterizations, such as Gaussian policies. Consequently, it remains unclear how to extend this framework to more advanced policy parameterizations, such as diffusion models. In this paper, we introduce BDPO, a principled behavior-regularized RL framework tailored for diffusion-based policies, thereby combining the expressive power of diffusion policies and the robustness provided by regularization. The key ingredient of our method is to calculate the Kullback-Leibler (KL) regularization analytically as the accumulated discrepancies in reverse-time transition kernels along the diffusion trajectory. By integrating the regularization, we develop an efficient two-time-scale actor-critic RL algorithm that produces the optimal policy while respecting the behavior constraint. Comprehensive evaluations conducted on synthetic 2D tasks and continuous control tasks from the D4RL benchmark validate its effectiveness and superior performance.
MM-Gaussian: 3D Gaussian-based Multi-modal Fusion for Localization and Reconstruction in Unbounded Scenes
Apr 05, 2024



Localization and mapping are critical tasks for various applications such as autonomous vehicles and robotics. The challenges posed by outdoor environments present particular complexities due to their unbounded characteristics. In this work, we present MM-Gaussian, a LiDAR-camera multi-modal fusion system for localization and mapping in unbounded scenes. Our approach is inspired by the recently developed 3D Gaussians, which demonstrate remarkable capabilities in achieving high rendering quality and fast rendering speed. Specifically, our system fully utilizes the geometric structure information provided by solid-state LiDAR to address the problem of inaccurate depth encountered when relying solely on visual solutions in unbounded, outdoor scenarios. Additionally, we utilize 3D Gaussian point clouds, with the assistance of pixel-level gradient descent, to fully exploit the color information in photos, thereby achieving realistic rendering effects. To further bolster the robustness of our system, we designed a relocalization module, which assists in returning to the correct trajectory in the event of a localization failure. Experiments conducted in multiple scenarios demonstrate the effectiveness of our method.
Reinforced In-Context Black-Box Optimization
Feb 27, 2024



Black-Box Optimization (BBO) has found successful applications in many fields of science and engineering. Recently, there has been a growing interest in meta-learning particular components of BBO algorithms to speed up optimization and get rid of tedious hand-crafted heuristics. As an extension, learning the entire algorithm from data requires the least labor from experts and can provide the most flexibility. In this paper, we propose RIBBO, a method to reinforce-learn a BBO algorithm from offline data in an end-to-end fashion. RIBBO employs expressive sequence models to learn the optimization histories produced by multiple behavior algorithms and tasks, leveraging the in-context learning ability of large models to extract task information and make decisions accordingly. Central to our method is to augment the optimization histories with regret-to-go tokens, which are designed to represent the performance of an algorithm based on cumulative regret of the histories. The integration of regret-to-go tokens enables RIBBO to automatically generate sequences of query points that satisfy the user-desired regret, which is verified by its universally good empirical performance on diverse problems, including BBOB functions, hyper-parameter optimization and robot control problems.
ACT: Empowering Decision Transformer with Dynamic Programming via Advantage Conditioning
Sep 12, 2023Decision Transformer (DT), which employs expressive sequence modeling techniques to perform action generation, has emerged as a promising approach to offline policy optimization. However, DT generates actions conditioned on a desired future return, which is known to bear some weaknesses such as the susceptibility to environmental stochasticity. To overcome DT's weaknesses, we propose to empower DT with dynamic programming. Our method comprises three steps. First, we employ in-sample value iteration to obtain approximated value functions, which involves dynamic programming over the MDP structure. Second, we evaluate action quality in context with estimated advantages. We introduce two types of advantage estimators, IAE and GAE, which are suitable for different tasks. Third, we train an Advantage-Conditioned Transformer (ACT) to generate actions conditioned on the estimated advantages. Finally, during testing, ACT generates actions conditioned on a desired advantage. Our evaluation results validate that, by leveraging the power of dynamic programming, ACT demonstrates effective trajectory stitching and robust action generation in spite of the environmental stochasticity, outperforming baseline methods across various benchmarks. Additionally, we conduct an in-depth analysis of ACT's various design choices through ablation studies.