 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-H-Embodiment: A Large-Scale Dataset for Enabling Foundation Models in Medical Robotics
Apr 22, 2026Autonomous medical robots hold promise to improve patient outcomes, reduce provider workload, democratize access to care, and enable superhuman precision. However, autonomous medical robotics has been limited by a fundamental data problem: existing medical robotic datasets are small, single-embodiment, and rarely shared openly, restricting the development of foundation models that the field needs to advance. We introduce Open-H-Embodiment, the largest open dataset of medical robotic video with synchronized kinematics to date, spanning more than 49 institutions and multiple robotic platforms including the CMR Versius, Intuitive Surgical's da Vinci, da Vinci Research Kit (dVRK), Rob Surgical BiTrack, Virtual Incision's MIRA, Moon Surgical Maestro, and a variety of custom systems, spanning surgical manipulation, robotic ultrasound, and endoscopy procedures. We demonstrate the research enabled by this dataset through two foundation models. GR00T-H is the first open foundation vision-language-action model for medical robotics, which is the only evaluated model to achieve full end-to-end task completion on a structured suturing benchmark (25% of trials vs. 0% for all others) and achieves 64% average success across a 29-step ex vivo suturing sequence. We also train Cosmos-H-Surgical-Simulator, the first action-conditioned world model to enable multi-embodiment surgical simulation from a single checkpoint, spanning nine robotic platforms and supporting in silico policy evaluation and synthetic data generation for the medical domain. These results suggest that open, large-scale medical robot data collection can serve as critical infrastructure for the research community, enabling advances in robot learning, world modeling, and beyond.
Learning Surgical Robotic Manipulation with 3D Spatial Priors
Mar 04, 2026Achieving 3D spatial awareness is crucial for surgical robotic manipulation, where precise and delicate operations are required. Existing methods either explicitly reconstruct the surgical scene prior to manipulation, or enhance multi-view features by adding wrist-mounted cameras to supplement the default stereo endoscopes. However, both paradigms suffer from notable limitations: the former easily leads to error accumulation and prevents end-to-end optimization due to its multi-stage nature, while the latter is rarely adopted in clinical practice since wrist-mounted cameras can interfere with the motion of surgical robot arms. In this work, we introduce the Spatial Surgical Transformer (SST), an end-to-end visuomotor policy that empowers surgical robots with 3D spatial awareness by directly exploring 3D spatial cues embedded in endoscopic images. First, we build Surgical3D, a large-scale photorealistic dataset containing 30K stereo endoscopic image pairs with accurate 3D geometry, addressing the scarcity of 3D data in surgical scenes. Based on Surgical3D, we finetune a powerful geometric transformer to extract robust 3D latent representations from stereo endoscopes images. These representations are then seamlessly aligned with the robot's action space via a lightweight multi-level spatial feature connector (MSFC), all within an endoscope-centric coordinate frame. Extensive real-robot experiments demonstrate that SST achieves state-of-the-art performance and strong spatial generalization on complex surgical tasks such as knot tying and ex-vivo organ dissection, representing a significant step toward practical clinical deployment. The dataset and code will be released.
SpatialSplat: Efficient Semantic 3D from Sparse Unposed Images
May 29, 2025A major breakthrough in 3D reconstruction is the feedforward paradigm to generate pixel-wise 3D points or Gaussian primitives from sparse, unposed images. To further incorporate semantics while avoiding the significant memory and storage costs of high-dimensional semantic features, existing methods extend this paradigm by associating each primitive with a compressed semantic feature vector. However, these methods have two major limitations: (a) the naively compressed feature compromises expressiveness, affecting the model's ability to capture fine-grained semantics, and (b) the pixel-wise primitive prediction introduces redundancy in overlapping areas, causing unnecessary memory overhead. To this end, we introduce \textbf{SpatialSplat}, a feedforward framework that produces redundancy-aware Gaussians and capitalizes on a dual-field semantic representation. Particularly, with the insight that primitives within the same instance exhibit high semantic consistency, we decompose the semantic representation into a coarse feature field that encodes uncompressed semantics with minimal primitives, and a fine-grained yet low-dimensional feature field that captures detailed inter-instance relationships. Moreover, we propose a selective Gaussian mechanism, which retains only essential Gaussians in the scene, effectively eliminating redundant primitives. Our proposed Spatialsplat learns accurate semantic information and detailed instances prior with more compact 3D Gaussians, making semantic 3D reconstruction more applicable. We conduct extensive experiments to evaluate our method, demonstrating a remarkable 60\% reduction in scene representation parameters while achieving superior performance over state-of-the-art methods. The code will be made available for future investigation.
Uncertainty Unveiled: Can Exposure to More In-context Examples Mitigate Uncertainty for Large Language Models?
May 27, 2025Recent advances in handling long sequences have facilitated the exploration of long-context in-context learning (ICL). While much of the existing research emphasizes performance improvements driven by additional in-context examples, the influence on the trustworthiness of generated responses remains underexplored. This paper addresses this gap by investigating how increased examples influence predictive uncertainty, an essential aspect in trustworthiness. We begin by systematically quantifying the uncertainty of ICL with varying shot counts, analyzing the impact of example quantity. Through uncertainty decomposition, we introduce a novel perspective on performance enhancement, with a focus on epistemic uncertainty (EU). Our results reveal that additional examples reduce total uncertainty in both simple and complex tasks by injecting task-specific knowledge, thereby diminishing EU and enhancing performance. For complex tasks, these advantages emerge only after addressing the increased noise and uncertainty associated with longer inputs. Finally, we explore the evolution of internal confidence across layers, unveiling the mechanisms driving the reduction in uncertainty.
ElectricSight: 3D Hazard Monitoring for Power Lines Using Low-Cost Sensors
May 10, 2025Protecting power transmission lines from potential hazards involves critical tasks, one of which is the accurate measurement of distances between power lines and potential threats, such as large cranes. The challenge with this task is that the current sensor-based methods face challenges in balancing accuracy and cost in distance measurement. A common practice is to install cameras on transmission towers, which, however, struggle to measure true 3D distances due to the lack of depth information. Although 3D lasers can provide accurate depth data, their high cost makes large-scale deployment impractical. To address this challenge, we present ElectricSight, a system designed for 3D distance measurement and monitoring of potential hazards to power transmission lines. This work's key innovations lie in both the overall system framework and a monocular depth estimation method. Specifically, the system framework combines real-time images with environmental point cloud priors, enabling cost-effective and precise 3D distance measurements. As a core component of the system, the monocular depth estimation method enhances the performance by integrating 3D point cloud data into image-based estimates, improving both the accuracy and reliability of the system. To assess ElectricSight's performance, we conducted tests with data from a real-world power transmission scenario. The experimental results demonstrate that ElectricSight achieves an average accuracy of 1.08 m for distance measurements and an early warning accuracy of 92%.
Building-Guided Pseudo-Label Learning for Cross-Modal Building Damage Mapping
May 08, 2025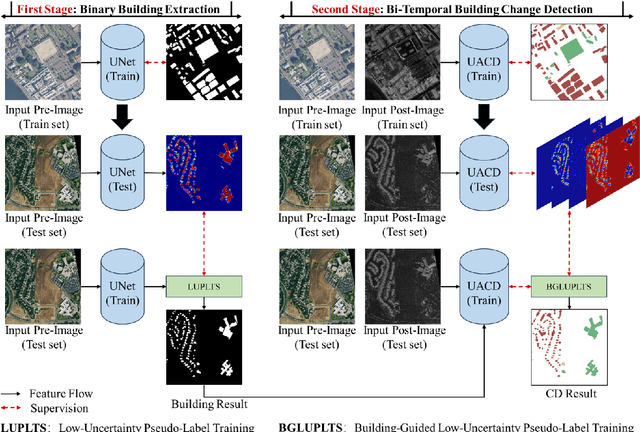
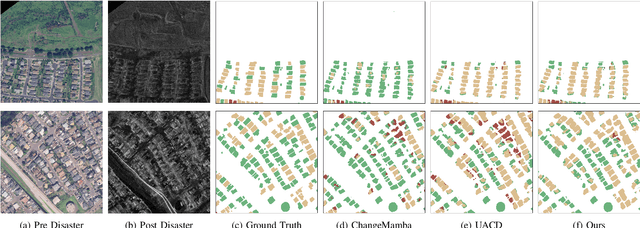

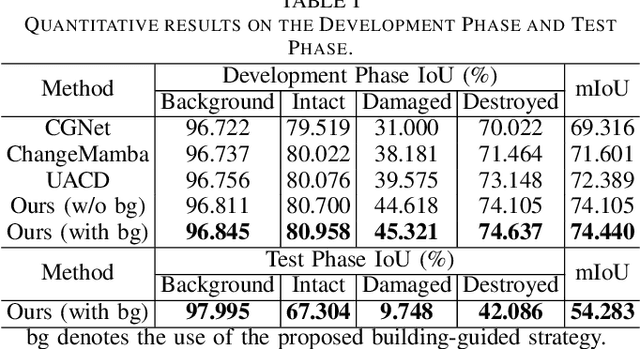
Accurate building damage assessment using bi-temporal multi-modal remote sensing images is essential for effective disaster response and recovery planning. This study proposes a novel Building-Guided Pseudo-Label Learning Framework to address the challenges of mapping building damage from pre-disaster optical and post-disaster SAR images. First, we train a series of building extraction models using pre-disaster optical images and building labels. To enhance building segmentation, we employ multi-model fusion and test-time augmentation strategies to generate pseudo-probabilities, followed by a low-uncertainty pseudo-label training method for further refinement. Next, a change detection model is trained on bi-temporal cross-modal images and damaged building labels. To improve damage classification accuracy, we introduce a building-guided low-uncertainty pseudo-label refinement strategy, which leverages building priors from the previous step to guide pseudo-label generation for damaged buildings, reducing uncertainty and enhancing reliability. Experimental results on the 2025 IEEE GRSS Data Fusion Contest dataset demonstrate the effectiveness of our approach, which achieved the highest mIoU score (54.28%) and secured first place in the competition.
Topology-aware Mamba for Crack Segmentation in Structures
Oct 25, 2024
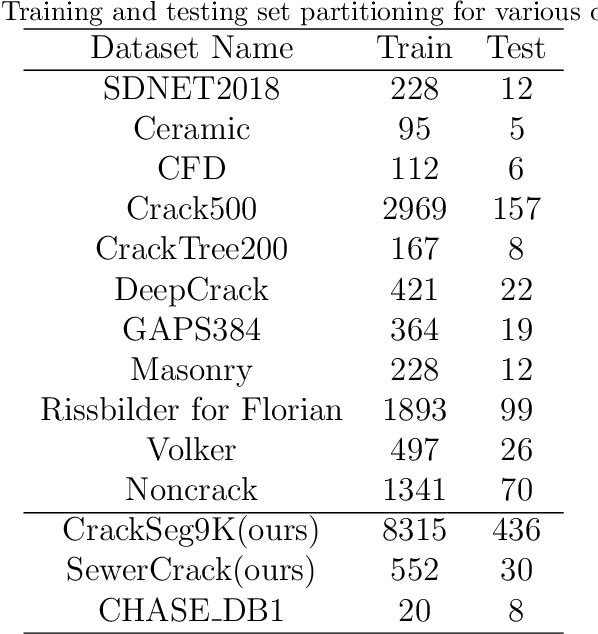
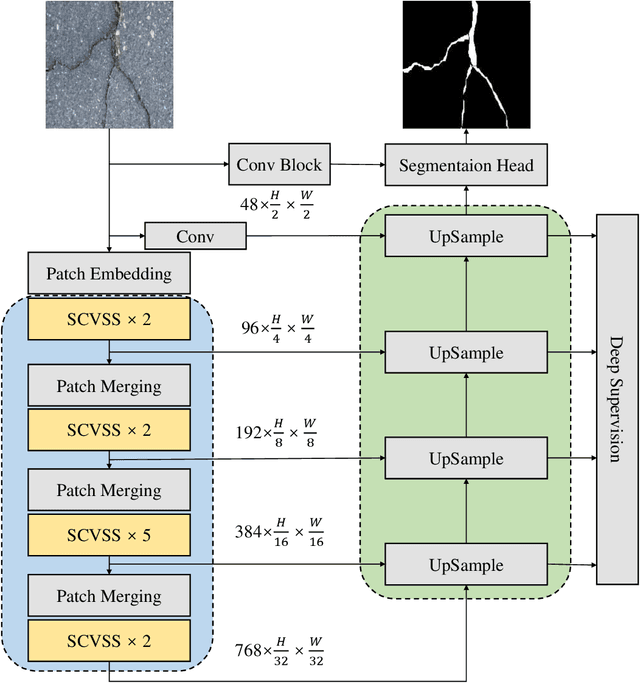
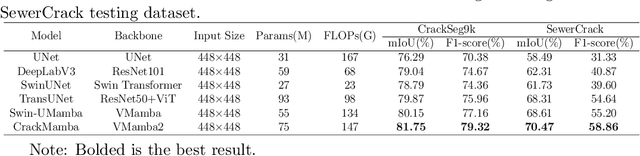
CrackMamba, a Mamba-based model, is designed for efficient and accurate crack segmentation for monitoring the structural health of infrastructure. Traditional Convolutional Neural Network (CNN) models struggle with limited receptive fields, and while Vision Transformers (ViT) improve segmentation accuracy, they are computationally intensive. CrackMamba addresses these challenges by utilizing the VMambaV2 with pre-trained ImageNet-1k weights as the encoder and a newly designed decoder for better performance. To handle the random and complex nature of crack development, a Snake Scan module is proposed to reshape crack feature sequences, enhancing feature extraction. Additionally, the three-branch Snake Conv VSS (SCVSS) block is proposed to target cracks more effectively. Experiments show that CrackMamba achieves state-of-the-art (SOTA) performance on the CrackSeg9k and SewerCrack datasets, and demonstrates competitive performance on the retinal vessel segmentation dataset CHASE\underline{~}DB1, highlighting its generalization capability. The code is publicly available at: {https://github.com/shengyu27/CrackMamba.}
MSGField: A Unified Scene Representation Integrating Motion, Semantics, and Geometry for Robotic Manipulation
Oct 21, 2024Combining accurate geometry with rich semantics has been proven to be highly effective for language-guided robotic manipulation. Existing methods for dynamic scenes either fail to update in real-time or rely on additional depth sensors for simple scene editing, limiting their applicability in real-world. In this paper, we introduce MSGField, a representation that uses a collection of 2D Gaussians for high-quality reconstruction, further enhanced with attributes to encode semantic and motion information. Specially, we represent the motion field compactly by decomposing each primitive's motion into a combination of a limited set of motion bases. Leveraging the differentiable real-time rendering of Gaussian splatting, we can quickly optimize object motion, even for complex non-rigid motions, with image supervision from only two camera views. Additionally, we designed a pipeline that utilizes object priors to efficiently obtain well-defined semantics. In our challenging dataset, which includes flexible and extremely small objects, our method achieve a success rate of 79.2% in static and 63.3% in dynamic environments for language-guided manipulation. For specified object grasping, we achieve a success rate of 90%, on par with point cloud-based methods. Code and dataset will be released at:https://shengyu724.github.io/MSGField.github.io.
Unveiling Factual Recall Behaviors of Large Language Models through Knowledge Neurons
Aug 06, 2024In this paper, we investigate whether Large Language Models (LLMs) actively recall or retrieve their internal repositories of factual knowledge when faced with reasoning tasks. Through an analysis of LLMs' internal factual recall at each reasoning step via Knowledge Neurons, we reveal that LLMs fail to harness the critical factual associations under certain circumstances. Instead, they tend to opt for alternative, shortcut-like pathways to answer reasoning questions. By manually manipulating the recall process of parametric knowledge in LLMs, we demonstrate that enhancing this recall process directly improves reasoning performance whereas suppressing it leads to notable degradation. Furthermore, we assess the effect of Chain-of-Thought (CoT) prompting, a powerful technique for addressing complex reasoning tasks. Our findings indicate that CoT can intensify the recall of factual knowledge by encouraging LLMs to engage in orderly and reliable reasoning. Furthermore, we explored how contextual conflicts affect the retrieval of facts during the reasoning process to gain a comprehensive understanding of the factual recall behaviors of LLMs. Code and data will be available soon.
Multi-label Sewer Pipe Defect Recognition with Mask Attention Feature Enhancement and Label Correlation Learning
Aug 01, 2024



The coexistence of multiple defect categories as well as the substantial class imbalance problem significantly impair the detection of sewer pipeline defects. To solve this problem, a multi-label pipe defect recognition method is proposed based on mask attention guided feature enhancement and label correlation learning. The proposed method can achieve current approximate state-of-the-art classification performance using just 1/16 of the Sewer-ML training dataset and exceeds the current best method by 11.87\% in terms of F2 metric on the full dataset, while also proving the superiority of the model. The major contribution of this study is the development of a more efficient model for identifying and locating multiple defects in sewer pipe images for a more accurate sewer pipeline condition assessment. Moreover, by employing class activation maps, our method can accurately pinpoint multiple defect categories in the image which demonstrates a strong model interpretability. Our code is available at \href{https://github.com/shengyu27/MA-Q2L}{\textcolor{black}{https://github.com/shengyu27/MA-Q2L.}