 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Dynamics in Continual Pre-Training for Large Language Models
May 12, 2025Continual Pre-Training (CPT) has become a popular and effective method to apply strong foundation models to specific downstream tasks. In this work, we explore the learning dynamics throughout the CPT process for large language models. We specifically focus on how general and downstream domain performance evolves at each training step, with domain performance measured via validation losses. We have observed that the CPT loss curve fundamentally characterizes the transition from one curve to another hidden curve, and could be described by decoupling the effects of distribution shift and learning rate annealing. We derive a CPT scaling law that combines the two factors, enabling the prediction of loss at any (continual) training steps and across learning rate schedules (LRS) in CPT. Our formulation presents a comprehensive understanding of several critical factors in CPT, including loss potential, peak learning rate, training steps, replay ratio, etc. Moreover, our approach can be adapted to customize training hyper-parameters to different CPT goals such as balancing general and domain-specific performance. Extensive experiments demonstrate that our scaling law holds across various CPT datasets and training hyper-parameters.
CRC-SGAD: Conformal Risk Control for Supervised Graph Anomaly Detection
Apr 03, 2025



Graph Anomaly Detection (GAD) is critical in security-sensitive domains, yet faces reliability challenges: miscalibrated confidence estimation (underconfidence in normal nodes, overconfidence in anomalies), adversarial vulnerability of derived confidence score under structural perturbations, and limited efficacy of conventional calibration methods for sparse anomaly patterns. Thus we propose CRC-SGAD, a framework integrating statistical risk control into GAD via two innovations: (1) A Dual-Threshold Conformal Risk Control mechanism that provides theoretically guaranteed bounds for both False Negative Rate (FNR) and False Positive Rate (FPR) through providing prediction sets; (2) A Subgraph-aware Spectral Graph Neural Calibrator (SSGNC) that optimizes node representations through adaptive spectral filtering while reducing the size of prediction sets via hybrid loss optimization. Experiments on four datasets and five GAD models demonstrate statistically significant improvements in FNR and FPR control and prediction set size. CRC-SGAD establishes a paradigm for statistically rigorous anomaly detection in graph-structured security applications.
Alleviating Performance Disparity in Adversarial Spatiotemporal Graph Learning Under Zero-Inflated Distribution
Apr 01, 2025Spatiotemporal Graph Learning (SGL) under Zero-Inflated Distribution (ZID) is crucial for urban risk management tasks, including crime prediction and traffic accident profiling. However, SGL models are vulnerable to adversarial attacks, compromising their practical utility. While adversarial training (AT) has been widely used to bolster model robustness, our study finds that traditional AT exacerbates performance disparities between majority and minority classes under ZID, potentially leading to irreparable losses due to underreporting critical risk events. In this paper, we first demonstrate the smaller top-k gradients and lower separability of minority class are key factors contributing to this disparity. To address these issues, we propose MinGRE, a framework for Minority Class Gradients and Representations Enhancement. MinGRE employs a multi-dimensional attention mechanism to reweight spatiotemporal gradients, minimizing the gradient distribution discrepancies across classes. Additionally, we introduce an uncertainty-guided contrastive loss to improve the inter-class separability and intra-class compactness of minority representations with higher uncertainty. Extensive experiments demonstrate that the MinGRE framework not only significantly reduces the performance disparity across classes but also achieves enhanced robustness compared to existing baselines. These findings underscore the potential of our method in fostering the development of more equitable and robust models.
Unveiling Factual Recall Behaviors of Large Language Models through Knowledge Neurons
Aug 06, 2024In this paper, we investigate whether Large Language Models (LLMs) actively recall or retrieve their internal repositories of factual knowledge when faced with reasoning tasks. Through an analysis of LLMs' internal factual recall at each reasoning step via Knowledge Neurons, we reveal that LLMs fail to harness the critical factual associations under certain circumstances. Instead, they tend to opt for alternative, shortcut-like pathways to answer reasoning questions. By manually manipulating the recall process of parametric knowledge in LLMs, we demonstrate that enhancing this recall process directly improves reasoning performance whereas suppressing it leads to notable degradation. Furthermore, we assess the effect of Chain-of-Thought (CoT) prompting, a powerful technique for addressing complex reasoning tasks. Our findings indicate that CoT can intensify the recall of factual knowledge by encouraging LLMs to engage in orderly and reliable reasoning. Furthermore, we explored how contextual conflicts affect the retrieval of facts during the reasoning process to gain a comprehensive understanding of the factual recall behaviors of LLMs. Code and data will be available soon.
Deep Causal Learning: Representation, Discovery and Inference
Nov 07, 2022



Causal learning has attracted much attention in recent years because causality reveals the essential relationship between things and indicates how the world progresses. However, there are many problems and bottlenecks in traditional causal learning methods, such as high-dimensional unstructured variables, combinatorial optimization problems, unknown intervention, unobserved confounders, selection bias and estimation bias. Deep causal learning, that is, causal learning based on deep neural networks, brings new insights for addressing these problems. While many deep learning-based causal discovery and causal inference methods have been proposed, there is a lack of reviews exploring the internal mechanism of deep learning to improve causal learning. In this article, we comprehensively review how deep learning can contribute to causal learning by addressing conventional challenges from three aspects: representation, discovery, and inference. We point out that deep causal learning is important for the theoretical extension and application expansion of causal science and is also an indispensable part of general artificial intelligence. We conclude the article with a summary of open issues and potential directions for future work.
An interpretable neural network model through piecewise linear approximation
Jan 20, 2020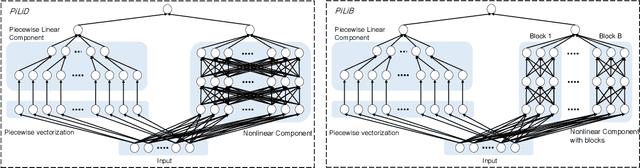
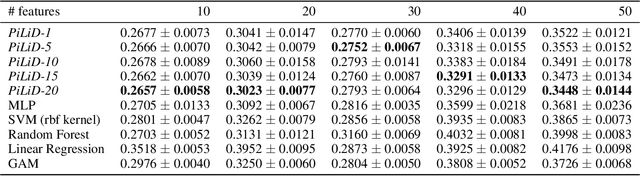

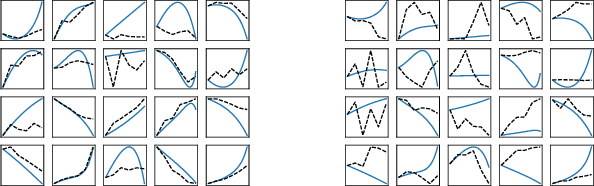
Most existing interpretable methods explain a black-box model in a post-hoc manner, which uses simpler models or data analysis techniques to interpret the predictions after the model is learned. However, they (a) may derive contradictory explanations on the same predictions given different methods and data samples, and (b) focus on using simpler models to provide higher descriptive accuracy at the sacrifice of prediction accuracy. To address these issues, we propose a hybrid interpretable model that combines a piecewise linear component and a nonlinear component. The first component describes the explicit feature contributions by piecewise linear approximation to increase the expressiveness of the model. The other component uses a multi-layer perceptron to capture feature interactions and implicit nonlinearity, and increase the prediction performance. Different from the post-hoc approaches, the interpretability is obtained once the model is learned in the form of feature shapes. We also provide a variant to explore higher-order interactions among features to demonstrate that the proposed model is flexible for adaptation. Experiments demonstrate that the proposed model can achieve good interpretability by describing feature shapes while maintaining state-of-the-art accuracy.
Multi-Label Annotation Aggregation in Crowdsourcing
Jun 19, 2017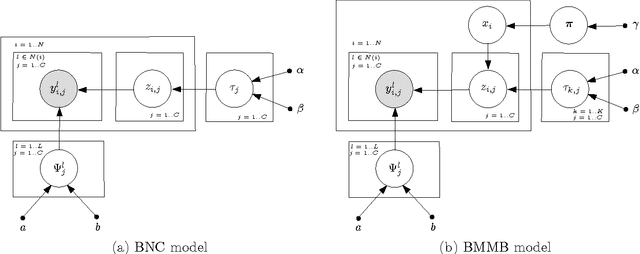

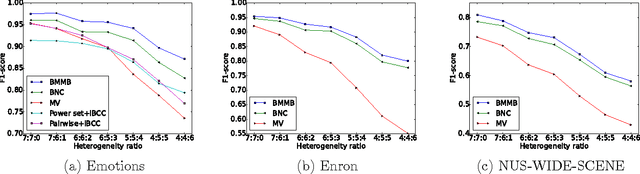
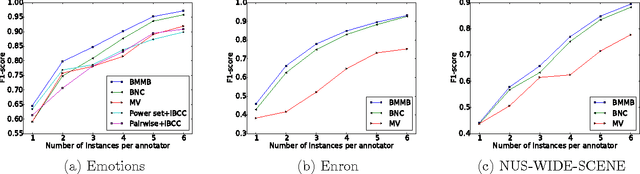
As a means of human-based computation, crowdsourcing has been widely used to annotate large-scale unlabeled datasets. One of the obvious challenges is how to aggregate these possibly noisy labels provided by a set of heterogeneous annotators. Another challenge stems from the difficulty in evaluating the annotator reliability without even knowing the ground truth, which can be used to build incentive mechanisms in crowdsourcing platforms. When each instance is associated with many possible labels simultaneously, the problem becomes even harder because of its combinatorial nature. In this paper, we present new flexible Bayesian models and efficient inference algorithms for multi-label annotation aggregation by taking both annotator reliability and label dependency into account. Extensive experiments on real-world datasets confirm that the proposed methods outperform other competitive alternatives, and the model can recover the type of the annotators with high accuracy. Besides, we empirically find that the mixture of multiple independent Bernoulli distribution is able to accurately capture label dependency in this unsupervised multi-label annotation aggregation scenario.