 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-platform Product Matching Based on Entity Alignment of Knowledge Graph with RAEA model
Dec 08, 2025Product matching aims to identify identical or similar products sold on different platforms. By building knowledge graphs (KGs), the product matching problem can be converted to the Entity Alignment (EA) task, which aims to discover the equivalent entities from diverse KGs. The existing EA methods inadequately utilize both attribute triples and relation triples simultaneously, especially the interactions between them. This paper introduces a two-stage pipeline consisting of rough filter and fine filter to match products from eBay and Amazon. For fine filtering, a new framework for Entity Alignment, Relation-aware and Attribute-aware Graph Attention Networks for Entity Alignment (RAEA), is employed. RAEA focuses on the interactions between attribute triples and relation triples, where the entity representation aggregates the alignment signals from attributes and relations with Attribute-aware Entity Encoder and Relation-aware Graph Attention Networks. The experimental results indicate that the RAEA model achieves significant improvements over 12 baselines on EA task in the cross-lingual dataset DBP15K (6.59% on average Hits@1) and delivers competitive results in the monolingual dataset DWY100K. The source code for experiments on DBP15K and DWY100K is available at github (https://github.com/Mockingjay-liu/RAEA-model-for-Entity-Alignment).
* 10 pages, 5 figures, published on World Wide Web
Displacement-Sparse Neural Optimal Transport
Feb 03, 2025Optimal Transport (OT) theory seeks to determine the map $T:X \to Y$ that transports a source measure $P$ to a target measure $Q$, minimizing the cost $c(\mathbf{x}, T(\mathbf{x}))$ between $\mathbf{x}$ and its image $T(\mathbf{x})$. Building upon the Input Convex Neural Network OT solver and incorporating the concept of displacement-sparse maps, we introduce a sparsity penalty into the minimax Wasserstein formulation, promote sparsity in displacement vectors $\Delta(\mathbf{x}) := T(\mathbf{x}) - \mathbf{x}$, and enhance the interpretability of the resulting map. However, increasing sparsity often reduces feasibility, causing $T_{\#}(P)$ to deviate more significantly from the target measure. In low-dimensional settings, we propose a heuristic framework to balance the trade-off between sparsity and feasibility by dynamically adjusting the sparsity intensity parameter during training. For high-dimensional settings, we directly constrain the dimensionality of displacement vectors by enforcing $\dim(\Delta(\mathbf{x})) \leq l$, where $l < d$ for $X \subseteq \mathbb{R}^d$. Among maps satisfying this constraint, we aim to identify the most feasible one. This goal can be effectively achieved by adapting our low-dimensional heuristic framework without resorting to dimensionality reduction. We validate our method on both synthesized sc-RNA and real 4i cell perturbation datasets, demonstrating improvements over existing methods.
Intrinsic Data Constraints and Upper Bounds in Binary Classification Performance
Jan 30, 2024The structure of data organization is widely recognized as having a substantial influence on the efficacy of machine learning algorithms, particularly in binary classification tasks. Our research provides a theoretical framework suggesting that the maximum potential of binary classifiers on a given dataset is primarily constrained by the inherent qualities of the data. Through both theoretical reasoning and empirical examination, we employed standard objective functions, evaluative metrics, and binary classifiers to arrive at two principal conclusions. Firstly, we show that the theoretical upper bound of binary classification performance on actual datasets can be theoretically attained. This upper boundary represents a calculable equilibrium between the learning loss and the metric of evaluation. Secondly, we have computed the precise upper bounds for three commonly used evaluation metrics, uncovering a fundamental uniformity with our overarching thesis: the upper bound is intricately linked to the dataset's characteristics, independent of the classifier in use. Additionally, our subsequent analysis uncovers a detailed relationship between the upper limit of performance and the level of class overlap within the binary classification data. This relationship is instrumental for pinpointing the most effective feature subsets for use in feature engineering.
Viewpoint-Invariant Exercise Repetition Counting
Jul 29, 2021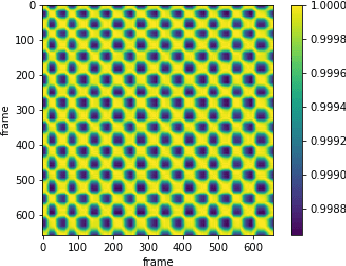
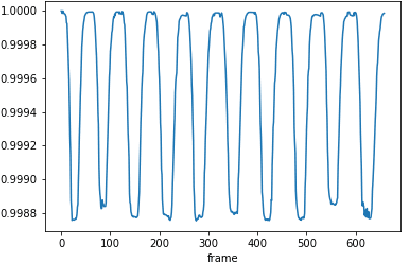
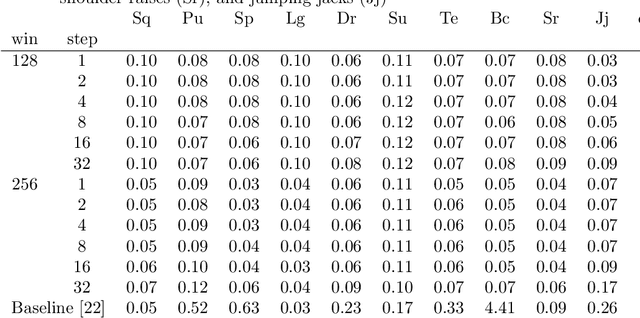
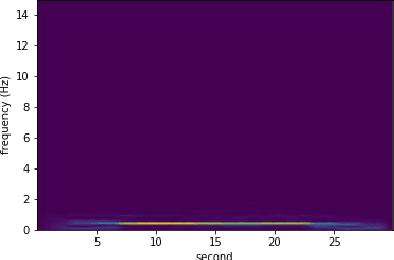
Counting the repetition of human exercise and physical rehabilitation is a common task in rehabilitation and exercise training. The existing vision-based repetition counting methods less emphasize the concurrent motions in the same video. This work presents a vision-based human motion repetition counting applicable to counting concurrent motions through the skeleton location extracted from various pose estimation methods. The presented method was validated on the University of Idaho Physical Rehabilitation Movements Data Set (UI-PRMD), and MM-fit dataset. The overall mean absolute error (MAE) for mm-fit was 0.06 with off-by-one Accuracy (OBOA) 0.94. Overall MAE for UI-PRMD dataset was 0.06 with OBOA 0.95. We have also tested the performance in a variety of camera locations and concurrent motions with conveniently collected video with overall MAE 0.06 and OBOA 0.88. The proposed method provides a view-angle and motion agnostic concurrent motion counting. This method can potentially use in large-scale remote rehabilitation and exercise training with only one camera.
An interpretable neural network model through piecewise linear approximation
Jan 20, 2020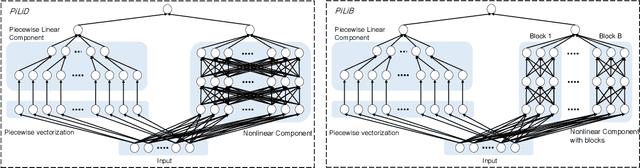
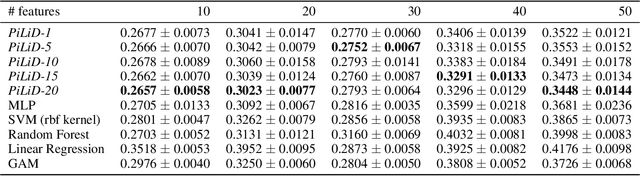

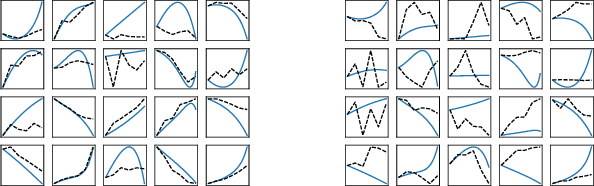
Most existing interpretable methods explain a black-box model in a post-hoc manner, which uses simpler models or data analysis techniques to interpret the predictions after the model is learned. However, they (a) may derive contradictory explanations on the same predictions given different methods and data samples, and (b) focus on using simpler models to provide higher descriptive accuracy at the sacrifice of prediction accuracy. To address these issues, we propose a hybrid interpretable model that combines a piecewise linear component and a nonlinear component. The first component describes the explicit feature contributions by piecewise linear approximation to increase the expressiveness of the model. The other component uses a multi-layer perceptron to capture feature interactions and implicit nonlinearity, and increase the prediction performance. Different from the post-hoc approaches, the interpretability is obtained once the model is learned in the form of feature shapes. We also provide a variant to explore higher-order interactions among features to demonstrate that the proposed model is flexible for adaptation. Experiments demonstrate that the proposed model can achieve good interpretability by describing feature shapes while maintaining state-of-the-art accuracy.
Knowledge-Enhanced Attentive Learning for Answer Selection in Community Question Answering Systems
Dec 17, 2019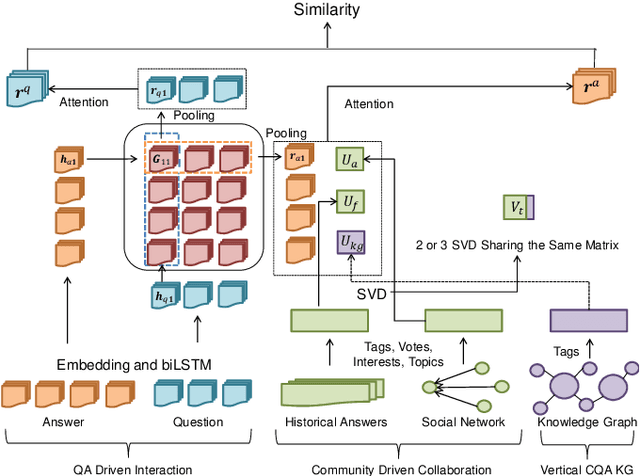
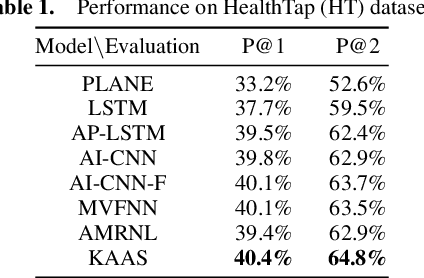
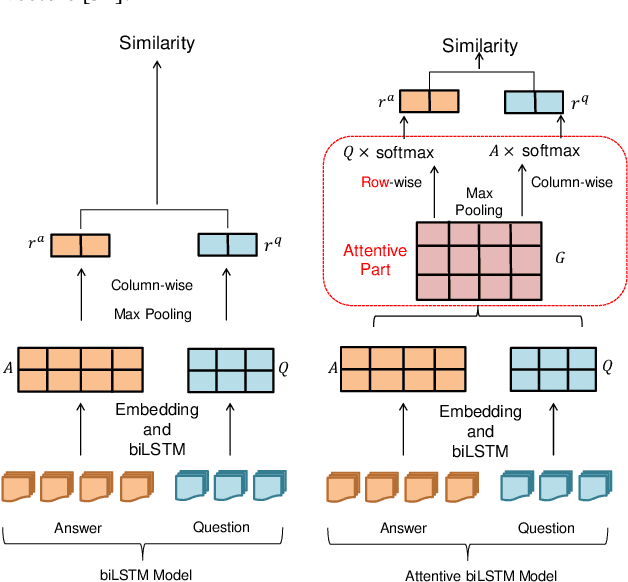
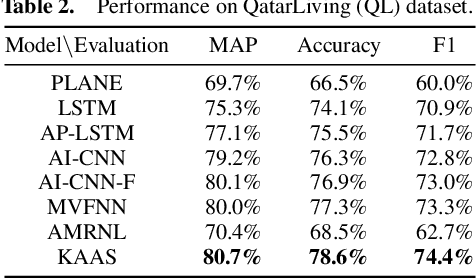
In the community question answering (CQA) system, the answer selection task aims to identify the best answer for a specific question, and thus is playing a key role in enhancing the service quality through recommending appropriate answers for new questions. Recent advances in CQA answer selection focus on enhancing the performance by incorporating the community information, particularly the expertise (previous answers) and authority (position in the social network) of an answerer. However, existing approaches for incorporating such information are limited in (a) only considering either the expertise or the authority, but not both; (b) ignoring the domain knowledge to differentiate topics of previous answers; and (c) simply using the authority information to adjust the similarity score, instead of fully utilizing it in the process of measuring the similarity between segments of the question and the answer. We propose the Knowledge-enhanced Attentive Answer Selection (KAAS) model, which enhances the performance through (a) considering both the expertise and the authority of the answerer; (b) utilizing the human-labeled tags, the taxonomy of the tags, and the votes as the domain knowledge to infer the expertise of the answer; (c) using matrix decomposition of the social network (formed by following-relationship) to infer the authority of the answerer and incorporating such information in the process of evaluating the similarity between segments. Besides, for vertical community, we incorporate an external knowledge graph to capture more professional information for vertical CQA systems. Then we adopt the attention mechanism to integrate the analysis of the text of questions and answers and the aforementioned community information. Experiments with both vertical and general CQA sites demonstrate the superior performance of the proposed KAAS model.
Explainable Ordinal Factorization Model: Deciphering the Effects of Attributes by Piece-wise Linear Approximation
Nov 14, 2019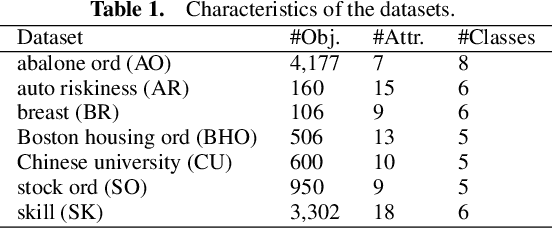
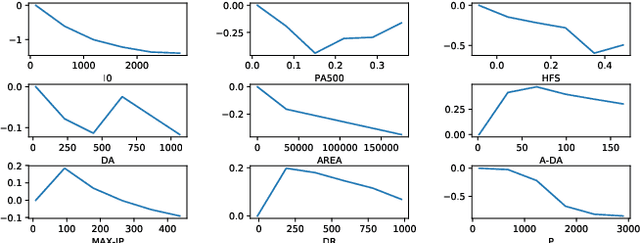

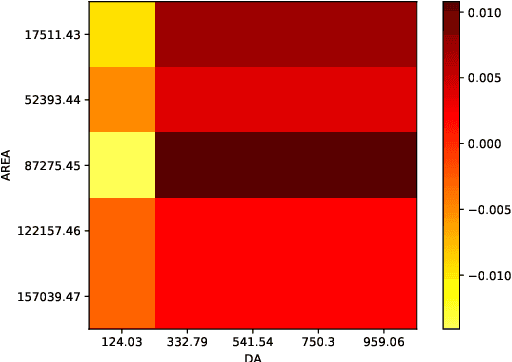
Ordinal regression predicts the objects' labels that exhibit a natural ordering, which is important to many managerial problems such as credit scoring and clinical diagnosis. In these problems, the ability to explain how the attributes affect the prediction is critical to users. However, most, if not all, existing ordinal regression models simplify such explanation in the form of constant coefficients for the main and interaction effects of individual attributes. Such explanation cannot characterize the contributions of attributes at different value scales. To address this challenge, we propose a new explainable ordinal regression model, namely, the Explainable Ordinal Factorization Model (XOFM). XOFM uses the piece-wise linear functions to approximate the actual contributions of individual attributes and their interactions. Moreover, XOFM introduces a novel ordinal transformation process to assign each object the probabilities of belonging to multiple relevant classes, instead of fixing boundaries to differentiate classes. XOFM is based on the Factorization Machines to handle the potential sparsity problem as a result of discretizing the attribute scales. Comprehensive experiments with benchmark datasets and baseline models demonstrate that the proposed XOFM exhibits superior explainability and leads to state-of-the-art prediction accuracy.
An interpretable machine learning framework for modelling human decision behavior
Jun 04, 2019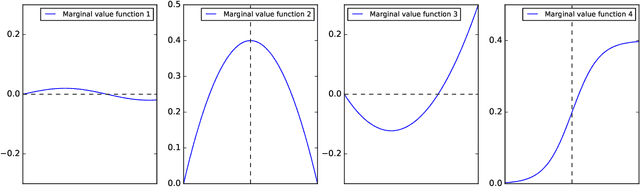
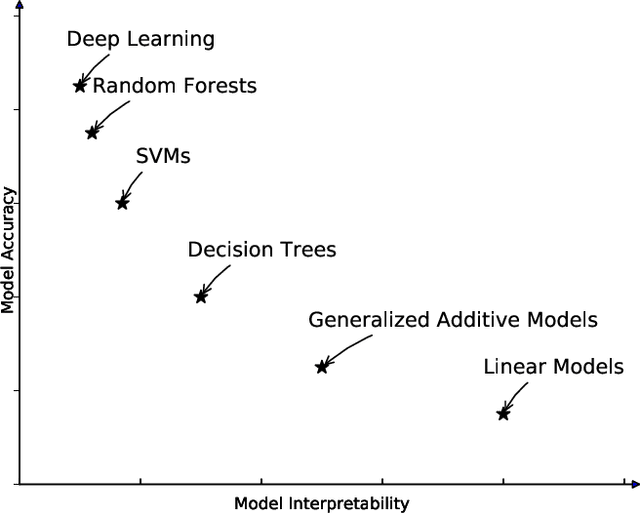
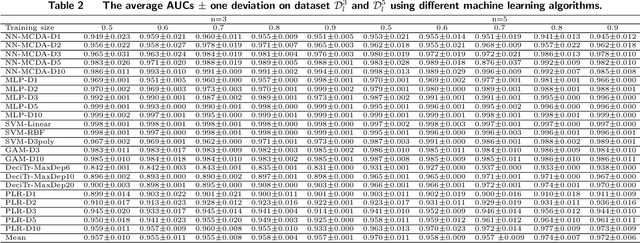
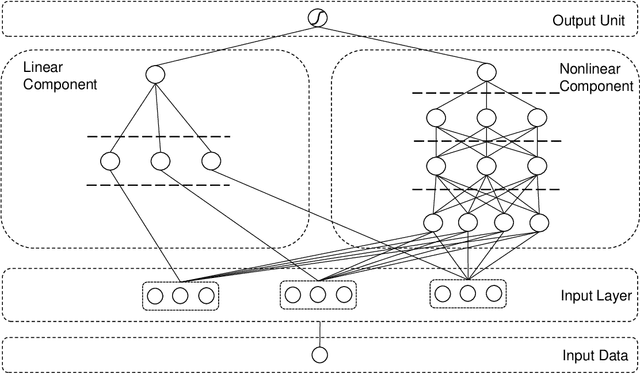
Machine learning has recently been widely adopted to address the managerial decision making problems. However, there is a trade-off between performance and interpretability. Full complexity models (such as neural network-based models) are non-traceable black-box, whereas classic interpretable models (such as logistic regression) are usually simplified with lower accuracy. This trade-off limits the application of state-of-the-art machine learning models in management problems, which requires high prediction performance, as well as the understanding of individual attributes' contributions to the model outcome. Multiple criteria decision aiding (MCDA) is a family of interpretable approaches to depicting the rationale of human decision behavior. It is also limited by strong assumptions (e.g. preference independence). In this paper, we propose an interpretable machine learning approach, namely Neural Network-based Multiple Criteria Decision Aiding (NN-MCDA), which combines an additive MCDA model and a fully-connected multilayer perceptron (MLP) to achieve good performance while preserving a certain degree of interpretability. NN-MCDA has a linear component (in an additive form of a set of polynomial functions) to capture the detailed relationship between individual attributes and the prediction, and a nonlinear component (in a standard MLP form) to capture the high-order interactions between attributes and their complex nonlinear transformations. We demonstrate the effectiveness of NN-MCDA with extensive simulation studies and two real-world datasets. To the best of our knowledge, this research is the first to enhance the interpretability of machine learning models with MCDA techniques. The proposed framework also sheds light on how to use machine learning techniques to free MCDA from strong assumptions.
E-LSTM-D: A Deep Learning Framework for Dynamic Network Link Prediction
Feb 22, 2019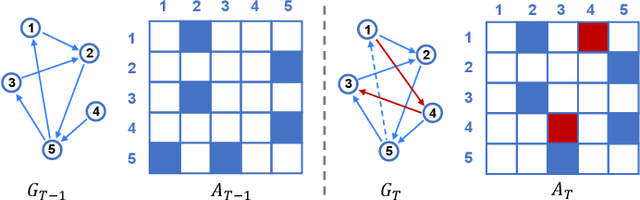
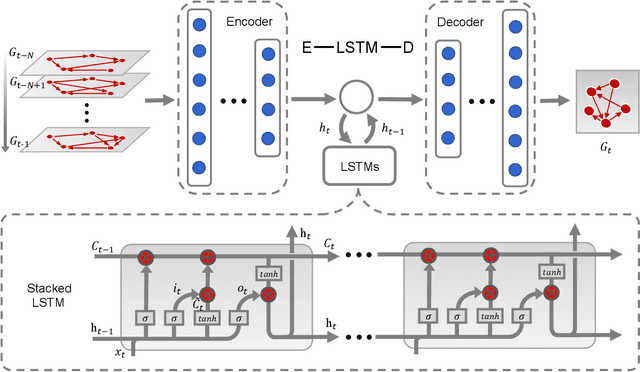
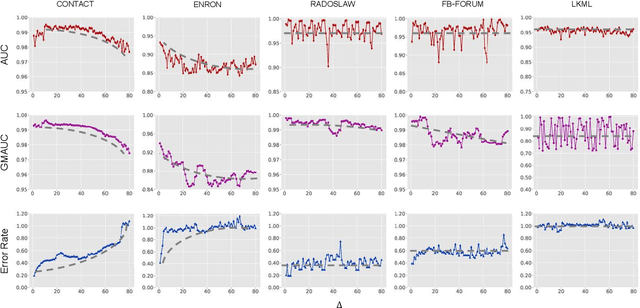
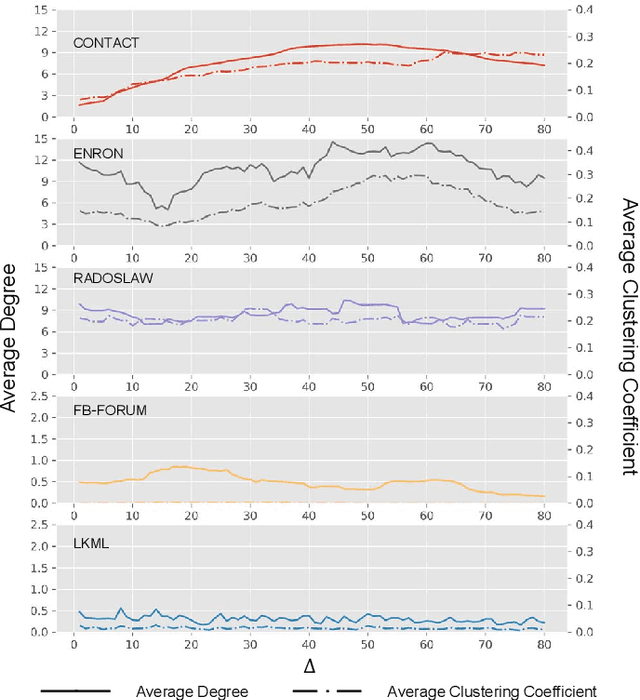
Predicting the potential relations between nodes in networks, known as link prediction, has long been a challenge in network science. However, most studies just focused on link prediction of static network, while real-world networks always evolve over time with the occurrence and vanishing of nodes and links. Dynamic network link prediction thus has been attracting more and more attention since it can better capture the evolution nature of networks, but still most algorithms fail to achieve satisfied prediction accuracy. Motivated by the excellent performance of Long Short-Term Memory (LSTM) in processing time series, in this paper, we propose a novel Encoder-LSTM-Decoder (E-LSTM-D) deep learning model to predict dynamic links end to end. It could handle long term prediction problems, and suits the networks of different scales with fine-tuned structure. To the best of our knowledge, it is the first time that LSTM, together with an encoder-decoder architecture, is applied to link prediction in dynamic networks. This new model is able to automatically learn structural and temporal features in a unified framework, which can predict the links that never appear in the network before. The extensive experiments show that our E-LSTM-D model significantly outperforms newly proposed dynamic network link prediction methods and obtain the state-of-the-art results.