 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolving Embodied Intelligence: Graph Neural Network--Driven Co-Design of Morphology and Control in Soft Robotics
Mar 20, 2026The intelligent behavior of robots does not emerge solely from control systems, but from the tight coupling between body and brain, a principle known as embodied intelligence. Designing soft robots that leverage this interaction remains a significant challenge, particularly when morphology and control require simultaneous optimization. A significant obstacle in this co-design process is that morphological evolution can disrupt learned control strategies, making it difficult to reuse or adapt existing knowledge. We address this by develop a Graph Neural Network-based approach for the co-design of morphology and controller. Each robot is represented as a graph, with a graph attention network (GAT) encoding node features and a pooled representation passed through a multilayer perceptron (MLP) head to produce actuator commands or value estimates. During evolution, inheritance follows a topology-consistent mapping: shared GAT layers are reused, MLP hidden layers are transferred intact, matched actuator outputs are copied, and unmatched ones are randomly initialized and fine-tuned. This morphology-aware policy class lets the controller adapt when the body mutates. On the benchmark, our GAT-based approach achieves higher final fitness and stronger adaptability to morphological variations compared to traditional MLP-only co-design methods. These results indicate that graph-structured policies provide a more effective interface between evolving morphologies and control for embodied intelligence.
Bi-level RL-Heuristic Optimization for Real-world Winter Road Maintenance
Feb 27, 2026Winter road maintenance is critical for ensuring public safety and reducing environmental impacts, yet existing methods struggle to manage large-scale routing problems effectively and mostly reply on human decision. This study presents a novel, scalable bi-level optimization framework, validated on real operational data on UK strategic road networks (M25, M6, A1), including interconnected local road networks in surrounding areas for vehicle traversing, as part of the highway operator's efforts to solve existing planning challenges. At the upper level, a reinforcement learning (RL) agent strategically partitions the road network into manageable clusters and optimally allocates resources from multiple depots. At the lower level, a multi-objective vehicle routing problem (VRP) is solved within each cluster, minimizing the maximum vehicle travel time and total carbon emissions. Unlike existing approaches, our method handles large-scale, real-world networks efficiently, explicitly incorporating vehicle-specific constraints, depot capacities, and road segment requirements. Results demonstrate significant improvements, including balanced workloads, reduced maximum travel times below the targeted two-hour threshold, lower emissions, and substantial cost savings. This study illustrates how advanced AI-driven bi-level optimization can directly enhance operational decision-making in real-world transportation and logistics.
Can Large Language Models Function as Qualified Pediatricians? A Systematic Evaluation in Real-World Clinical Contexts
Nov 17, 2025With the rapid rise of large language models (LLMs) in medicine, a key question is whether they can function as competent pediatricians in real-world clinical settings. We developed PEDIASBench, a systematic evaluation framework centered on a knowledge-system framework and tailored to realistic clinical environments. PEDIASBench assesses LLMs across three dimensions: application of basic knowledge, dynamic diagnosis and treatment capability, and pediatric medical safety and medical ethics. We evaluated 12 representative models released over the past two years, including GPT-4o, Qwen3-235B-A22B, and DeepSeek-V3, covering 19 pediatric subspecialties and 211 prototypical diseases. State-of-the-art models performed well on foundational knowledge, with Qwen3-235B-A22B achieving over 90% accuracy on licensing-level questions, but performance declined ~15% as task complexity increased, revealing limitations in complex reasoning. Multiple-choice assessments highlighted weaknesses in integrative reasoning and knowledge recall. In dynamic diagnosis and treatment scenarios, DeepSeek-R1 scored highest in case reasoning (mean 0.58), yet most models struggled to adapt to real-time patient changes. On pediatric medical ethics and safety tasks, Qwen2.5-72B performed best (accuracy 92.05%), though humanistic sensitivity remained limited. These findings indicate that pediatric LLMs are constrained by limited dynamic decision-making and underdeveloped humanistic care. Future development should focus on multimodal integration and a clinical feedback-model iteration loop to enhance safety, interpretability, and human-AI collaboration. While current LLMs cannot independently perform pediatric care, they hold promise for decision support, medical education, and patient communication, laying the groundwork for a safe, trustworthy, and collaborative intelligent pediatric healthcare system.
Auditory-Tactile Congruence for Synthesis of Adaptive Pain Expressions in RoboPatients
Jun 13, 2025Misdiagnosis can lead to delayed treatments and harm. Robotic patients offer a controlled way to train and evaluate clinicians in rare, subtle, or complex cases, reducing diagnostic errors. We present RoboPatient, a medical robotic simulator aimed at multimodal pain synthesis based on haptic and auditory feedback during palpation-based training scenarios. The robopatient functions as an adaptive intermediary, capable of synthesizing plausible pain expressions vocal and facial in response to tactile stimuli generated during palpation. Using an abdominal phantom, robopatient captures and processes haptic input via an internal palpation-to-pain mapping model. To evaluate perceptual congruence between palpation and the corresponding auditory output, we conducted a study involving 7680 trials across 20 participants, where they evaluated pain intensity through sound. Results show that amplitude and pitch significantly influence agreement with the robot's pain expressions, irrespective of pain sounds. Stronger palpation forces elicited stronger agreement, aligning with psychophysical patterns. The study revealed two key dimensions: pitch and amplitude are central to how people perceive pain sounds, with pitch being the most influential cue. These acoustic features shape how well the sound matches the applied force during palpation, impacting perceived realism. This approach lays the groundwork for high-fidelity robotic patients in clinical education and diagnostic simulation.
Palpation Alters Auditory Pain Expressions with Gender-Specific Variations in Robopatients
Jun 13, 2025Diagnostic errors remain a major cause of preventable deaths, particularly in resource-limited regions. Medical training simulators, including robopatients, play a vital role in reducing these errors by mimicking real patients for procedural training such as palpation. However, generating multimodal feedback, especially auditory pain expressions, remains challenging due to the complex relationship between palpation behavior and sound. The high-dimensional nature of pain sounds makes exploration challenging with conventional methods. This study introduces a novel experimental paradigm for pain expressivity in robopatients where they dynamically generate auditory pain expressions in response to palpation force, by co-optimizing human feedback using machine learning. Using Proximal Policy Optimization (PPO), a reinforcement learning (RL) technique optimized for continuous adaptation, our robot iteratively refines pain sounds based on real-time human feedback. This robot initializes randomized pain responses to palpation forces, and the RL agent learns to adjust these sounds to align with human preferences. The results demonstrated that the system adapts to an individual's palpation forces and sound preferences and captures a broad spectrum of pain intensity, from mild discomfort to acute distress, through RL-guided exploration of the auditory pain space. The study further showed that pain sound perception exhibits saturation at lower forces with gender specific thresholds. These findings highlight the system's potential to enhance abdominal palpation training by offering a controllable and immersive simulation platform.
The Morphology-Control Trade-Off: Insights into Soft Robotic Efficiency
Mar 20, 2025Soft robotics holds transformative potential for enabling adaptive and adaptable systems in dynamic environments. However, the interplay between morphological and control complexities and their collective impact on task performance remains poorly understood. Therefore, in this study, we investigate these trade-offs across tasks of differing difficulty levels using four well-used morphological complexity metrics and control complexity measured by FLOPs. We investigate how these factors jointly influence task performance by utilizing the evolutionary robot experiments. Results show that optimal performance depends on the alignment between morphology and control: simpler morphologies and lightweight controllers suffice for easier tasks, while harder tasks demand higher complexities in both dimensions. In addition, a clear trade-off between morphological and control complexities that achieve the same task performance can be observed. Moreover, we also propose a sensitivity analysis to expose the task-specific contributions of individual morphological metrics. Our study establishes a framework for investigating the relationships between morphology, control, and task performance, advancing the development of task-specific robotic designs that balance computational efficiency with adaptability. This study contributes to the practical application of soft robotics in real-world scenarios by providing actionable insights.
Displacement-Sparse Neural Optimal Transport
Feb 03, 2025Optimal Transport (OT) theory seeks to determine the map $T:X \to Y$ that transports a source measure $P$ to a target measure $Q$, minimizing the cost $c(\mathbf{x}, T(\mathbf{x}))$ between $\mathbf{x}$ and its image $T(\mathbf{x})$. Building upon the Input Convex Neural Network OT solver and incorporating the concept of displacement-sparse maps, we introduce a sparsity penalty into the minimax Wasserstein formulation, promote sparsity in displacement vectors $\Delta(\mathbf{x}) := T(\mathbf{x}) - \mathbf{x}$, and enhance the interpretability of the resulting map. However, increasing sparsity often reduces feasibility, causing $T_{\#}(P)$ to deviate more significantly from the target measure. In low-dimensional settings, we propose a heuristic framework to balance the trade-off between sparsity and feasibility by dynamically adjusting the sparsity intensity parameter during training. For high-dimensional settings, we directly constrain the dimensionality of displacement vectors by enforcing $\dim(\Delta(\mathbf{x})) \leq l$, where $l < d$ for $X \subseteq \mathbb{R}^d$. Among maps satisfying this constraint, we aim to identify the most feasible one. This goal can be effectively achieved by adapting our low-dimensional heuristic framework without resorting to dimensionality reduction. We validate our method on both synthesized sc-RNA and real 4i cell perturbation datasets, demonstrating improvements over existing methods.
A 'MAP' to find high-performing soft robot designs: Traversing complex design spaces using MAP-elites and Topology Optimization
Jul 10, 2024
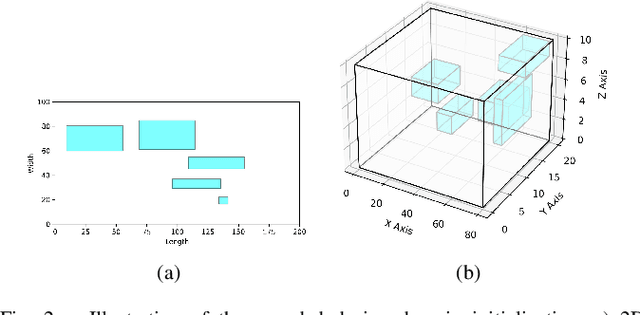
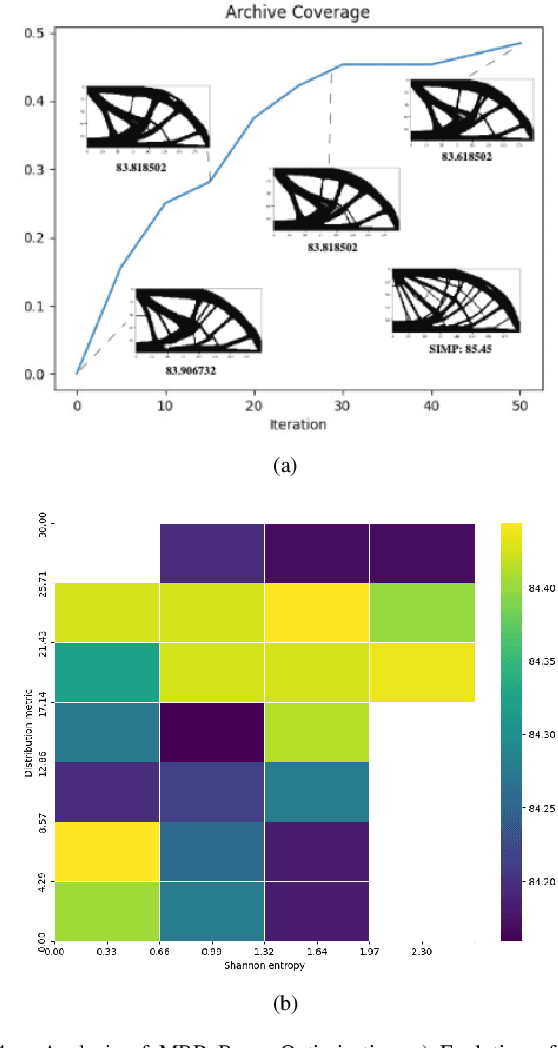
Soft robotics has emerged as the standard solution for grasping deformable objects, and has proven invaluable for mobile robotic exploration in extreme environments. However, despite this growth, there are no widely adopted computational design tools that produce quality, manufacturable designs. To advance beyond the diminishing returns of heuristic bio-inspiration, the field needs efficient tools to explore the complex, non-linear design spaces present in soft robotics, and find novel high-performing designs. In this work, we investigate a hierarchical design optimization methodology which combines the strengths of topology optimization and quality diversity optimization to generate diverse and high-performance soft robots by evolving the design domain. The method embeds variably sized void regions within the design domain and evolves their size and position, to facilitating a richer exploration of the design space and find a diverse set of high-performing soft robots. We demonstrate its efficacy on both benchmark topology optimization problems and soft robotic design problems, and show the method enhances grasp performance when applied to soft grippers. Our method provides a new framework to design parts in complex design domains, both soft and rigid.
Stochastic First-Order Methods with Non-smooth and Non-Euclidean Proximal Terms for Nonconvex High-Dimensional Stochastic Optimization
Jun 27, 2024When the nonconvex problem is complicated by stochasticity, the sample complexity of stochastic first-order methods may depend linearly on the problem dimension, which is undesirable for large-scale problems. In this work, we propose dimension-insensitive stochastic first-order methods (DISFOMs) to address nonconvex optimization with expected-valued objective function. Our algorithms allow for non-Euclidean and non-smooth distance functions as the proximal terms. Under mild assumptions, we show that DISFOM using minibatches to estimate the gradient enjoys sample complexity of $ \mathcal{O} ( (\log d) / \epsilon^4 ) $ to obtain an $\epsilon$-stationary point. Furthermore, we prove that DISFOM employing variance reduction can sharpen this bound to $\mathcal{O} ( (\log d)^{2/3}/\epsilon^{10/3} )$, which perhaps leads to the best-known sample complexity result in terms of $d$. We provide two choices of the non-smooth distance functions, both of which allow for closed-form solutions to the proximal step. Numerical experiments are conducted to illustrate the dimension insensitive property of the proposed frameworks.
VEnvision3D: A Synthetic Perception Dataset for 3D Multi-Task Model Research
Mar 05, 2024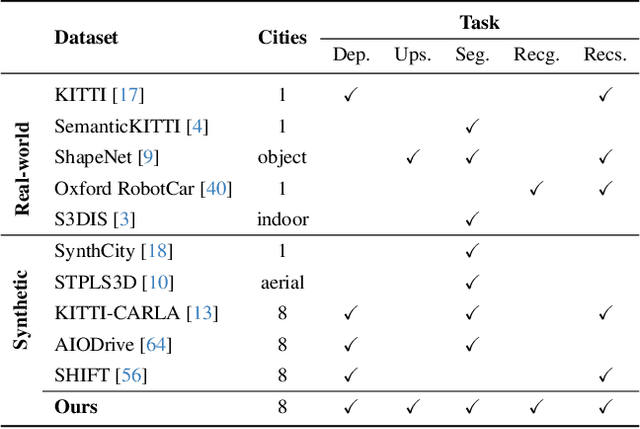
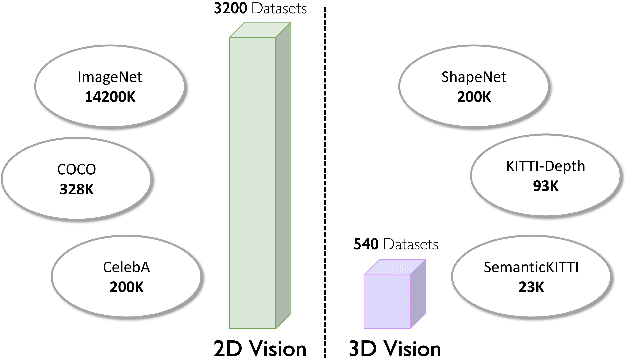


Developing a unified multi-task foundation model has become a critical challenge in computer vision research. In the current field of 3D computer vision, most datasets only focus on single task, which complicates the concurrent training requirements of various downstream tasks. In this paper, we introduce VEnvision3D, a large 3D synthetic perception dataset for multi-task learning, including depth completion, segmentation, upsampling, place recognition, and 3D reconstruction. Since the data for each task is collected in the same environmental domain, sub-tasks are inherently aligned in terms of the utilized data. Therefore, such a unique attribute can assist in exploring the potential for the multi-task model and even the foundation model without separate training methods. Meanwhile, capitalizing on the advantage of virtual environments being freely editable, we implement some novel settings such as simulating temporal changes in the environment and sampling point clouds on model surfaces. These characteristics enable us to present several new benchmarks. We also perform extensive studies on multi-task end-to-end models, revealing new observations, challenges, and opportunities for future research. Our dataset and code will be open-sourced upon acceptance.