 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVRD-Bench: Multi-View Learning and Benchmarking for Dynamic Remote Photoplethysmography under Occlusion
Mar 24, 2026Remote photoplethysmography (rPPG) is a non-contact technique that estimates physiological signals by analyzing subtle skin color changes in facial videos. Existing rPPG methods often encounter performance degradation under facial motion and occlusion scenarios due to their reliance on static and single-view facial videos. Thus, this work focuses on tackling the motion-induced occlusion problem for rPPG measurement in unconstrained multi-view facial videos. Specifically, we introduce a Multi-View rPPG Dataset (MVRD), a high-quality benchmark dataset featuring synchronized facial videos from three viewpoints under stationary, speaking, and head movement scenarios to better match real-world conditions. We also propose MVRD-rPPG, a unified multi-view rPPG learning framework that fuses complementary visual cues to maintain robust facial skin coverage, especially under motion conditions. Our method integrates an Adaptive Temporal Optical Compensation (ATOC) module for motion artifact suppression, a Rhythm-Visual Dual-Stream Network to disentangle rhythmic and appearance-related features, and a Multi-View Correlation-Aware Attention (MVCA) for adaptive view-wise signal aggregation. Furthermore, we introduce a Correlation Frequency Adversarial (CFA) learning strategy, which jointly enforces temporal accuracy, spectral consistency, and perceptual realism in the predicted signals. Extensive experiments and ablation studies on the MVRD dataset demonstrate the superiority of our approach. In the MVRD movement scenario, MVRD-rPPG achieves an MAE of 0.90 and a Pearson correlation coefficient (R) of 0.99. The source code and dataset will be made available.
Micro-AU CLIP: Fine-Grained Contrastive Learning from Local Independence to Global Dependency for Micro-Expression Action Unit Detection
Mar 17, 2026Micro-expression (ME) action units (Micro-AUs) provide objective clues for fine-grained genuine emotion analysis. Most existing Micro-AU detection methods learn AU features from the whole facial image/video, which conflicts with the inherent locality of AU, resulting in insufficient perception of AU regions. In fact, each AU independently corresponds to specific localized facial muscle movements (local independence), while there is an inherent dependency between some AUs under specific emotional states (global dependency). Thus, this paper explores the effectiveness of the independence-to-dependency pattern and proposes a novel micro-AU detection framework, micro-AU CLIP, that uniquely decomposes the AU detection process into local semantic independence modeling (LSI) and global semantic dependency (GSD) modeling. In LSI, Patch Token Attention (PTA) is designed, mapping several local features within the AU region to the same feature space; In GSD, Global Dependency Attention (GDA) and Global Dependency Loss (GDLoss) are presented to model the global dependency relationships between different AUs, thereby enhancing each AU feature. Furthermore, considering CLIP's native limitations in micro-semantic alignment, a microAU contrastive loss (MiAUCL) is designed to learn AU features by a fine-grained alignment of visual and text features. Also, Micro-AU CLIP is effectively applied to ME recognition in an emotion-label-free way. The experimental results demonstrate that Micro-AU CLIP can fully learn fine-grained micro-AU features, achieving state-of-the-art performance.
FDeID-Toolbox: Face De-Identification Toolbox
Mar 13, 2026Face de-identification (FDeID) aims to remove personally identifiable information from facial images while preserving task-relevant utility attributes such as age, gender, and expression. It is critical for privacy-preserving computer vision, yet the field suffers from fragmented implementations, inconsistent evaluation protocols, and incomparable results across studies. These challenges stem from the inherent complexity of the task: FDeID spans multiple downstream applications (e.g., age estimation, gender recognition, expression analysis) and requires evaluation across three dimensions (e.g., privacy protection, utility preservation, and visual quality), making existing codebases difficult to use and extend. To address these issues, we present FDeID-Toolbox, a comprehensive toolbox designed for reproducible FDeID research. Our toolbox features a modular architecture comprising four core components: (1) standardized data loaders for mainstream benchmark datasets, (2) unified method implementations spanning classical approaches to SOTA generative models, (3) flexible inference pipelines, and (4) systematic evaluation protocols covering privacy, utility, and quality metrics. Through experiments, we demonstrate that FDeID-Toolbox enables fair and reproducible comparison of diverse FDeID methods under consistent conditions.
Steering Vision-Language Pre-trained Models for Incremental Face Presentation Attack Detection
Dec 24, 2025Face Presentation Attack Detection (PAD) demands incremental learning (IL) to combat evolving spoofing tactics and domains. Privacy regulations, however, forbid retaining past data, necessitating rehearsal-free IL (RF-IL). Vision-Language Pre-trained (VLP) models, with their prompt-tunable cross-modal representations, enable efficient adaptation to new spoofing styles and domains. Capitalizing on this strength, we propose \textbf{SVLP-IL}, a VLP-based RF-IL framework that balances stability and plasticity via \textit{Multi-Aspect Prompting} (MAP) and \textit{Selective Elastic Weight Consolidation} (SEWC). MAP isolates domain dependencies, enhances distribution-shift sensitivity, and mitigates forgetting by jointly exploiting universal and domain-specific cues. SEWC selectively preserves critical weights from previous tasks, retaining essential knowledge while allowing flexibility for new adaptations. Comprehensive experiments across multiple PAD benchmarks show that SVLP-IL significantly reduces catastrophic forgetting and enhances performance on unseen domains. SVLP-IL offers a privacy-compliant, practical solution for robust lifelong PAD deployment in RF-IL settings.
Semantic Mismatch and Perceptual Degradation: A New Perspective on Image Editing Immunity
Dec 16, 2025



Text-guided image editing via diffusion models, while powerful, raises significant concerns about misuse, motivating efforts to immunize images against unauthorized edits using imperceptible perturbations. Prevailing metrics for evaluating immunization success typically rely on measuring the visual dissimilarity between the output generated from a protected image and a reference output generated from the unprotected original. This approach fundamentally overlooks the core requirement of image immunization, which is to disrupt semantic alignment with attacker intent, regardless of deviation from any specific output. We argue that immunization success should instead be defined by the edited output either semantically mismatching the prompt or suffering substantial perceptual degradations, both of which thwart malicious intent. To operationalize this principle, we propose Synergistic Intermediate Feature Manipulation (SIFM), a method that strategically perturbs intermediate diffusion features through dual synergistic objectives: (1) maximizing feature divergence from the original edit trajectory to disrupt semantic alignment with the expected edit, and (2) minimizing feature norms to induce perceptual degradations. Furthermore, we introduce the Immunization Success Rate (ISR), a novel metric designed to rigorously quantify true immunization efficacy for the first time. ISR quantifies the proportion of edits where immunization induces either semantic failure relative to the prompt or significant perceptual degradations, assessed via Multimodal Large Language Models (MLLMs). Extensive experiments show our SIFM achieves the state-of-the-art performance for safeguarding visual content against malicious diffusion-based manipulation.
Controllable Localized Face Anonymization Via Diffusion Inpainting
Sep 18, 2025



The growing use of portrait images in computer vision highlights the need to protect personal identities. At the same time, anonymized images must remain useful for downstream computer vision tasks. In this work, we propose a unified framework that leverages the inpainting ability of latent diffusion models to generate realistic anonymized images. Unlike prior approaches, we have complete control over the anonymization process by designing an adaptive attribute-guidance module that applies gradient correction during the reverse denoising process, aligning the facial attributes of the generated image with those of the synthesized target image. Our framework also supports localized anonymization, allowing users to specify which facial regions are left unchanged. Extensive experiments conducted on the public CelebA-HQ and FFHQ datasets show that our method outperforms state-of-the-art approaches while requiring no additional model training. The source code is available on our page.
Learning Transferable Facial Emotion Representations from Large-Scale Semantically Rich Captions
Jul 28, 2025Current facial emotion recognition systems are predominately trained to predict a fixed set of predefined categories or abstract dimensional values. This constrained form of supervision hinders generalization and applicability, as it reduces the rich and nuanced spectrum of emotions into oversimplified labels or scales. In contrast, natural language provides a more flexible, expressive, and interpretable way to represent emotions, offering a much broader source of supervision. Yet, leveraging semantically rich natural language captions as supervisory signals for facial emotion representation learning remains relatively underexplored, primarily due to two key challenges: 1) the lack of large-scale caption datasets with rich emotional semantics, and 2) the absence of effective frameworks tailored to harness such rich supervision. To this end, we introduce EmoCap100K, a large-scale facial emotion caption dataset comprising over 100,000 samples, featuring rich and structured semantic descriptions that capture both global affective states and fine-grained local facial behaviors. Building upon this dataset, we further propose EmoCapCLIP, which incorporates a joint global-local contrastive learning framework enhanced by a cross-modal guided positive mining module. This design facilitates the comprehensive exploitation of multi-level caption information while accommodating semantic similarities between closely related expressions. Extensive evaluations on over 20 benchmarks covering five tasks demonstrate the superior performance of our method, highlighting the promise of learning facial emotion representations from large-scale semantically rich captions. The code and data will be available at https://github.com/sunlicai/EmoCapCLIP.
EmotionHallucer: Evaluating Emotion Hallucinations in Multimodal Large Language Models
May 16, 2025Emotion understanding is a critical yet challenging task. Recent advances in Multimodal Large Language Models (MLLMs) have significantly enhanced their capabilities in this area. However, MLLMs often suffer from hallucinations, generating irrelevant or nonsensical content. To the best of our knowledge, despite the importance of this issue, there has been no dedicated effort to evaluate emotion-related hallucinations in MLLMs. In this work, we introduce EmotionHallucer, the first benchmark for detecting and analyzing emotion hallucinations in MLLMs. Unlike humans, whose emotion understanding stems from the interplay of biology and social learning, MLLMs rely solely on data-driven learning and lack innate emotional instincts. Fortunately, emotion psychology provides a solid foundation of knowledge about human emotions. Building on this, we assess emotion hallucinations from two dimensions: emotion psychology knowledge and real-world multimodal perception. To support robust evaluation, we utilize an adversarial binary question-answer (QA) framework, which employs carefully crafted basic and hallucinated pairs to assess the emotion hallucination tendencies of MLLMs. By evaluating 38 LLMs and MLLMs on EmotionHallucer, we reveal that: i) most current models exhibit substantial issues with emotion hallucinations; ii) closed-source models outperform open-source ones in detecting emotion hallucinations, and reasoning capability provides additional advantages; iii) existing models perform better in emotion psychology knowledge than in multimodal emotion perception. As a byproduct, these findings inspire us to propose the PEP-MEK framework, which yields an average improvement of 9.90% in emotion hallucination detection across selected models. Resources will be available at https://github.com/xxtars/EmotionHallucer.
MagicPortrait: Temporally Consistent Face Reenactment with 3D Geometric Guidance
Apr 30, 2025In this paper, we propose a method for video face reenactment that integrates a 3D face parametric model into a latent diffusion framework, aiming to improve shape consistency and motion control in existing video-based face generation approaches. Our approach employs the FLAME (Faces Learned with an Articulated Model and Expressions) model as the 3D face parametric representation, providing a unified framework for modeling face expressions and head pose. This enables precise extraction of detailed face geometry and motion features from driving videos. Specifically, we enhance the latent diffusion model with rich 3D expression and detailed pose information by incorporating depth maps, normal maps, and rendering maps derived from FLAME sequences. A multi-layer face movements fusion module with integrated self-attention mechanisms is used to combine identity and motion latent features within the spatial domain. By utilizing the 3D face parametric model as motion guidance, our method enables parametric alignment of face identity between the reference image and the motion captured from the driving video. Experimental results on benchmark datasets show that our method excels at generating high-quality face animations with precise expression and head pose variation modeling. In addition, it demonstrates strong generalization performance on out-of-domain images. Code is publicly available at https://github.com/weimengting/MagicPortrait.
Contrastive Language-Image Learning with Augmented Textual Prompts for 3D/4D FER Using Vision-Language Model
Apr 28, 2025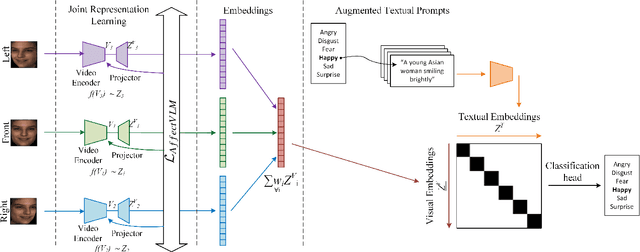
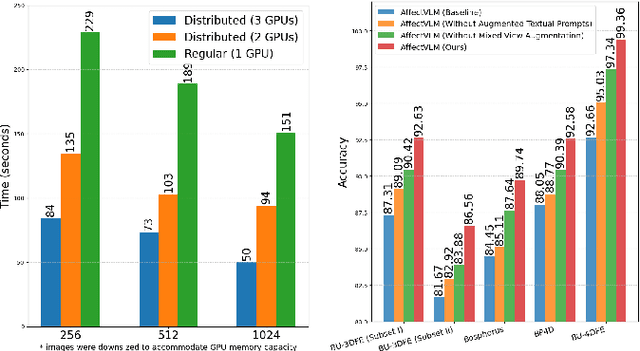


In this paper, we introduce AffectVLM, a vision-language model designed to integrate multiviews for a semantically rich and visually comprehensive understanding of facial emotions from 3D/4D data. To effectively capture visual features, we propose a joint representation learning framework paired with a novel gradient-friendly loss function that accelerates model convergence towards optimal feature representation. Additionally, we introduce augmented textual prompts to enhance the model's linguistic capabilities and employ mixed view augmentation to expand the visual dataset. We also develop a Streamlit app for a real-time interactive inference and enable the model for distributed learning. Extensive experiments validate the superior performance of AffectVLM across multiple benchmarks.