 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVRD-Bench: Multi-View Learning and Benchmarking for Dynamic Remote Photoplethysmography under Occlusion
Mar 24, 2026Remote photoplethysmography (rPPG) is a non-contact technique that estimates physiological signals by analyzing subtle skin color changes in facial videos. Existing rPPG methods often encounter performance degradation under facial motion and occlusion scenarios due to their reliance on static and single-view facial videos. Thus, this work focuses on tackling the motion-induced occlusion problem for rPPG measurement in unconstrained multi-view facial videos. Specifically, we introduce a Multi-View rPPG Dataset (MVRD), a high-quality benchmark dataset featuring synchronized facial videos from three viewpoints under stationary, speaking, and head movement scenarios to better match real-world conditions. We also propose MVRD-rPPG, a unified multi-view rPPG learning framework that fuses complementary visual cues to maintain robust facial skin coverage, especially under motion conditions. Our method integrates an Adaptive Temporal Optical Compensation (ATOC) module for motion artifact suppression, a Rhythm-Visual Dual-Stream Network to disentangle rhythmic and appearance-related features, and a Multi-View Correlation-Aware Attention (MVCA) for adaptive view-wise signal aggregation. Furthermore, we introduce a Correlation Frequency Adversarial (CFA) learning strategy, which jointly enforces temporal accuracy, spectral consistency, and perceptual realism in the predicted signals. Extensive experiments and ablation studies on the MVRD dataset demonstrate the superiority of our approach. In the MVRD movement scenario, MVRD-rPPG achieves an MAE of 0.90 and a Pearson correlation coefficient (R) of 0.99. The source code and dataset will be made available.
Radar-APLANC: Unsupervised Radar-based Heartbeat Sensing via Augmented Pseudo-Label and Noise Contrast
Nov 11, 2025Frequency Modulated Continuous Wave (FMCW) radars can measure subtle chest wall oscillations to enable non-contact heartbeat sensing. However, traditional radar-based heartbeat sensing methods face performance degradation due to noise. Learning-based radar methods achieve better noise robustness but require costly labeled signals for supervised training. To overcome these limitations, we propose the first unsupervised framework for radar-based heartbeat sensing via Augmented Pseudo-Label and Noise Contrast (Radar-APLANC). We propose to use both the heartbeat range and noise range within the radar range matrix to construct the positive and negative samples, respectively, for improved noise robustness. Our Noise-Contrastive Triplet (NCT) loss only utilizes positive samples, negative samples, and pseudo-label signals generated by the traditional radar method, thereby avoiding dependence on expensive ground-truth physiological signals. We further design a pseudo-label augmentation approach featuring adaptive noise-aware label selection to improve pseudo-label signal quality. Extensive experiments on the Equipleth dataset and our collected radar dataset demonstrate that our unsupervised method achieves performance comparable to state-of-the-art supervised methods. Our code, dataset, and supplementary materials can be accessed from https://github.com/RadarHRSensing/Radar-APLANC.
From Laboratory to Real World: A New Benchmark Towards Privacy-Preserved Visible-Infrared Person Re-Identification
Mar 15, 2025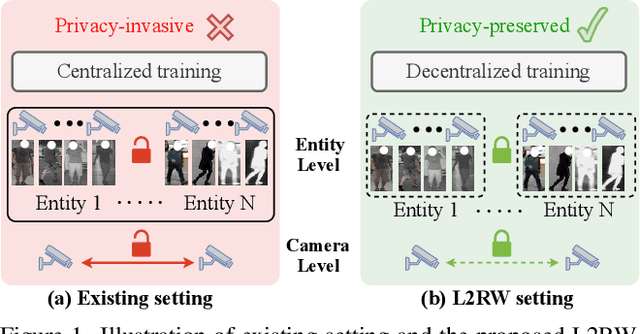
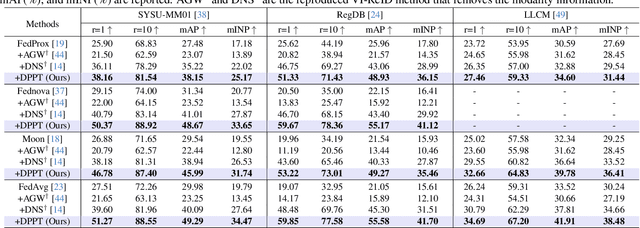
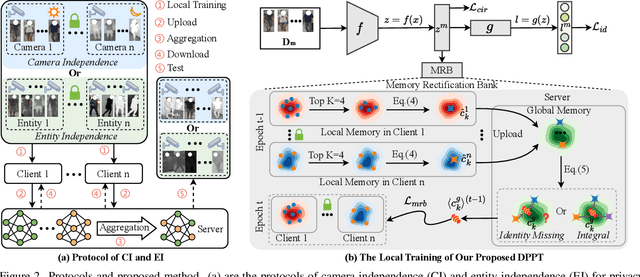
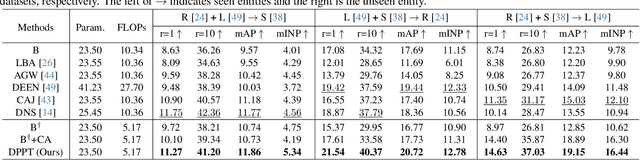
Aiming to match pedestrian images captured under varying lighting conditions, visible-infrared person re-identification (VI-ReID) has drawn intensive research attention and achieved promising results. However, in real-world surveillance contexts, data is distributed across multiple devices/entities, raising privacy and ownership concerns that make existing centralized training impractical for VI-ReID. To tackle these challenges, we propose L2RW, a benchmark that brings VI-ReID closer to real-world applications. The rationale of L2RW is that integrating decentralized training into VI-ReID can address privacy concerns in scenarios with limited data-sharing regulation. Specifically, we design protocols and corresponding algorithms for different privacy sensitivity levels. In our new benchmark, we ensure the model training is done in the conditions that: 1) data from each camera remains completely isolated, or 2) different data entities (e.g., data controllers of a certain region) can selectively share the data. In this way, we simulate scenarios with strict privacy constraints which is closer to real-world conditions. Intensive experiments with various server-side federated algorithms are conducted, showing the feasibility of decentralized VI-ReID training. Notably, when evaluated in unseen domains (i.e., new data entities), our L2RW, trained with isolated data (privacy-preserved), achieves performance comparable to SOTAs trained with shared data (privacy-unrestricted). We hope this work offers a novel research entry for deploying VI-ReID that fits real-world scenarios and can benefit the community.
Biometric Authentication Based on Enhanced Remote Photoplethysmography Signal Morphology
Jul 04, 2024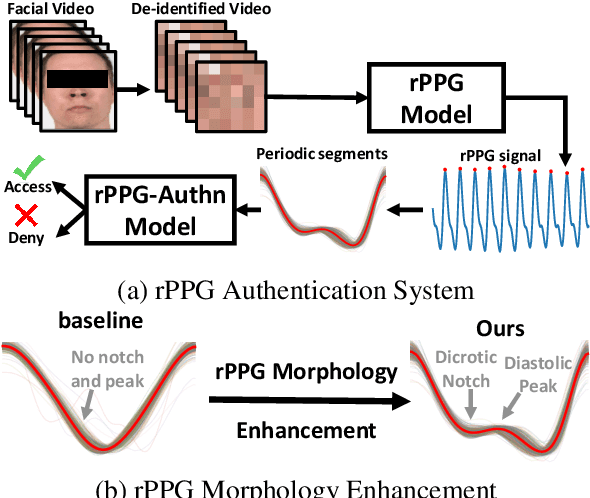
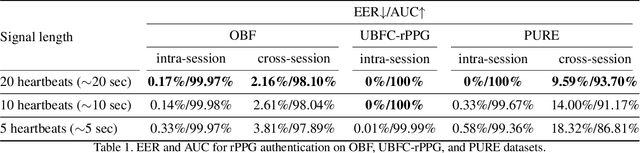
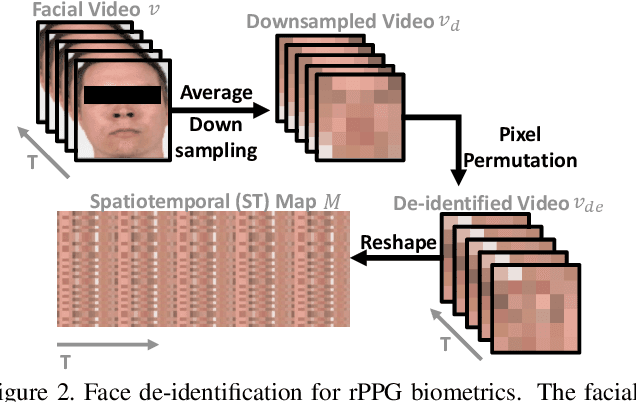
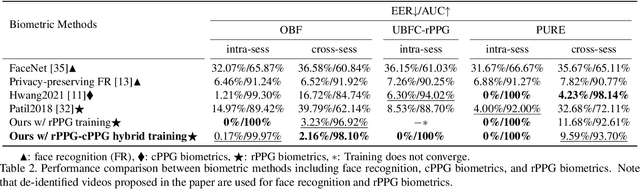
Remote photoplethysmography (rPPG) is a non-contact method for measuring cardiac signals from facial videos, offering a convenient alternative to contact photoplethysmography (cPPG) obtained from contact sensors. Recent studies have shown that each individual possesses a unique cPPG signal morphology that can be utilized as a biometric identifier, which has inspired us to utilize the morphology of rPPG signals extracted from facial videos for person authentication. Since the facial appearance and rPPG are mixed in the facial videos, we first de-identify facial videos to remove facial appearance while preserving the rPPG information, which protects facial privacy and guarantees that only rPPG is used for authentication. The de-identified videos are fed into an rPPG model to get the rPPG signal morphology for authentication. In the first training stage, unsupervised rPPG training is performed to get coarse rPPG signals. In the second training stage, an rPPG-cPPG hybrid training is performed by incorporating external cPPG datasets to achieve rPPG biometric authentication and enhance rPPG signal morphology. Our approach needs only de-identified facial videos with subject IDs to train rPPG authentication models. The experimental results demonstrate that rPPG signal morphology hidden in facial videos can be used for biometric authentication. The code is available at https://github.com/zhaodongsun/rppg_biometrics.
Analyzing Participants' Engagement during Online Meetings Using Unsupervised Remote Photoplethysmography with Behavioral Features
Apr 05, 2024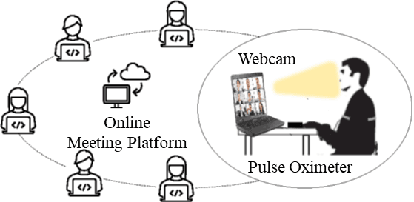

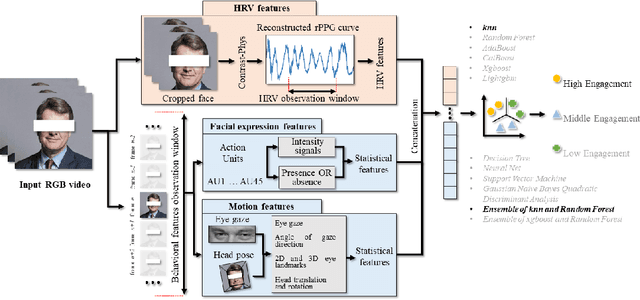

Engagement measurement finds application in healthcare, education, advertisement, and services. The use of physiological and behavioral features is viable, but the impracticality of traditional physiological measurement arises due to the need for contact sensors. We demonstrate the feasibility of unsupervised remote photoplethysmography (rPPG) as an alternative for contact sensors in deriving heart rate variability (HRV) features, then fusing these with behavioral features to measure engagement in online group meetings. Firstly, a unique Engagement Dataset of online interactions among social workers is collected with granular engagement labels, offering insight into virtual meeting dynamics. Secondly, a pre-trained rPPG model is customized to reconstruct accurate rPPG signals from video meetings in an unsupervised manner, enabling the calculation of HRV features. Thirdly, the feasibility of estimating engagement from HRV features using short observation windows, with a notable enhancement when using longer observation windows of two to four minutes, is demonstrated. Fourthly, the effectiveness of behavioral cues is evaluated and fused with physiological data, which further enhances engagement estimation performance. An accuracy of 94% is achieved when only HRV features are used, eliminating the need for contact sensors or ground truth signals. The incorporation of behavioral cues raises the accuracy to 96%. Facial video analysis offers precise engagement measurement, beneficial for future applications.
Contrast-Phys+: Unsupervised and Weakly-supervised Video-based Remote Physiological Measurement via Spatiotemporal Contrast
Sep 13, 2023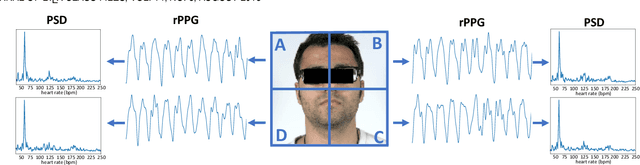
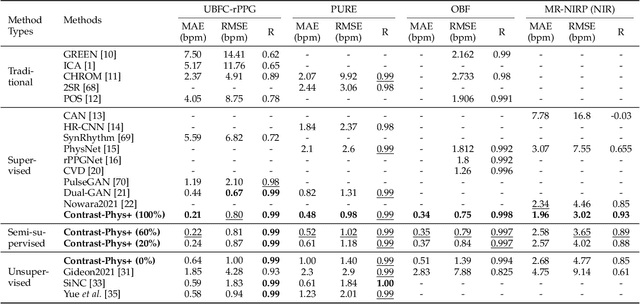
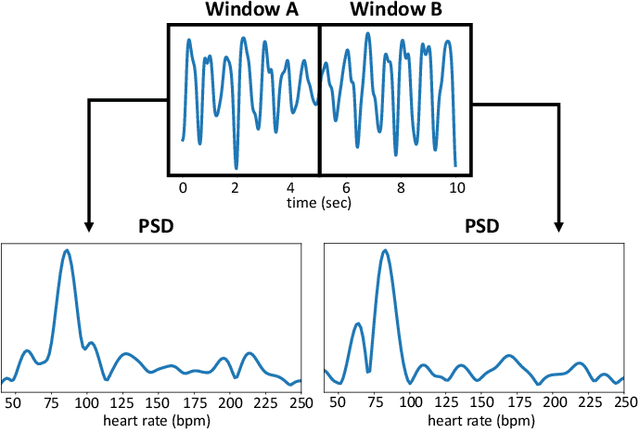
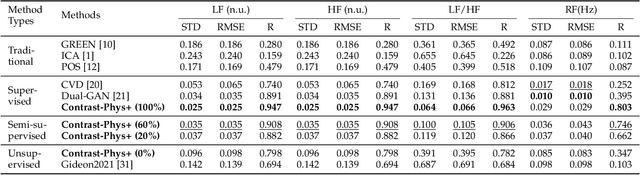
Video-based remote physiological measurement utilizes facial videos to measure the blood volume change signal, which is also called remote photoplethysmography (rPPG). Supervised methods for rPPG measurements have been shown to achieve good performance. However, the drawback of these methods is that they require facial videos with ground truth (GT) physiological signals, which are often costly and difficult to obtain. In this paper, we propose Contrast-Phys+, a method that can be trained in both unsupervised and weakly-supervised settings. We employ a 3DCNN model to generate multiple spatiotemporal rPPG signals and incorporate prior knowledge of rPPG into a contrastive loss function. We further incorporate the GT signals into contrastive learning to adapt to partial or misaligned labels. The contrastive loss encourages rPPG/GT signals from the same video to be grouped together, while pushing those from different videos apart. We evaluate our methods on five publicly available datasets that include both RGB and Near-infrared videos. Contrast-Phys+ outperforms the state-of-the-art supervised methods, even when using partially available or misaligned GT signals, or no labels at all. Additionally, we highlight the advantages of our methods in terms of computational efficiency, noise robustness, and generalization.
Contrast-Phys: Unsupervised Video-based Remote Physiological Measurement via Spatiotemporal Contrast
Aug 08, 2022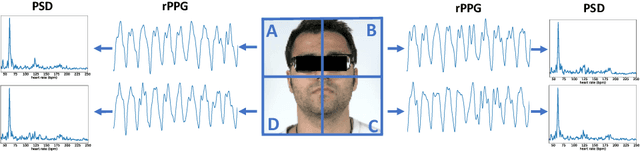
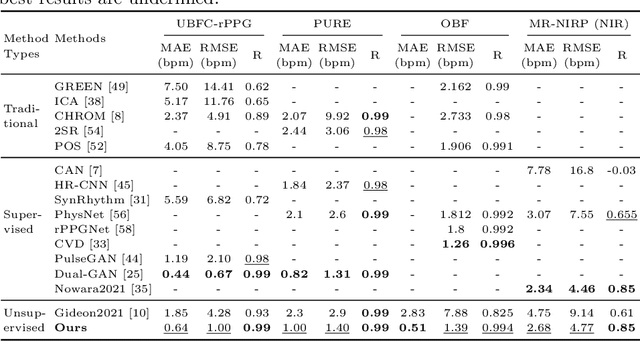

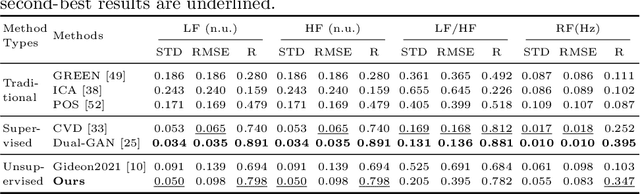
Video-based remote physiological measurement utilizes face videos to measure the blood volume change signal, which is also called remote photoplethysmography (rPPG). Supervised methods for rPPG measurements achieve state-of-the-art performance. However, supervised rPPG methods require face videos and ground truth physiological signals for model training. In this paper, we propose an unsupervised rPPG measurement method that does not require ground truth signals for training. We use a 3DCNN model to generate multiple rPPG signals from each video in different spatiotemporal locations and train the model with a contrastive loss where rPPG signals from the same video are pulled together while those from different videos are pushed away. We test on five public datasets, including RGB videos and NIR videos. The results show that our method outperforms the previous unsupervised baseline and achieves accuracies very close to the current best supervised rPPG methods on all five datasets. Furthermore, we also demonstrate that our approach can run at a much faster speed and is more robust to noises than the previous unsupervised baseline. Our code is available at https://github.com/zhaodongsun/contrast-phys.
Non-contact Atrial Fibrillation Detection from Face Videos by Learning Systolic Peaks
Oct 14, 2021
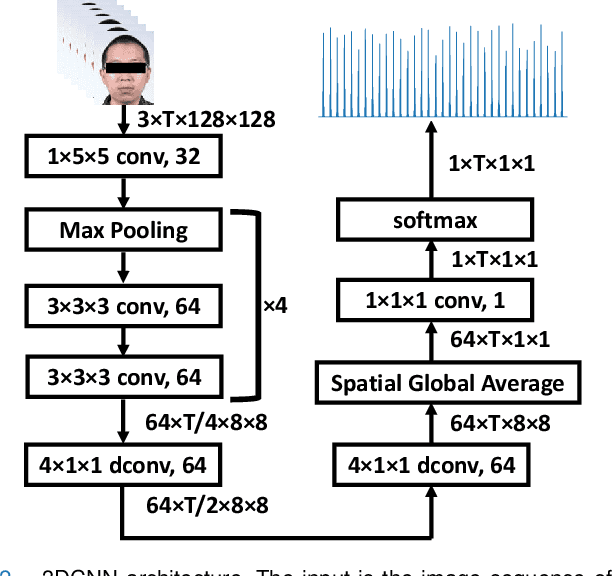
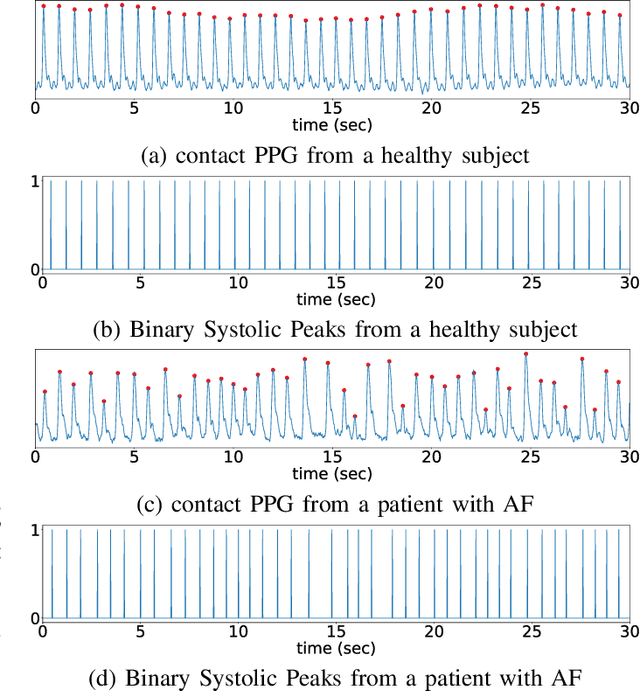
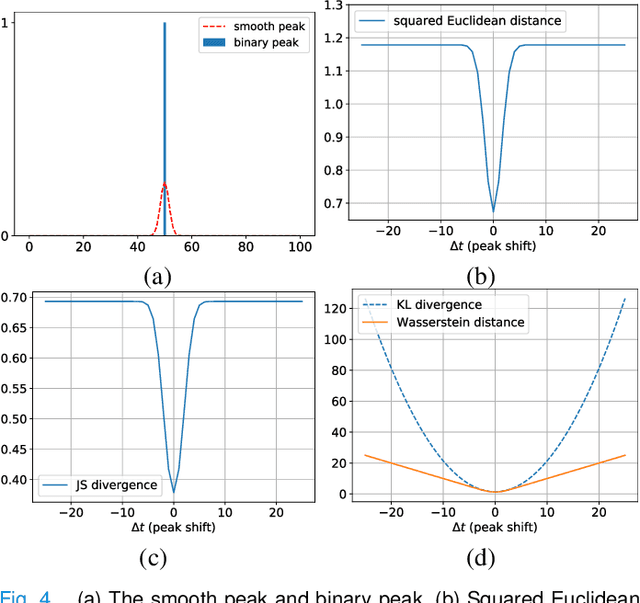
Objective: We propose a non-contact approach for atrial fibrillation (AF) detection from face videos. Methods: Face videos, electrocardiography (ECG), and contact photoplethysmography (PPG) from 100 healthy subjects and 100 AF patients are recorded. All the videos in the healthy group are labeled as healthy. Videos in the patient group are labeled as AF, sinus rhythm (SR), or atrial flutter (AFL) by cardiologists. We use the 3D convolutional neural network for remote PPG measurement and propose a novel loss function (Wasserstein distance) to use the timing of systolic peaks from contact PPG as the label for our model training. Then a set of heart rate variability (HRV) features are calculated from the inter-beat intervals, and a support vector machine (SVM) classifier is trained with HRV features. Results: Our proposed method can accurately extract systolic peaks from face videos for AF detection. The proposed method is trained with subject-independent 10-fold cross-validation with 30s video clips and tested on two tasks. 1) Classification of healthy versus AF: the accuracy, sensitivity, and specificity are 96.16%, 95.71%, and 96.23%. 2) Classification of SR versus AF: the accuracy, sensitivity, and specificity are 95.31%, 98.66%, and 91.11%. Conclusion: We achieve good performance of non-contact AF detection by learning systolic peaks. Significance: non-contact AF detection can be used for self-screening of AF symptom for suspectable populations at home, or self-monitoring of AF recurrence after treatment for the chronical patients.
Solving Inverse Problems with Hybrid Deep Image Priors: the challenge of preventing overfitting
Nov 03, 2020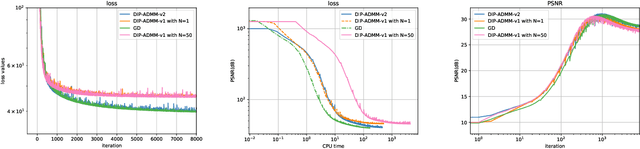
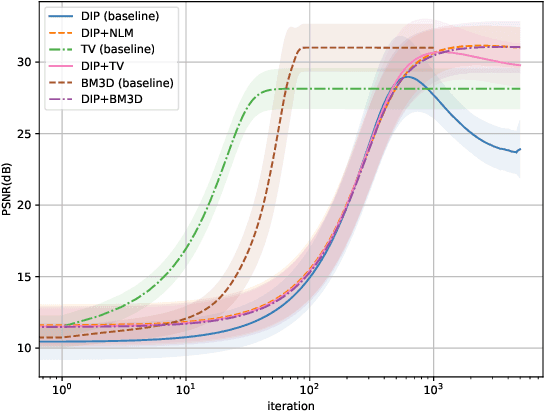
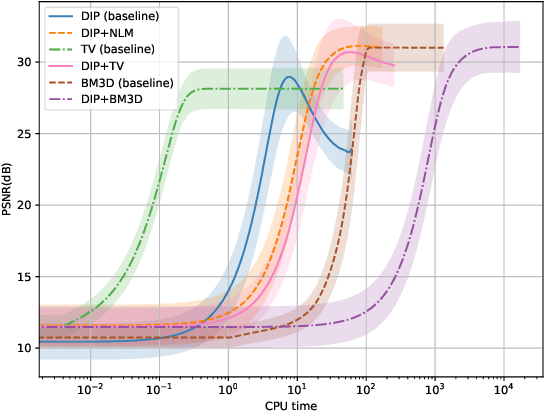

We mainly analyze and solve the overfitting problem of deep image prior (DIP). Deep image prior can solve inverse problems such as super-resolution, inpainting and denoising. The main advantage of DIP over other deep learning approaches is that it does not need access to a large dataset. However, due to the large number of parameters of the neural network and noisy data, DIP overfits to the noise in the image as the number of iterations grows. In the thesis, we use hybrid deep image priors to avoid overfitting. The hybrid priors are to combine DIP with an explicit prior such as total variation or with an implicit prior such as a denoising algorithm. We use the alternating direction method-of-multipliers (ADMM) to incorporate the new prior and try different forms of ADMM to avoid extra computation caused by the inner loop of ADMM steps. We also study the relation between the dynamics of gradient descent, and the overfitting phenomenon. The numerical results show the hybrid priors play an important role in preventing overfitting. Besides, we try to fit the image along some directions and find this method can reduce overfitting when the noise level is large. When the noise level is small, it does not considerably reduce the overfitting problem.