 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXAI-CLIP: ROI-Guided Perturbation Framework for Explainable Medical Image Segmentation in Multimodal Vision-Language Models
Feb 01, 2026Medical image segmentation is a critical component of clinical workflows, enabling accurate diagnosis, treatment planning, and disease monitoring. However, despite the superior performance of transformer-based models over convolutional architectures, their limited interpretability remains a major obstacle to clinical trust and deployment. Existing explainable artificial intelligence (XAI) techniques, including gradient-based saliency methods and perturbation-based approaches, are often computationally expensive, require numerous forward passes, and frequently produce noisy or anatomically irrelevant explanations. To address these limitations, we propose XAI-CLIP, an ROI-guided perturbation framework that leverages multimodal vision-language model embeddings to localize clinically meaningful anatomical regions and guide the explanation process. By integrating language-informed region localization with medical image segmentation and applying targeted, region-aware perturbations, the proposed method generates clearer, boundary-aware saliency maps while substantially reducing computational overhead. Experiments conducted on the FLARE22 and CHAOS datasets demonstrate that XAI-CLIP achieves up to a 60\% reduction in runtime, a 44.6\% improvement in dice score, and a 96.7\% increase in Intersection-over-Union for occlusion-based explanations compared to conventional perturbation methods. Qualitative results further confirm cleaner and more anatomically consistent attribution maps with fewer artifacts, highlighting that the incorporation of multimodal vision-language representations into perturbation-based XAI frameworks significantly enhances both interpretability and efficiency, thereby enabling transparent and clinically deployable medical image segmentation systems.
SwinTF3D: A Lightweight Multimodal Fusion Approach for Text-Guided 3D Medical Image Segmentation
Dec 28, 2025The recent integration of artificial intelligence into medical imaging has driven remarkable advances in automated organ segmentation. However, most existing 3D segmentation frameworks rely exclusively on visual learning from large annotated datasets restricting their adaptability to new domains and clinical tasks. The lack of semantic understanding in these models makes them ineffective in addressing flexible, user-defined segmentation objectives. To overcome these limitations, we propose SwinTF3D, a lightweight multimodal fusion approach that unifies visual and linguistic representations for text-guided 3D medical image segmentation. The model employs a transformer-based visual encoder to extract volumetric features and integrates them with a compact text encoder via an efficient fusion mechanism. This design allows the system to understand natural-language prompts and correctly align semantic cues with their corresponding spatial structures in medical volumes, while producing accurate, context-aware segmentation results with low computational overhead. Extensive experiments on the BTCV dataset demonstrate that SwinTF3D achieves competitive Dice and IoU scores across multiple organs, despite its compact architecture. The model generalizes well to unseen data and offers significant efficiency gains compared to conventional transformer-based segmentation networks. Bridging visual perception with linguistic understanding, SwinTF3D establishes a practical and interpretable paradigm for interactive, text-driven 3D medical image segmentation, opening perspectives for more adaptive and resource-efficient solutions in clinical imaging.
Attack-Aware Deepfake Detection under Counter-Forensic Manipulations
Dec 26, 2025This work presents an attack-aware deepfake and image-forensics detector designed for robustness, well-calibrated probabilities, and transparent evidence under realistic deployment conditions. The method combines red-team training with randomized test-time defense in a two-stream architecture, where one stream encodes semantic content using a pretrained backbone and the other extracts forensic residuals, fused via a lightweight residual adapter for classification, while a shallow Feature Pyramid Network style head produces tamper heatmaps under weak supervision. Red-team training applies worst-of-K counter-forensics per batch, including JPEG realign and recompress, resampling warps, denoise-to-regrain operations, seam smoothing, small color and gamma shifts, and social-app transcodes, while test-time defense injects low-cost jitters such as resize and crop phase changes, mild gamma variation, and JPEG phase shifts with aggregated predictions. Heatmaps are guided to concentrate within face regions using face-box masks without strict pixel-level annotations. Evaluation on existing benchmarks, including standard deepfake datasets and a surveillance-style split with low light and heavy compression, reports clean and attacked performance, AUC, worst-case accuracy, reliability, abstention quality, and weak-localization scores. Results demonstrate near-perfect ranking across attacks, low calibration error, minimal abstention risk, and controlled degradation under regrain, establishing a modular, data-efficient, and practically deployable baseline for attack-aware detection with calibrated probabilities and actionable heatmaps.
AquaDiff: Diffusion-Based Underwater Image Enhancement for Addressing Color Distortion
Dec 15, 2025Underwater images are severely degraded by wavelength-dependent light absorption and scattering, resulting in color distortion, low contrast, and loss of fine details that hinder vision-based underwater applications. To address these challenges, we propose AquaDiff, a diffusion-based underwater image enhancement framework designed to correct chromatic distortions while preserving structural and perceptual fidelity. AquaDiff integrates a chromatic prior-guided color compensation strategy with a conditional diffusion process, where cross-attention dynamically fuses degraded inputs and noisy latent states at each denoising step. An enhanced denoising backbone with residual dense blocks and multi-resolution attention captures both global color context and local details. Furthermore, a novel cross-domain consistency loss jointly enforces pixel-level accuracy, perceptual similarity, structural integrity, and frequency-domain fidelity. Extensive experiments on multiple challenging underwater benchmarks demonstrate that AquaDiff provides good results as compared to the state-of-the-art traditional, CNN-, GAN-, and diffusion-based methods, achieving superior color correction and competitive overall image quality across diverse underwater conditions.
From Graphs to Gates: DNS-HyXNet, A Lightweight and Deployable Sequential Model for Real-Time DNS Tunnel Detection
Dec 10, 2025



Domain Name System (DNS) tunneling remains a covert channel for data exfiltration and command-and-control communication. Although graph-based methods such as GraphTunnel achieve strong accuracy, they introduce significant latency and computational overhead due to recursive parsing and graph construction, limiting their suitability for real-time deployment. This work presents DNS-HyXNet, a lightweight extended Long Short-Term Memory (xLSTM) hybrid framework designed for efficient sequence-based DNS tunnel detection. DNS-HyXNet integrates tokenized domain embeddings with normalized numerical DNS features and processes them through a two-layer xLSTM network that directly learns temporal dependencies from packet sequences, eliminating the need for graph reconstruction and enabling single-stage multi-class classification. The model was trained and evaluated on two public benchmark datasets with carefully tuned hyperparameters to ensure low memory consumption and fast inference. Across all experimental splits of the DNS-Tunnel-Datasets, DNS-HyXNet achieved up to 99.99% accuracy, with macro-averaged precision, recall, and F1-scores exceeding 99.96%, and demonstrated a per-sample detection latency of just 0.041 ms, confirming its scalability and real-time readiness. These results show that sequential modeling with xLSTM can effectively replace computationally expensive recursive graph generation, offering a deployable and energy-efficient alternative for real-time DNS tunnel detection on commodity hardware.
Facial Emotion Learning with Text-Guided Multiview Fusion via Vision-Language Model for 3D/4D Facial Expression Recognition
Jul 02, 2025



Facial expression recognition (FER) in 3D and 4D domains presents a significant challenge in affective computing due to the complexity of spatial and temporal facial dynamics. Its success is crucial for advancing applications in human behavior understanding, healthcare monitoring, and human-computer interaction. In this work, we propose FACET-VLM, a vision-language framework for 3D/4D FER that integrates multiview facial representation learning with semantic guidance from natural language prompts. FACET-VLM introduces three key components: Cross-View Semantic Aggregation (CVSA) for view-consistent fusion, Multiview Text-Guided Fusion (MTGF) for semantically aligned facial emotions, and a multiview consistency loss to enforce structural coherence across views. Our model achieves state-of-the-art accuracy across multiple benchmarks, including BU-3DFE, Bosphorus, BU-4DFE, and BP4D-Spontaneous. We further extend FACET-VLM to 4D micro-expression recognition (MER) on the 4DME dataset, demonstrating strong performance in capturing subtle, short-lived emotional cues. The extensive experimental results confirm the effectiveness and substantial contributions of each individual component within the framework. Overall, FACET-VLM offers a robust, extensible, and high-performing solution for multimodal FER in both posed and spontaneous settings.
Beam-Guided Knowledge Replay for Knowledge-Rich Image Captioning using Vision-Language Model
May 29, 2025Generating informative and knowledge-rich image captions remains a challenge for many existing captioning models, which often produce generic descriptions that lack specificity and contextual depth. To address this limitation, we propose KRCapVLM, a knowledge replay-based novel image captioning framework using vision-language model. We incorporate beam search decoding to generate more diverse and coherent captions. We also integrate attention-based modules into the image encoder to enhance feature representation. Finally, we employ training schedulers to improve stability and ensure smoother convergence during training. These proposals accelerate substantial gains in both caption quality and knowledge recognition. Our proposed model demonstrates clear improvements in both the accuracy of knowledge recognition and the overall quality of generated captions. It shows a stronger ability to generalize to previously unseen knowledge concepts, producing more informative and contextually relevant descriptions. These results indicate the effectiveness of our approach in enhancing the model's capacity to generate meaningful, knowledge-grounded captions across a range of scenarios.
Underwater Diffusion Attention Network with Contrastive Language-Image Joint Learning for Underwater Image Enhancement
May 26, 2025

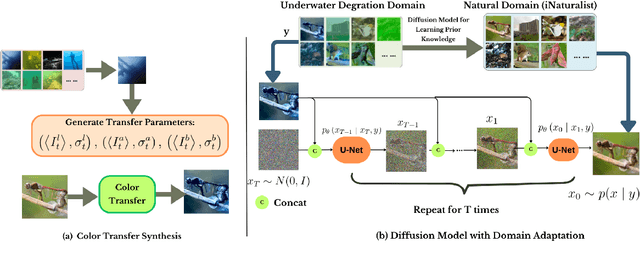

Underwater images are often affected by complex degradations such as light absorption, scattering, color casts, and artifacts, making enhancement critical for effective object detection, recognition, and scene understanding in aquatic environments. Existing methods, especially diffusion-based approaches, typically rely on synthetic paired datasets due to the scarcity of real underwater references, introducing bias and limiting generalization. Furthermore, fine-tuning these models can degrade learned priors, resulting in unrealistic enhancements due to domain shifts. To address these challenges, we propose UDAN-CLIP, an image-to-image diffusion framework pre-trained on synthetic underwater datasets and enhanced with a customized classifier based on vision-language model, a spatial attention module, and a novel CLIP-Diffusion loss. The classifier preserves natural in-air priors and semantically guides the diffusion process, while the spatial attention module focuses on correcting localized degradations such as haze and low contrast. The proposed CLIP-Diffusion loss further strengthens visual-textual alignment and helps maintain semantic consistency during enhancement. The proposed contributions empower our UDAN-CLIP model to perform more effective underwater image enhancement, producing results that are not only visually compelling but also more realistic and detail-preserving. These improvements are consistently validated through both quantitative metrics and qualitative visual comparisons, demonstrating the model's ability to correct distortions and restore natural appearance in challenging underwater conditions.
Deformable Attentive Visual Enhancement for Referring Segmentation Using Vision-Language Model
May 25, 2025Image segmentation is a fundamental task in computer vision, aimed at partitioning an image into semantically meaningful regions. Referring image segmentation extends this task by using natural language expressions to localize specific objects, requiring effective integration of visual and linguistic information. In this work, we propose SegVLM, a vision-language model that incorporates architectural improvements to enhance segmentation accuracy and cross-modal alignment. The model integrates squeeze-and-excitation (SE) blocks for dynamic feature recalibration, deformable convolutions for geometric adaptability, and residual connections for deep feature learning. We also introduce a novel referring-aware fusion (RAF) loss that balances region-level alignment, boundary precision, and class imbalance. Extensive experiments and ablation studies demonstrate that each component contributes to consistent performance improvements. SegVLM also shows strong generalization across diverse datasets and referring expression scenarios.
MOSAIC: A Multi-View 2.5D Organ Slice Selector with Cross-Attentional Reasoning for Anatomically-Aware CT Localization in Medical Organ Segmentation
May 15, 2025Efficient and accurate multi-organ segmentation from abdominal CT volumes is a fundamental challenge in medical image analysis. Existing 3D segmentation approaches are computationally and memory intensive, often processing entire volumes that contain many anatomically irrelevant slices. Meanwhile, 2D methods suffer from class imbalance and lack cross-view contextual awareness. To address these limitations, we propose a novel, anatomically-aware slice selector pipeline that reduces input volume prior to segmentation. Our unified framework introduces a vision-language model (VLM) for cross-view organ presence detection using fused tri-slice (2.5D) representations from axial, sagittal, and coronal planes. Our proposed model acts as an "expert" in anatomical localization, reasoning over multi-view representations to selectively retain slices with high structural relevance. This enables spatially consistent filtering across orientations while preserving contextual cues. More importantly, since standard segmentation metrics such as Dice or IoU fail to measure the spatial precision of such slice selection, we introduce a novel metric, Slice Localization Concordance (SLC), which jointly captures anatomical coverage and spatial alignment with organ-centric reference slices. Unlike segmentation-specific metrics, SLC provides a model-agnostic evaluation of localization fidelity. Our model offers substantial improvement gains against several baselines across all organs, demonstrating both accurate and reliable organ-focused slice filtering. These results show that our method enables efficient and spatially consistent organ filtering, thereby significantly reducing downstream segmentation cost while maintaining high anatomical fidelity.