 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Surgery: Zero-Shot Concept Erasure in Diffusion Models
Oct 26, 2025Concept erasure in text-to-image diffusion models is crucial for mitigating harmful content, yet existing methods often compromise generative quality. We introduce Semantic Surgery, a novel training-free, zero-shot framework for concept erasure that operates directly on text embeddings before the diffusion process. It dynamically estimates the presence of target concepts in a prompt and performs a calibrated vector subtraction to neutralize their influence at the source, enhancing both erasure completeness and locality. The framework includes a Co-Occurrence Encoding module for robust multi-concept erasure and a visual feedback loop to address latent concept persistence. As a training-free method, Semantic Surgery adapts dynamically to each prompt, ensuring precise interventions. Extensive experiments on object, explicit content, artistic style, and multi-celebrity erasure tasks show our method significantly outperforms state-of-the-art approaches. We achieve superior completeness and robustness while preserving locality and image quality (e.g., 93.58 H-score in object erasure, reducing explicit content to just 1 instance, and 8.09 H_a in style erasure with no quality degradation). This robustness also allows our framework to function as a built-in threat detection system, offering a practical solution for safer text-to-image generation.
EmotionHallucer: Evaluating Emotion Hallucinations in Multimodal Large Language Models
May 16, 2025Emotion understanding is a critical yet challenging task. Recent advances in Multimodal Large Language Models (MLLMs) have significantly enhanced their capabilities in this area. However, MLLMs often suffer from hallucinations, generating irrelevant or nonsensical content. To the best of our knowledge, despite the importance of this issue, there has been no dedicated effort to evaluate emotion-related hallucinations in MLLMs. In this work, we introduce EmotionHallucer, the first benchmark for detecting and analyzing emotion hallucinations in MLLMs. Unlike humans, whose emotion understanding stems from the interplay of biology and social learning, MLLMs rely solely on data-driven learning and lack innate emotional instincts. Fortunately, emotion psychology provides a solid foundation of knowledge about human emotions. Building on this, we assess emotion hallucinations from two dimensions: emotion psychology knowledge and real-world multimodal perception. To support robust evaluation, we utilize an adversarial binary question-answer (QA) framework, which employs carefully crafted basic and hallucinated pairs to assess the emotion hallucination tendencies of MLLMs. By evaluating 38 LLMs and MLLMs on EmotionHallucer, we reveal that: i) most current models exhibit substantial issues with emotion hallucinations; ii) closed-source models outperform open-source ones in detecting emotion hallucinations, and reasoning capability provides additional advantages; iii) existing models perform better in emotion psychology knowledge than in multimodal emotion perception. As a byproduct, these findings inspire us to propose the PEP-MEK framework, which yields an average improvement of 9.90% in emotion hallucination detection across selected models. Resources will be available at https://github.com/xxtars/EmotionHallucer.
Graph Convolutional Network with Connectivity Uncertainty for EEG-based Emotion Recognition
Oct 22, 2023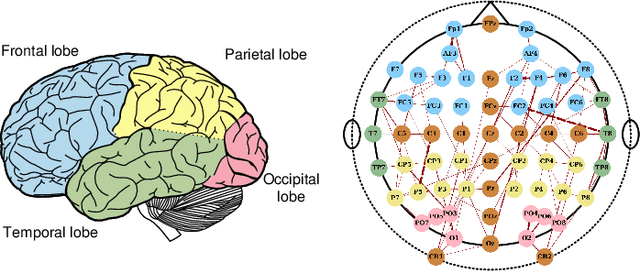
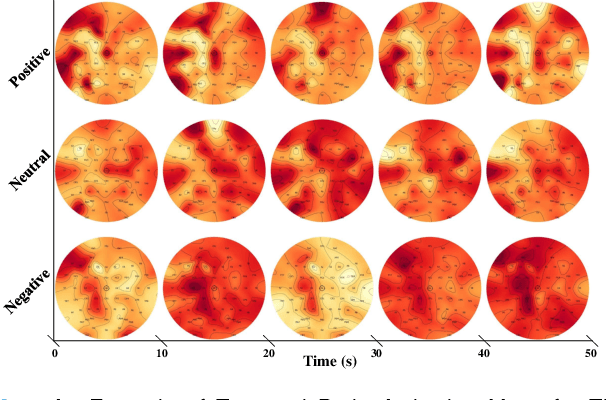
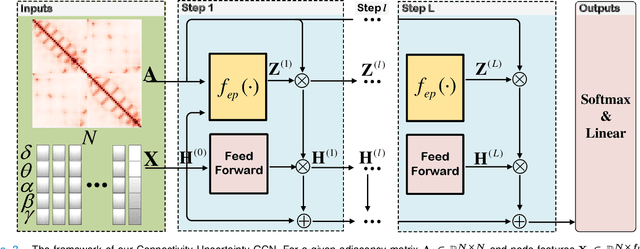

Automatic emotion recognition based on multichannel Electroencephalography (EEG) holds great potential in advancing human-computer interaction. However, several significant challenges persist in existing research on algorithmic emotion recognition. These challenges include the need for a robust model to effectively learn discriminative node attributes over long paths, the exploration of ambiguous topological information in EEG channels and effective frequency bands, and the mapping between intrinsic data qualities and provided labels. To address these challenges, this study introduces the distribution-based uncertainty method to represent spatial dependencies and temporal-spectral relativeness in EEG signals based on Graph Convolutional Network (GCN) architecture that adaptively assigns weights to functional aggregate node features, enabling effective long-path capturing while mitigating over-smoothing phenomena. Moreover, the graph mixup technique is employed to enhance latent connected edges and mitigate noisy label issues. Furthermore, we integrate the uncertainty learning method with deep GCN weights in a one-way learning fashion, termed Connectivity Uncertainty GCN (CU-GCN). We evaluate our approach on two widely used datasets, namely SEED and SEEDIV, for emotion recognition tasks. The experimental results demonstrate the superiority of our methodology over previous methods, yielding positive and significant improvements. Ablation studies confirm the substantial contributions of each component to the overall performance.
ECG-CL: A Comprehensive Electrocardiogram Interpretation Method Based on Continual Learning
Apr 10, 2023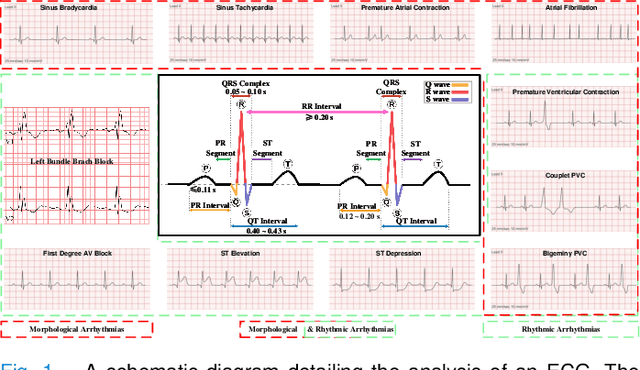
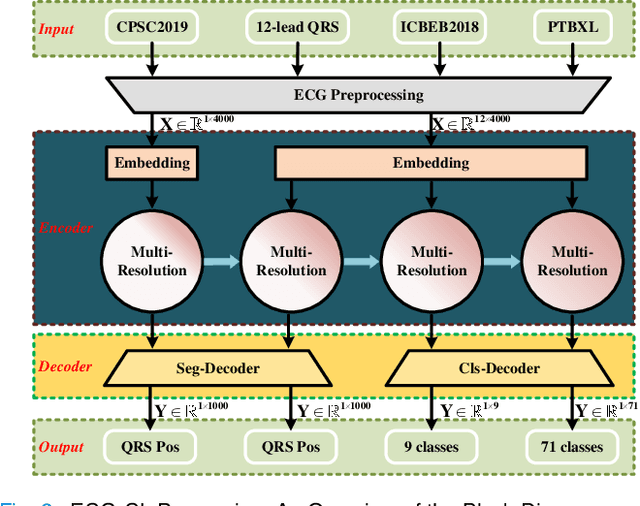
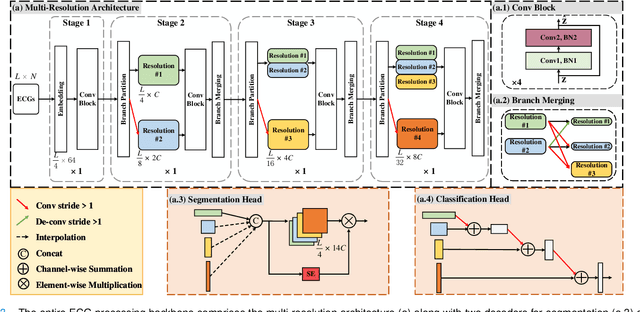
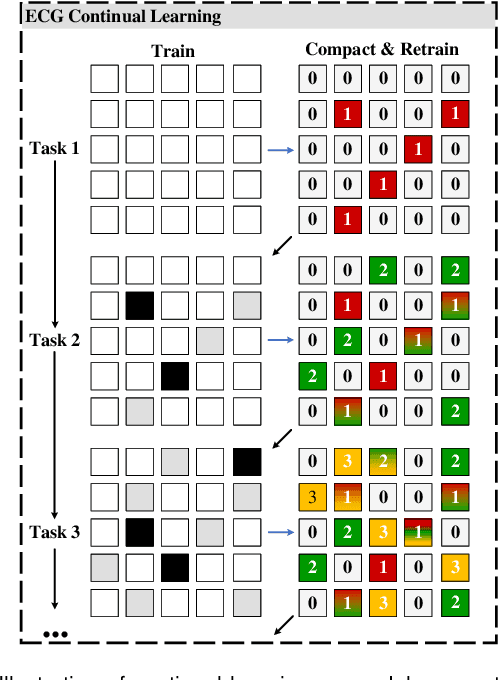
Electrocardiogram (ECG) monitoring is one of the most powerful technique of cardiovascular disease (CVD) early identification, and the introduction of intelligent wearable ECG devices has enabled daily monitoring. However, due to the need for professional expertise in the ECGs interpretation, general public access has once again been restricted, prompting the need for the development of advanced diagnostic algorithms. Classic rule-based algorithms are now completely outperformed by deep learning based methods. But the advancement of smart diagnostic algorithms is hampered by issues like small dataset, inconsistent data labeling, inefficient use of local and global ECG information, memory and inference time consuming deployment of multiple models, and lack of information transfer between tasks. We propose a multi-resolution model that can sustain high-resolution low-level semantic information throughout, with the help of the development of low-resolution high-level semantic information, by capitalizing on both local morphological information and global rhythm information. From the perspective of effective data leverage and inter-task knowledge transfer, we develop a parameter isolation based ECG continual learning (ECG-CL) approach. We evaluated our model's performance on four open-access datasets by designing segmentation-to-classification for cross-domain incremental learning, minority-to-majority class for category incremental learning, and small-to-large sample for task incremental learning. Our approach is shown to successfully extract informative morphological and rhythmic features from ECG segmentation, leading to higher quality classification results. From the perspective of intelligent wearable applications, the possibility of a comprehensive ECG interpretation algorithm based on single-lead ECGs is also confirmed.
A Causal Intervention Scheme for Semantic Segmentation of Quasi-periodic Cardiovascular Signals
Sep 19, 2022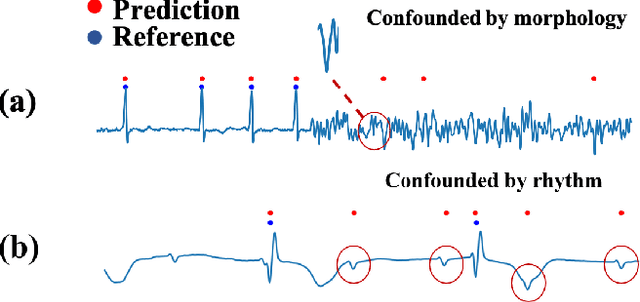
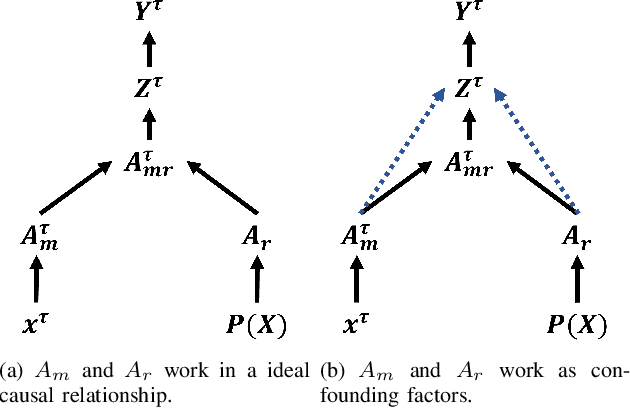
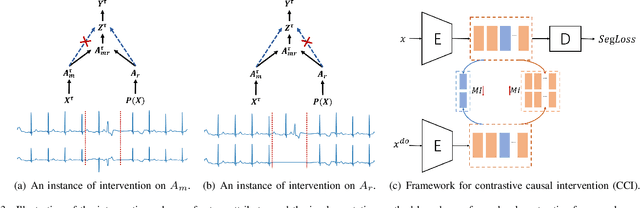
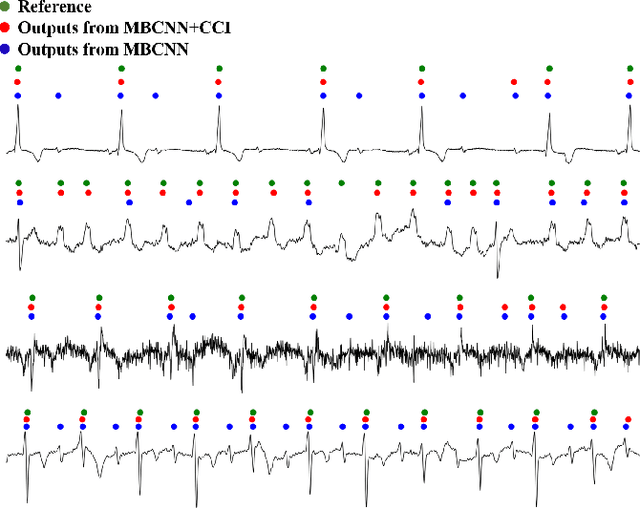
Precise segmentation is a vital first step to analyze semantic information of cardiac cycle and capture anomaly with cardiovascular signals. However, in the field of deep semantic segmentation, inference is often unilaterally confounded by the individual attribute of data. Towards cardiovascular signals, quasi-periodicity is the essential characteristic to be learned, regarded as the synthesize of the attributes of morphology (Am) and rhythm (Ar). Our key insight is to suppress the over-dependence on Am or Ar while the generation process of deep representations. To address this issue, we establish a structural causal model as the foundation to customize the intervention approaches on Am and Ar, respectively. In this paper, we propose contrastive causal intervention (CCI) to form a novel training paradigm under a frame-level contrastive framework. The intervention can eliminate the implicit statistical bias brought by the single attribute and lead to more objective representations. We conduct comprehensive experiments with the controlled condition for QRS location and heart sound segmentation. The final results indicate that our approach can evidently improve the performance by up to 0.41% for QRS location and 2.73% for heart sound segmentation. The efficiency of the proposed method is generalized to multiple databases and noisy signals.
Neural network facilitated ab initio derivation of linear formula: A case study on formulating the relationship between DNA motifs and gene expression
Aug 19, 2022

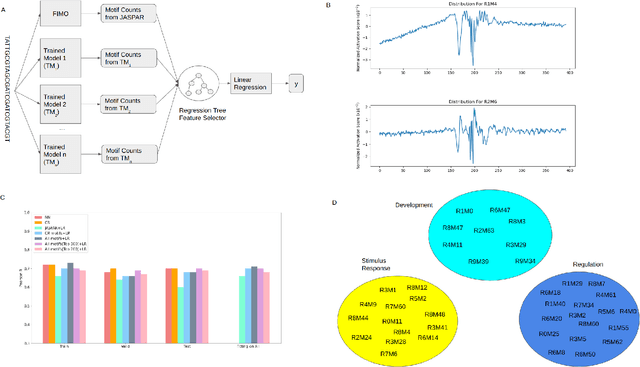

Developing models with high interpretability and even deriving formulas to quantify relationships between biological data is an emerging need. We propose here a framework for ab initio derivation of sequence motifs and linear formula using a new approach based on the interpretable neural network model called contextual regression model. We showed that this linear model could predict gene expression levels using promoter sequences with a performance comparable to deep neural network models. We uncovered a list of 300 motifs with important regulatory roles on gene expression and showed that they also had significant contributions to cell-type specific gene expression in 154 diverse cell types. This work illustrates the possibility of deriving formulas to represent biology laws that may not be easily elucidated. (https://github.com/Wang-lab-UCSD/Motif_Finding_Contextual_Regression)
Subject Envelope based Multitype Reconstruction Algorithm of Speech Samples of Parkinson's Disease
Aug 23, 2021
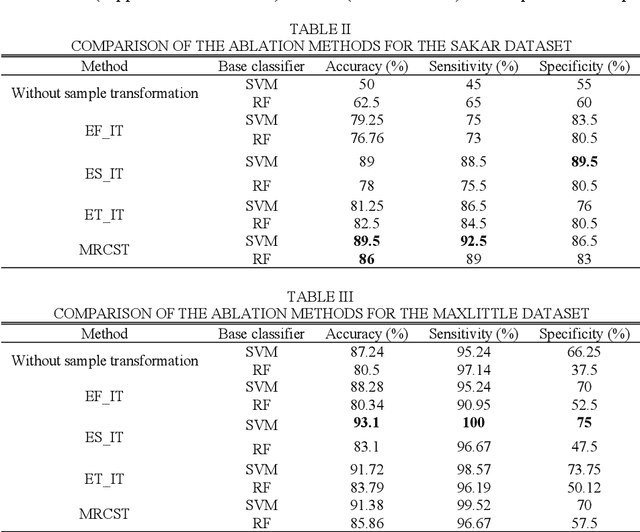

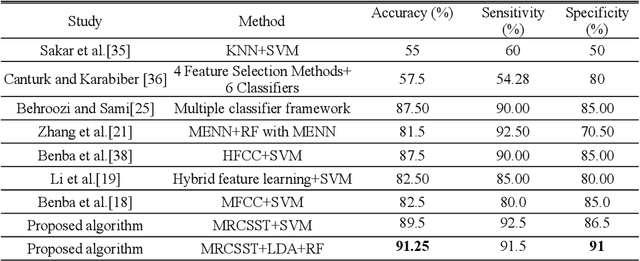
The risk of Parkinson's disease (PD) is extremely serious, and PD speech recognition is an effective method of diagnosis nowadays. However, due to the influence of the disease stage, corpus, and other factors on data collection, the ability of every samples within one subject to reflect the status of PD vary. No samples are useless totally, and not samples are 100% perfect. This characteristic means that it is not suitable just to remove some samples or keep some samples. It is necessary to consider the sample transformation for obtaining high quality new samples. Unfortunately, existing PD speech recognition methods focus mainly on feature learning and classifier design rather than sample learning, and few methods consider the sample transformation. To solve the problem above, a PD speech sample transformation algorithm based on multitype reconstruction operators is proposed in this paper. The algorithm is divided into four major steps. Three types of reconstruction operators are designed in the algorithm: types A, B and C. Concerning the type A operator, the original dataset is directly reconstructed by designing a linear transformation to obtain the first dataset. The type B operator is designed for clustering and linear transformation of the dataset to obtain the second new dataset. The third operator, namely, the type C operator, reconstructs the dataset by clustering and convolution to obtain the third dataset. Finally, the base classifier is trained based on the three new datasets, and then the classification results are fused by decision weighting. In the experimental section, two representative PD speech datasets are used for verification. The results show that the proposed algorithm is effective. Compared with other algorithms, the proposed algorithm achieves apparent improvements in terms of classification accuracy.
Active Stacking for Heart Rate Estimation
Mar 26, 2019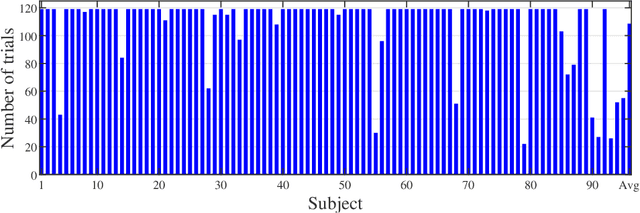
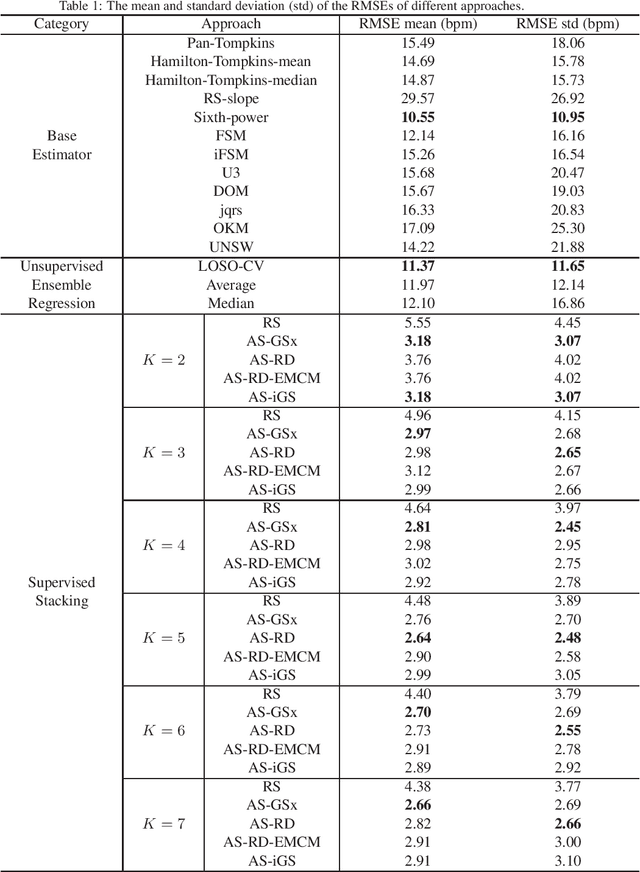
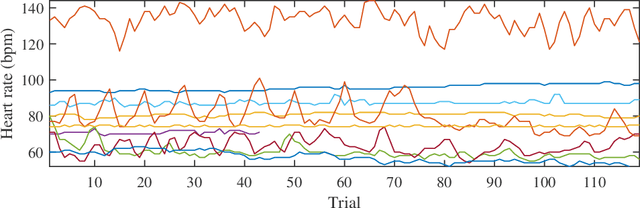
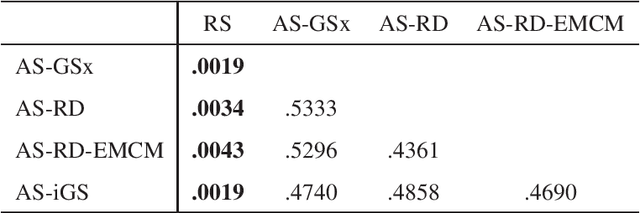
Heart rate estimation from electrocardiogram signals is very important for the early detection of cardiovascular diseases. However, due to large individual differences and varying electrocardiogram signal quality, there does not exist a single reliable estimation algorithm that works well on all subjects. Every algorithm may break down on certain subjects, resulting in a significant estimation error. Ensemble regression, which aggregates the outputs of multiple base estimators for more reliable and stable estimates, can be used to remedy this problem. Moreover, active learning can be used to optimally select a few trials from a new subject to label, based on which a stacking ensemble regression model can be trained to aggregate the base estimators. This paper proposes four active stacking approaches, and demonstrates that they all significantly outperform three common unsupervised ensemble regression approaches, and a supervised stacking approach which randomly selects some trials to label. Remarkably, our active stacking approaches only need three or four labeled trials from each subject to achieve an average root mean squared estimation error below three beats per minute, making them very convenient for real-world applications. To our knowledge, this is the first research on active stacking, and its application to heart rate estimation.
Contextual Regression: An Accurate and Conveniently Interpretable Nonlinear Model for Mining Discovery from Scientific Data
Oct 30, 2017Machine learning algorithms such as linear regression, SVM and neural network have played an increasingly important role in the process of scientific discovery. However, none of them is both interpretable and accurate on nonlinear datasets. Here we present contextual regression, a method that joins these two desirable properties together using a hybrid architecture of neural network embedding and dot product layer. We demonstrate its high prediction accuracy and sensitivity through the task of predictive feature selection on a simulated dataset and the application of predicting open chromatin sites in the human genome. On the simulated data, our method achieved high fidelity recovery of feature contributions under random noise levels up to 200%. On the open chromatin dataset, the application of our method not only outperformed the state of the art method in terms of accuracy, but also unveiled two previously unfound open chromatin related histone marks. Our method can fill the blank of accurate and interpretable nonlinear modeling in scientific data mining tasks.