 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIQuest-Coder-V1 Technical Report
Mar 17, 2026In this report, we introduce the IQuest-Coder-V1 series-(7B/14B/40B/40B-Loop), a new family of code large language models (LLMs). Moving beyond static code representations, we propose the code-flow multi-stage training paradigm, which captures the dynamic evolution of software logic through different phases of the pipeline. Our models are developed through the evolutionary pipeline, starting with the initial pre-training consisting of code facts, repository, and completion data. Following that, we implement a specialized mid-training stage that integrates reasoning and agentic trajectories in 32k-context and repository-scale in 128k-context to forge deep logical foundations. The models are then finalized with post-training of specialized coding capabilities, which is bifurcated into two specialized paths: the thinking path (utilizing reasoning-driven RL) and the instruct path (optimized for general assistance). IQuest-Coder-V1 achieves state-of-the-art performance among competitive models across critical dimensions of code intelligence: agentic software engineering, competitive programming, and complex tool use. To address deployment constraints, the IQuest-Coder-V1-Loop variant introduces a recurrent mechanism designed to optimize the trade-off between model capacity and deployment footprint, offering an architecturally enhanced path for efficacy-efficiency trade-off. We believe the release of the IQuest-Coder-V1 series, including the complete white-box chain of checkpoints from pre-training bases to the final thinking and instruction models, will advance research in autonomous code intelligence and real-world agentic systems.
Close the Loop: Synthesizing Infinite Tool-Use Data via Multi-Agent Role-Playing
Dec 29, 2025Enabling Large Language Models (LLMs) to reliably invoke external tools remains a critical bottleneck for autonomous agents. Existing approaches suffer from three fundamental challenges: expensive human annotation for high-quality trajectories, poor generalization to unseen tools, and quality ceilings inherent in single-model synthesis that perpetuate biases and coverage gaps. We introduce InfTool, a fully autonomous framework that breaks these barriers through self-evolving multi-agent synthesis. Given only raw API specifications, InfTool orchestrates three collaborative agents (User Simulator, Tool-Calling Assistant, and MCP Server) to generate diverse, verified trajectories spanning single-turn calls to complex multi-step workflows. The framework establishes a closed loop: synthesized data trains the model via Group Relative Policy Optimization (GRPO) with gated rewards, the improved model generates higher-quality data targeting capability gaps, and this cycle iterates without human intervention. Experiments on the Berkeley Function-Calling Leaderboard (BFCL) demonstrate that InfTool transforms a base 32B model from 19.8% to 70.9% accuracy (+258%), surpassing models 10x larger and rivaling Claude-Opus, and entirely from synthetic data without human annotation.
Investigating Vulnerabilities and Defenses Against Audio-Visual Attacks: A Comprehensive Survey Emphasizing Multimodal Models
Jun 13, 2025Multimodal large language models (MLLMs), which bridge the gap between audio-visual and natural language processing, achieve state-of-the-art performance on several audio-visual tasks. Despite the superior performance of MLLMs, the scarcity of high-quality audio-visual training data and computational resources necessitates the utilization of third-party data and open-source MLLMs, a trend that is increasingly observed in contemporary research. This prosperity masks significant security risks. Empirical studies demonstrate that the latest MLLMs can be manipulated to produce malicious or harmful content. This manipulation is facilitated exclusively through instructions or inputs, including adversarial perturbations and malevolent queries, effectively bypassing the internal security mechanisms embedded within the models. To gain a deeper comprehension of the inherent security vulnerabilities associated with audio-visual-based multimodal models, a series of surveys investigates various types of attacks, including adversarial and backdoor attacks. While existing surveys on audio-visual attacks provide a comprehensive overview, they are limited to specific types of attacks, which lack a unified review of various types of attacks. To address this issue and gain insights into the latest trends in the field, this paper presents a comprehensive and systematic review of audio-visual attacks, which include adversarial attacks, backdoor attacks, and jailbreak attacks. Furthermore, this paper also reviews various types of attacks in the latest audio-visual-based MLLMs, a dimension notably absent in existing surveys. Drawing upon comprehensive insights from a substantial review, this paper delineates both challenges and emergent trends for future research on audio-visual attacks and defense.
Higher Order Approximation Rates for ReLU CNNs in Korobov Spaces
Jan 20, 2025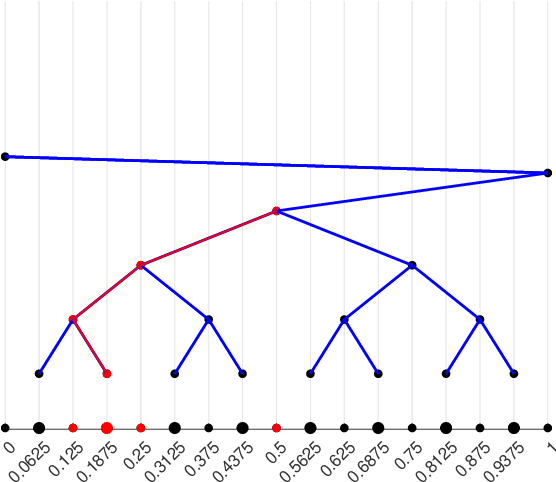
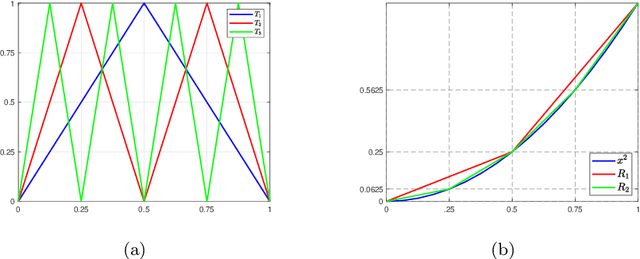
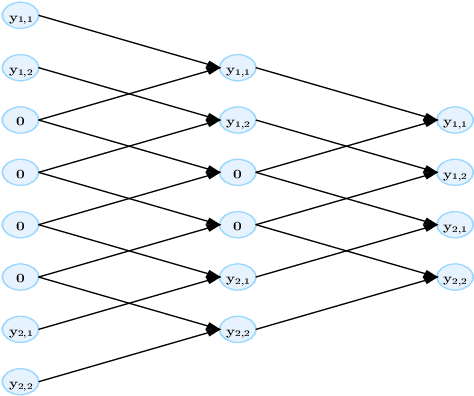
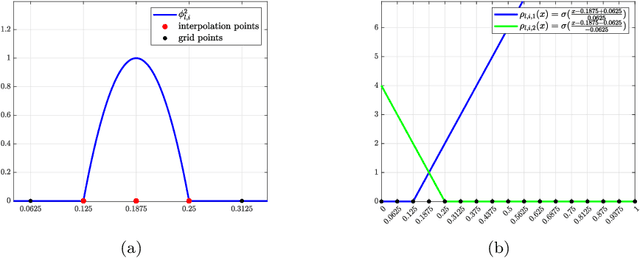
This paper investigates the $L_p$ approximation error for higher order Korobov functions using deep convolutional neural networks (CNNs) with ReLU activation. For target functions having a mixed derivative of order m+1 in each direction, we improve classical approximation rate of second order to (m+1)-th order (modulo a logarithmic factor) in terms of the depth of CNNs. The key ingredient in our analysis is approximate representation of high-order sparse grid basis functions by CNNs. The results suggest that higher order expressivity of CNNs does not severely suffer from the curse of dimensionality.
GraphCleaner: Detecting Mislabelled Samples in Popular Graph Learning Benchmarks
May 30, 2023



Label errors have been found to be prevalent in popular text, vision, and audio datasets, which heavily influence the safe development and evaluation of machine learning algorithms. Despite increasing efforts towards improving the quality of generic data types, such as images and texts, the problem of mislabel detection in graph data remains underexplored. To bridge the gap, we explore mislabelling issues in popular real-world graph datasets and propose GraphCleaner, a post-hoc method to detect and correct these mislabelled nodes in graph datasets. GraphCleaner combines the novel ideas of 1) Synthetic Mislabel Dataset Generation, which seeks to generate realistic mislabels; and 2) Neighborhood-Aware Mislabel Detection, where neighborhood dependency is exploited in both labels and base classifier predictions. Empirical evaluations on 6 datasets and 6 experimental settings demonstrate that GraphCleaner outperforms the closest baseline, with an average improvement of 0.14 in F1 score, and 0.16 in MCC. On real-data case studies, GraphCleaner detects real and previously unknown mislabels in popular graph benchmarks: PubMed, Cora, CiteSeer and OGB-arxiv; we find that at least 6.91% of PubMed data is mislabelled or ambiguous, and simply removing these mislabelled data can boost evaluation performance from 86.71% to 89.11%.
Single Image Deraining via Rain-Steaks Aware Deep Convolutional Neural Network
Sep 20, 2022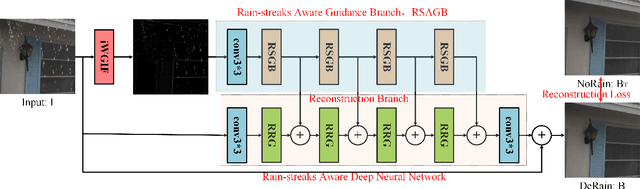
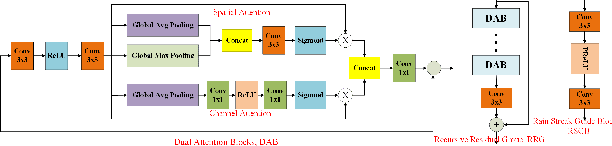
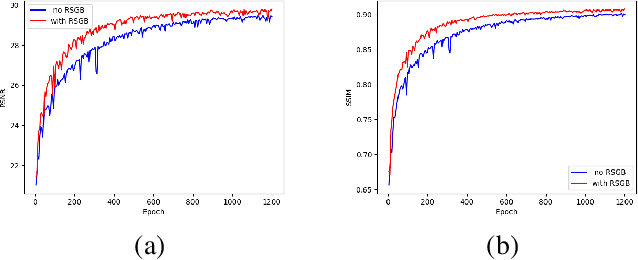

It is challenging to remove rain-steaks from a single rainy image because the rain steaks are spatially varying in the rainy image. This problem is studied in this paper by combining conventional image processing techniques and deep learning based techniques. An improved weighted guided image filter (iWGIF) is proposed to extract high frequency information from a rainy image. The high frequency information mainly includes rain steaks and noise, and it can guide the rain steaks aware deep convolutional neural network (RSADCNN) to pay more attention to rain steaks. The efficiency and explain-ability of RSADNN are improved. Experiments show that the proposed algorithm significantly outperforms state-of-the-art methods on both synthetic and real-world images in terms of both qualitative and quantitative measures. It is useful for autonomous navigation in raining conditions.
A Causal Intervention Scheme for Semantic Segmentation of Quasi-periodic Cardiovascular Signals
Sep 19, 2022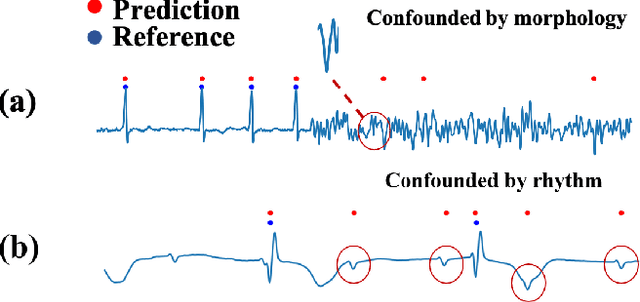
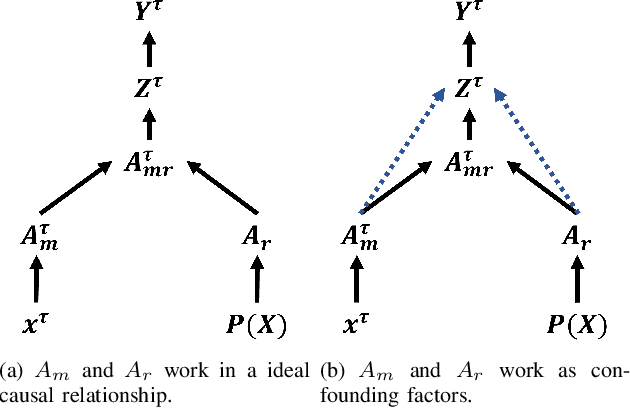
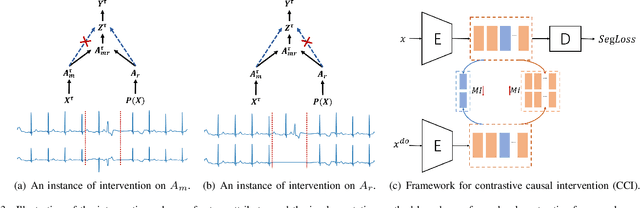
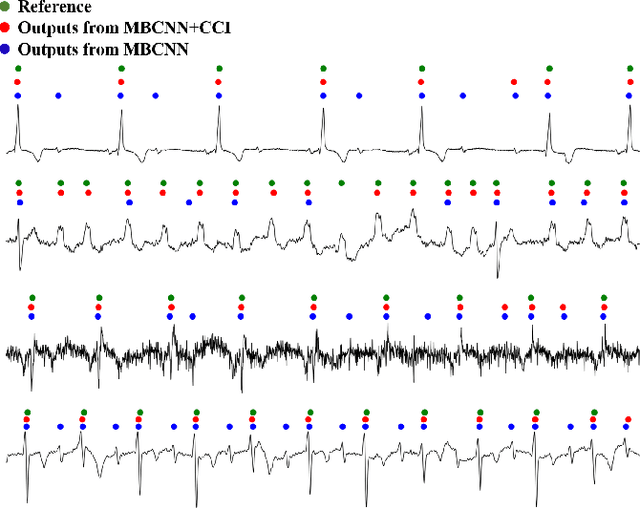
Precise segmentation is a vital first step to analyze semantic information of cardiac cycle and capture anomaly with cardiovascular signals. However, in the field of deep semantic segmentation, inference is often unilaterally confounded by the individual attribute of data. Towards cardiovascular signals, quasi-periodicity is the essential characteristic to be learned, regarded as the synthesize of the attributes of morphology (Am) and rhythm (Ar). Our key insight is to suppress the over-dependence on Am or Ar while the generation process of deep representations. To address this issue, we establish a structural causal model as the foundation to customize the intervention approaches on Am and Ar, respectively. In this paper, we propose contrastive causal intervention (CCI) to form a novel training paradigm under a frame-level contrastive framework. The intervention can eliminate the implicit statistical bias brought by the single attribute and lead to more objective representations. We conduct comprehensive experiments with the controlled condition for QRS location and heart sound segmentation. The final results indicate that our approach can evidently improve the performance by up to 0.41% for QRS location and 2.73% for heart sound segmentation. The efficiency of the proposed method is generalized to multiple databases and noisy signals.
Adaptive Weighted Guided Image Filtering for Depth Enhancement in Shape-From-Focus
Jan 18, 2022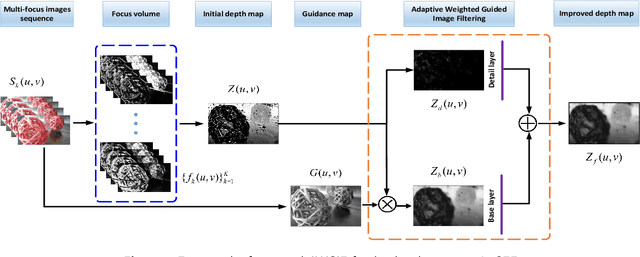



Existing shape from focus (SFF) techniques cannot preserve depth edges and fine structural details from a sequence of multi-focus images. Moreover, noise in the sequence of multi-focus images affects the accuracy of the depth map. In this paper, a novel depth enhancement algorithm for the SFF based on an adaptive weighted guided image filtering (AWGIF) is proposed to address the above issues. The AWGIF is applied to decompose an initial depth map which is estimated by the traditional SFF into a base layer and a detail layer. In order to preserve the edges accurately in the refined depth map, the guidance image is constructed from the multi-focus image sequence, and the coefficient of the AWGIF is utilized to suppress the noise while enhancing the fine depth details. Experiments on real and synthetic objects demonstrate the superiority of the proposed algorithm in terms of anti-noise, and the ability to preserve depth edges and fine structural details compared to existing methods.
Single image dehazing via combining the prior knowledge and CNNs
Nov 14, 2021
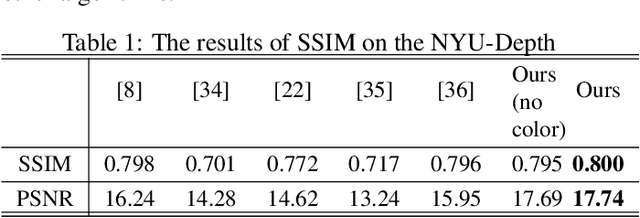
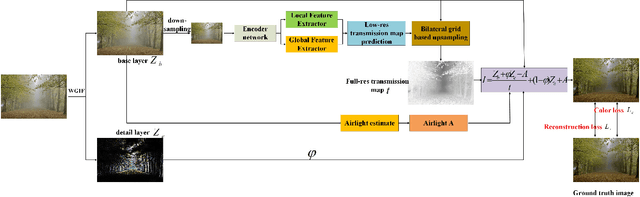

Aiming at the existing single image haze removal algorithms, which are based on prior knowledge and assumptions, subject to many limitations in practical applications, and could suffer from noise and halo amplification. An end-to-end system is proposed in this paper to reduce defects by combining the prior knowledge and deep learning method. The haze image is decomposed into the base layer and detail layers through a weighted guided image filter (WGIF) firstly, and the airlight is estimated from the base layer. Then, the base layer image is passed to the efficient deep convolutional network for estimating the transmission map. To restore object close to the camera completely without amplifying noise in sky or heavily hazy scene, an adaptive strategy is proposed based on the value of the transmission map. If the transmission map of a pixel is small, the base layer of the haze image is used to recover a haze-free image via atmospheric scattering model, finally. Otherwise, the haze image is used. Experiments show that the proposed method achieves superior performance over existing methods.
Neural networks with trainable matrix activation functions
Oct 06, 2021
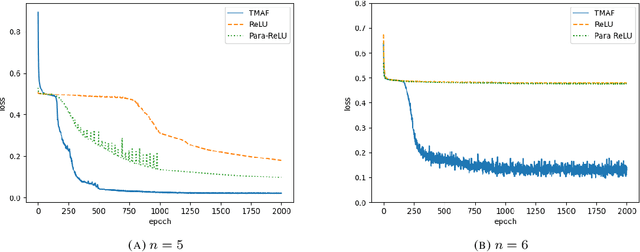
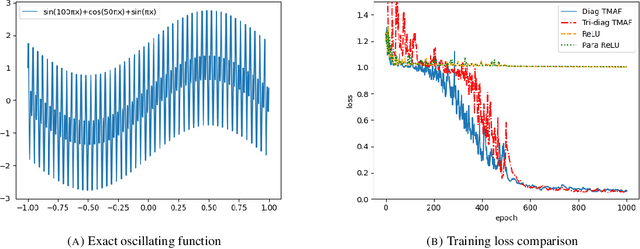
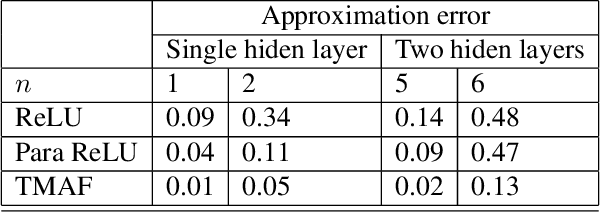
The training process of neural networks usually optimize weights and bias parameters of linear transformations, while nonlinear activation functions are pre-specified and fixed. This work develops a systematic approach to constructing matrix activation functions whose entries are generalized from ReLU. The activation is based on matrix-vector multiplications using only scalar multiplications and comparisons. The proposed activation functions depend on parameters that are trained along with the weights and bias vectors. Neural networks based on this approach are simple and efficient and are shown to be robust in numerical experiments.