 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChronoPhyBench: Do MLLMs Truly Understand the World or Merely Exploit Language Priors?
Jun 06, 2026Recent advancements in Multimodal Large Language Models (MLLMs) have demonstrated remarkable proficiency in open-world reasoning and understanding. However, a critical ambiguity persists: it remains unclear whether these models genuinely synthesize cross-modal information to construct physically grounded reasoning chains, or if they merely exploit strong language priors to mask single-modality reliance, thereby hallucinating advanced multimodal capabilities. Motivated by this, and to rigorously mitigate language modality bias and shortcuts, we propose a novel multimodal Chrono}logical Physical Dynamics Reasoning Benchmark ChronoPhyBench, which unifies next state prediction with Visual Question Answering (VQA) paradigms by conditioning on historical video context and textual captions to enforce models to deduce subsequent physical states through both single image selection and the inherently more complex task of multiple frame chronological sorting. Concurrently, we construct a large-scale multimodal reasoning dataset curated using the ChronoPhyBench criteria, comprising over 10,000 long-form videos paired with meticulously annotated captions, totaling 5M tokens. Our experimental evaluations reveal a stark contrast to conclusions drawn by previous benchmarks. The capacity of current open-source models to perform physically grounded multimodal reasoning remains in its infancy. Ultimately, this work seeks to systematically stress-test the reasoning capabilities of multimodal models, quantify hallucination rates, and advance the development of Physical AI, thereby providing the community with a robust and transparent evaluation framework toward Artificial General Intelligence (AGI).
Understanding and Preventing Entropy Collapse in RLVR with On-Policy Entropy Flow Optimization
May 12, 2026Reinforcement learning with verifiable rewards (RLVR) has become an effective paradigm for improving the reasoning ability of large language models. However, widely used RLVR algorithms, such as GRPO, often suffer from entropy collapse, leading to premature determinism and unstable optimization. Existing remedies, including entropy regularization and ratio-based clipping heuristics, either control entropy in a coarse-grained manner or rely on approximate on-policy training. In this paper, we revisit entropy collapse from a token-level entropy flow perspective. Our analysis reveals that entropy-decreasing tokens consistently outweigh entropy-increasing ones, resulting in a severely imbalanced entropy flow. This perspective provides a unified explanation of entropy collapse in existing RLVR algorithms and highlights the importance of balancing entropy dynamics. Motivated by this analysis, we propose On-Policy Entropy Flow Optimization (OPEFO), an adaptive entropy flow balancing mechanism that rescales entropy-increasing and entropy-decreasing updates according to their contributions to entropy change, while remaining strict on-policy. Experiments on six mathematical reasoning benchmarks demonstrate that OPEFO improves training stability and final performance. We will release the code and models upon publication.
EduStory: A Unified Framework for Pedagogically-Consistent Multi-Shot STEM Instructional Video Generation
May 10, 2026Long-horizon video generation has advanced in visual quality, yet existing methods still struggle to maintain knowledge consistency and coherent pedagogical narratives across multi-shot instructional videos, especially in STEM domains. To address these challenges, we propose EduStory, a unified framework for reliable instructional video generation. EduStory integrates pedagogical state modeling to track persistent knowledge states, script-guided structured control to organize multi-shot narratives, and learning-oriented evaluation metrics to assess knowledge fidelity and constraint satisfaction. To support rigorous evaluation, we further introduce EduVideoBench, a diagnostic benchmark with multi-granularity annotations, including pedagogical storyboards, shot-level semantics, and knowledge state transitions, together with baseline tasks for controllable instructional video generation. Extensive experiments demonstrate that domain-aware state modeling and structured control substantially reduce narrative breakdown and improve alignment with instructional intent. These results highlight the significance of domain-specific structural constraints and tailored benchmarks for advancing reliable, controllable, and also trustworthy long-horizon video generation.
Self-Debias: Self-correcting for Debiasing Large Language Models
Apr 09, 2026Although Large Language Models (LLMs) demonstrate remarkable reasoning capabilities, inherent social biases often cascade throughout the Chain-of-Thought (CoT) process, leading to continuous "Bias Propagation". Existing debiasing methods primarily focus on static constraints or external interventions, failing to identify and interrupt this propagation once triggered. To address this limitation, we introduce Self-Debias, a progressive framework designed to instill intrinsic self-correction capabilities. Specifically, we reformulate the debiasing process as a strategic resource redistribution problem, treating the model's output probability mass as a limited resource to be reallocated from biased heuristics to unbiased reasoning paths. Unlike standard preference optimization which applies broad penalties, Self-Debias employs a fine-grained trajectory-level objective subject to dynamic debiasing constraints. This enables the model to selectively revise biased reasoning suffixes while preserving valid contextual prefixes. Furthermore, we integrate an online self-improvement mechanism utilizing consistency filtering to autonomously synthesize supervision signals. With merely 20k annotated samples, Self-Debias activates efficient self-correction, achieving superior debiasing performance while preserving general reasoning capabilities without continuous external oversight.
Physics-Aligned Spectral Mamba: Decoupling Semantics and Dynamics for Few-Shot Hyperspectral Target Detection
Apr 07, 2026Meta-learning facilitates few-shot hyperspectral target detection (HTD), but adapting deep backbones remains challenging. Full-parameter fine-tuning is inefficient and prone to overfitting, and existing methods largely ignore the frequency-domain structure and spectral band continuity of hyperspectral data, limiting spectral adaptation and cross-domain generalization.To address these challenges, we propose SpecMamba, a parameter-efficient and frequency-aware framework that decouples stable semantic representation from agile spectral adaptation. Specifically, we introduce a Discrete Cosine Transform Mamba Adapter (DCTMA) on top of frozen Transformer representations. By projecting spectral features into the frequency domain via DCT and leveraging Mamba's linear-complexity state-space recursion, DCTMA explicitly captures global spectral dependencies and band continuity while avoiding the redundancy of full fine-tuning. Furthermore, to address prototype drift caused by limited sample sizes, we design a Prior-Guided Tri-Encoder (PGTE) that allows laboratory spectral priors to guide the optimization of the learnable adapter without disrupting the stable semantic feature space. Finally, a Self-Supervised Pseudo-Label Mapping (SSPLM) strategy is developed for test-time adaptation, enabling efficient decision boundary refinement through uncertainty-aware sampling and dual-path consistency constraints. Extensive experiments on multiple public datasets demonstrate that SpecMamba consistently outperforms state-of-the-art methods in detection accuracy and cross-domain generalization.
NS-VLA: Towards Neuro-Symbolic Vision-Language-Action Models
Mar 10, 2026Vision-Language-Action (VLA) models are formulated to ground instructions in visual context and generate action sequences for robotic manipulation. Despite recent progress, VLA models still face challenges in learning related and reusable primitives, reducing reliance on large-scale data and complex architectures, and enabling exploration beyond demonstrations. To address these challenges, we propose a novel Neuro-Symbolic Vision-Language-Action (NS-VLA) framework via online reinforcement learning (RL). It introduces a symbolic encoder to embedding vision and language features and extract structured primitives, utilizes a symbolic solver for data-efficient action sequencing, and leverages online RL to optimize generation via expansive exploration. Experiments on robotic manipulation benchmarks demonstrate that NS-VLA outperforms previous methods in both one-shot training and data-perturbed settings, while simultaneously exhibiting superior zero-shot generalizability, high data efficiency and expanded exploration space. Our code is available.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Global Context Compression with Interleaved Vision-Text Transformation
Jan 15, 2026Recent achievements of vision-language models in end-to-end OCR point to a new avenue for low-loss compression of textual information. This motivates earlier works that render the Transformer's input into images for prefilling, which effectively reduces the number of tokens through visual encoding, thereby alleviating the quadratically increased Attention computations. However, this partial compression fails to save computational or memory costs at token-by-token inference. In this paper, we investigate global context compression, which saves tokens at both prefilling and inference stages. Consequently, we propose VIST2, a novel Transformer that interleaves input text chunks alongside their visual encoding, while depending exclusively on visual tokens in the pre-context to predict the next text token distribution. Around this idea, we render text chunks into sketch images and train VIST2 in multiple stages, starting from curriculum-scheduled pretraining for optical language modeling, followed by modal-interleaved instruction tuning. We conduct extensive experiments using VIST2 families scaled from 0.6B to 8B to explore the training recipe and hyperparameters. With a 4$\times$ compression ratio, the resulting models demonstrate significant superiority over baselines on long writing tasks, achieving, on average, a 3$\times$ speedup in first-token generation, 77% reduction in memory usage, and 74% reduction in FLOPS. Our codes and datasets will be public to support further studies.
C2PO: Diagnosing and Disentangling Bias Shortcuts in LLMs
Dec 29, 2025Bias in Large Language Models (LLMs) poses significant risks to trustworthiness, manifesting primarily as stereotypical biases (e.g., gender or racial stereotypes) and structural biases (e.g., lexical overlap or position preferences). However, prior paradigms typically address these in isolation, often mitigating one at the expense of exacerbating the other. To address this, we conduct a systematic exploration of these reasoning failures and identify a primary inducement: the latent spurious feature correlations within the input that drive these erroneous reasoning shortcuts. Driven by these findings, we introduce Causal-Contrastive Preference Optimization (C2PO), a unified alignment framework designed to tackle these specific failures by simultaneously discovering and suppressing these correlations directly within the optimization process. Specifically, C2PO leverages causal counterfactual signals to isolate bias-inducing features from valid reasoning paths, and employs a fairness-sensitive preference update mechanism to dynamically evaluate logit-level contributions and suppress shortcut features. Extensive experiments across multiple benchmarks covering stereotypical bias (BBQ, Unqover), structural bias (MNLI, HANS, Chatbot, MT-Bench), out-of-domain fairness (StereoSet, WinoBias), and general utility (MMLU, GSM8K) demonstrate that C2PO effectively mitigates stereotypical and structural biases while preserving robust general reasoning capabilities.
E-Navi: Environmental Adaptive Navigation for UAVs on Resource Constrained Platforms
Dec 16, 2025
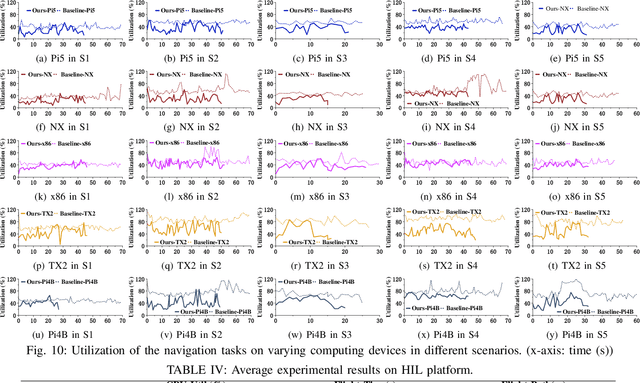
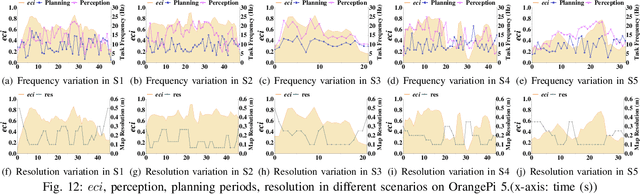
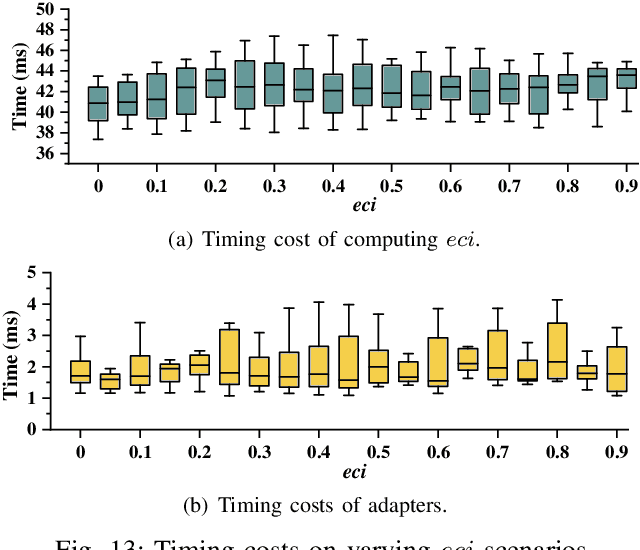
The ability to adapt to changing environments is crucial for the autonomous navigation systems of Unmanned Aerial Vehicles (UAVs). However, existing navigation systems adopt fixed execution configurations without considering environmental dynamics based on available computing resources, e.g., with a high execution frequency and task workload. This static approach causes rigid flight strategies and excessive computations, ultimately degrading flight performance or even leading to failures in UAVs. Despite the necessity for an adaptive system, dynamically adjusting workloads remains challenging, due to difficulties in quantifying environmental complexity and modeling the relationship between environment and system configuration. Aiming at adapting to dynamic environments, this paper proposes E-Navi, an environmental-adaptive navigation system for UAVs that dynamically adjusts task executions on the CPUs in response to environmental changes based on available computational resources. Specifically, the perception-planning pipeline of UAVs navigation system is redesigned through dynamic adaptation of mapping resolution and execution frequency, driven by the quantitative environmental complexity evaluations. In addition, E-Navi supports flexible deployment across hardware platforms with varying levels of computing capability. Extensive Hardware-In-the-Loop and real-world experiments demonstrate that the proposed system significantly outperforms the baseline method across various hardware platforms, achieving up to 53.9% navigation task workload reduction, up to 63.8% flight time savings, and delivering more stable velocity control.