 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Debias: Self-correcting for Debiasing Large Language Models
Apr 09, 2026Although Large Language Models (LLMs) demonstrate remarkable reasoning capabilities, inherent social biases often cascade throughout the Chain-of-Thought (CoT) process, leading to continuous "Bias Propagation". Existing debiasing methods primarily focus on static constraints or external interventions, failing to identify and interrupt this propagation once triggered. To address this limitation, we introduce Self-Debias, a progressive framework designed to instill intrinsic self-correction capabilities. Specifically, we reformulate the debiasing process as a strategic resource redistribution problem, treating the model's output probability mass as a limited resource to be reallocated from biased heuristics to unbiased reasoning paths. Unlike standard preference optimization which applies broad penalties, Self-Debias employs a fine-grained trajectory-level objective subject to dynamic debiasing constraints. This enables the model to selectively revise biased reasoning suffixes while preserving valid contextual prefixes. Furthermore, we integrate an online self-improvement mechanism utilizing consistency filtering to autonomously synthesize supervision signals. With merely 20k annotated samples, Self-Debias activates efficient self-correction, achieving superior debiasing performance while preserving general reasoning capabilities without continuous external oversight.
OmniSapiens: A Foundation Model for Social Behavior Processing via Heterogeneity-Aware Relative Policy Optimization
Feb 11, 2026To develop socially intelligent AI, existing approaches typically model human behavioral dimensions (e.g., affective, cognitive, or social attributes) in isolation. Although useful, task-specific modeling often increases training costs and limits generalization across behavioral settings. Recent reasoning RL methods facilitate training a single unified model across multiple behavioral tasks, but do not explicitly address learning across different heterogeneous behavioral data. To address this gap, we introduce Heterogeneity-Aware Relative Policy Optimization (HARPO), an RL method that balances leaning across heterogeneous tasks and samples. This is achieved by modulating advantages to ensure that no single task or sample carries disproportionate influence during policy optimization. Using HARPO, we develop and release Omnisapiens-7B 2.0, a foundation model for social behavior processing. Relative to existing behavioral foundation models, Omnisapiens-7B 2.0 achieves the strongest performance across behavioral tasks, with gains of up to +16.85% and +9.37% on multitask and held-out settings respectively, while producing more explicit and robust reasoning traces. We also validate HARPO against recent RL methods, where it achieves the most consistently strong performance across behavioral tasks.
Affective Flow Language Model for Emotional Support Conversation
Feb 09, 2026Large language models (LLMs) have been widely applied to emotional support conversation (ESC). However, complex multi-turn support remains challenging.This is because existing alignment schemes rely on sparse outcome-level signals, thus offering limited supervision for intermediate strategy decisions. To fill this gap, this paper proposes affective flow language model for emotional support conversation (AFlow), a framework that introduces fine-grained supervision on dialogue prefixes by modeling a continuous affective flow along multi-turn trajectories. AFlow can estimate intermediate utility over searched trajectories and learn preference-consistent strategy transitions. To improve strategy coherence and empathetic response quality, a subpath-level flow-balance objective is presented to propagate preference signals to intermediate states. Experiment results show consistent and significant improvements over competitive baselines in diverse emotional contexts. Remarkably, AFlow with a compact open-source backbone outperforms proprietary LMMs such as GPT-4o and Claude-3.5 on major ESC metrics. Our code is available at https://github.com/chzou25-lgtm/AffectiveFlow.
Exploring Cognitive and Aesthetic Causality for Multimodal Aspect-Based Sentiment Analysis
Apr 22, 2025



Multimodal aspect-based sentiment classification (MASC) is an emerging task due to an increase in user-generated multimodal content on social platforms, aimed at predicting sentiment polarity toward specific aspect targets (i.e., entities or attributes explicitly mentioned in text-image pairs). Despite extensive efforts and significant achievements in existing MASC, substantial gaps remain in understanding fine-grained visual content and the cognitive rationales derived from semantic content and impressions (cognitive interpretations of emotions evoked by image content). In this study, we present Chimera: a cognitive and aesthetic sentiment causality understanding framework to derive fine-grained holistic features of aspects and infer the fundamental drivers of sentiment expression from both semantic perspectives and affective-cognitive resonance (the synergistic effect between emotional responses and cognitive interpretations). Specifically, this framework first incorporates visual patch features for patch-word alignment. Meanwhile, it extracts coarse-grained visual features (e.g., overall image representation) and fine-grained visual regions (e.g., aspect-related regions) and translates them into corresponding textual descriptions (e.g., facial, aesthetic). Finally, we leverage the sentimental causes and impressions generated by a large language model (LLM) to enhance the model's awareness of sentimental cues evoked by semantic content and affective-cognitive resonance. Experimental results on standard MASC datasets demonstrate the effectiveness of the proposed model, which also exhibits greater flexibility to MASC compared to LLMs such as GPT-4o. We have publicly released the complete implementation and dataset at https://github.com/Xillv/Chimera
Aspect-Based Summarization with Self-Aspect Retrieval Enhanced Generation
Apr 17, 2025Aspect-based summarization aims to generate summaries tailored to specific aspects, addressing the resource constraints and limited generalizability of traditional summarization approaches. Recently, large language models have shown promise in this task without the need for training. However, they rely excessively on prompt engineering and face token limits and hallucination challenges, especially with in-context learning. To address these challenges, in this paper, we propose a novel framework for aspect-based summarization: Self-Aspect Retrieval Enhanced Summary Generation. Rather than relying solely on in-context learning, given an aspect, we employ an embedding-driven retrieval mechanism to identify its relevant text segments. This approach extracts the pertinent content while avoiding unnecessary details, thereby mitigating the challenge of token limits. Moreover, our framework optimizes token usage by deleting unrelated parts of the text and ensuring that the model generates output strictly based on the given aspect. With extensive experiments on benchmark datasets, we demonstrate that our framework not only achieves superior performance but also effectively mitigates the token limitation problem.
Weak-To-Strong Backdoor Attacks for LLMs with Contrastive Knowledge Distillation
Sep 26, 2024Despite being widely applied due to their exceptional capabilities, Large Language Models (LLMs) have been proven to be vulnerable to backdoor attacks. These attacks introduce targeted vulnerabilities into LLMs by poisoning training samples and full-parameter fine-tuning. However, this kind of backdoor attack is limited since they require significant computational resources, especially as the size of LLMs increases. Besides, parameter-efficient fine-tuning (PEFT) offers an alternative but the restricted parameter updating may impede the alignment of triggers with target labels. In this study, we first verify that backdoor attacks with PEFT may encounter challenges in achieving feasible performance. To address these issues and improve the effectiveness of backdoor attacks with PEFT, we propose a novel backdoor attack algorithm from weak to strong based on contrastive knowledge distillation (W2SAttack). Specifically, we poison small-scale language models through full-parameter fine-tuning to serve as the teacher model. The teacher model then covertly transfers the backdoor to the large-scale student model through contrastive knowledge distillation, which employs PEFT. Theoretical analysis reveals that W2SAttack has the potential to augment the effectiveness of backdoor attacks. We demonstrate the superior performance of W2SAttack on classification tasks across four language models, four backdoor attack algorithms, and two different architectures of teacher models. Experimental results indicate success rates close to 100% for backdoor attacks targeting PEFT.
DCQA: Document-Level Chart Question Answering towards Complex Reasoning and Common-Sense Understanding
Oct 29, 2023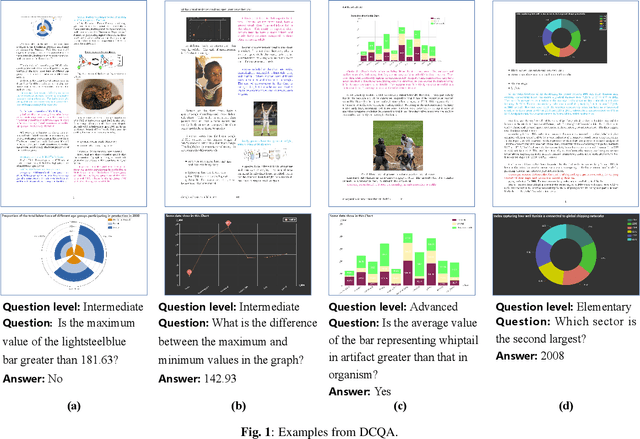
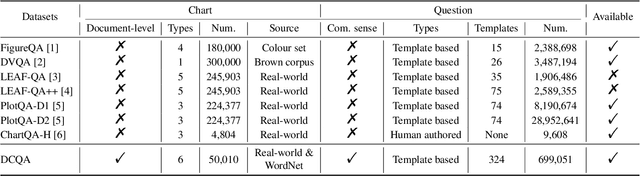
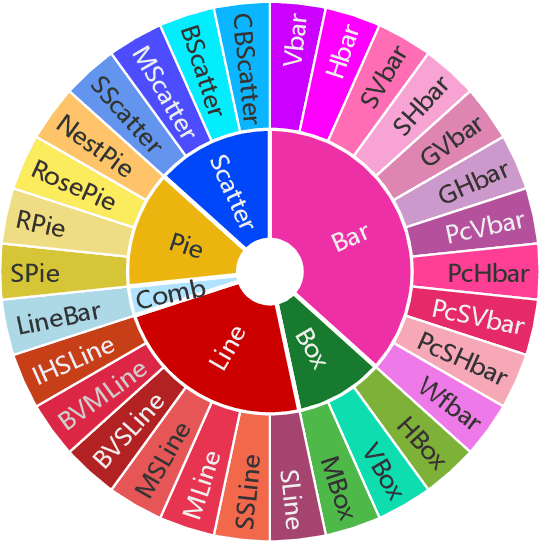

Visually-situated languages such as charts and plots are omnipresent in real-world documents. These graphical depictions are human-readable and are often analyzed in visually-rich documents to address a variety of questions that necessitate complex reasoning and common-sense responses. Despite the growing number of datasets that aim to answer questions over charts, most only address this task in isolation, without considering the broader context of document-level question answering. Moreover, such datasets lack adequate common-sense reasoning information in their questions. In this work, we introduce a novel task named document-level chart question answering (DCQA). The goal of this task is to conduct document-level question answering, extracting charts or plots in the document via document layout analysis (DLA) first and subsequently performing chart question answering (CQA). The newly developed benchmark dataset comprises 50,010 synthetic documents integrating charts in a wide range of styles (6 styles in contrast to 3 for PlotQA and ChartQA) and includes 699,051 questions that demand a high degree of reasoning ability and common-sense understanding. Besides, we present the development of a potent question-answer generation engine that employs table data, a rich color set, and basic question templates to produce a vast array of reasoning question-answer pairs automatically. Based on DCQA, we devise an OCR-free transformer for document-level chart-oriented understanding, capable of DLA and answering complex reasoning and common-sense questions over charts in an OCR-free manner. Our DCQA dataset is expected to foster research on understanding visualizations in documents, especially for scenarios that require complex reasoning for charts in the visually-rich document. We implement and evaluate a set of baselines, and our proposed method achieves comparable results.
Progressive Evidence Refinement for Open-domain Multimodal Retrieval Question Answering
Oct 15, 2023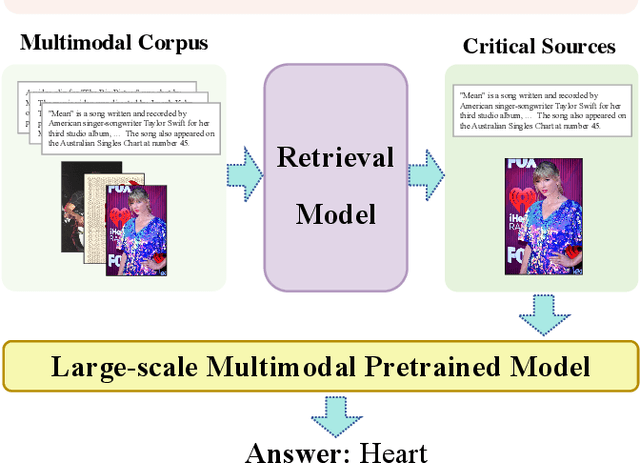

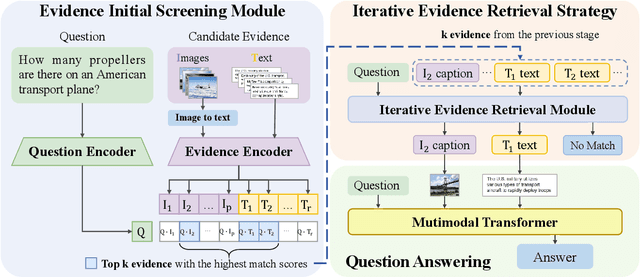
Pre-trained multimodal models have achieved significant success in retrieval-based question answering. However, current multimodal retrieval question-answering models face two main challenges. Firstly, utilizing compressed evidence features as input to the model results in the loss of fine-grained information within the evidence. Secondly, a gap exists between the feature extraction of evidence and the question, which hinders the model from effectively extracting critical features from the evidence based on the given question. We propose a two-stage framework for evidence retrieval and question-answering to alleviate these issues. First and foremost, we propose a progressive evidence refinement strategy for selecting crucial evidence. This strategy employs an iterative evidence retrieval approach to uncover the logical sequence among the evidence pieces. It incorporates two rounds of filtering to optimize the solution space, thus further ensuring temporal efficiency. Subsequently, we introduce a semi-supervised contrastive learning training strategy based on negative samples to expand the scope of the question domain, allowing for a more thorough exploration of latent knowledge within known samples. Finally, in order to mitigate the loss of fine-grained information, we devise a multi-turn retrieval and question-answering strategy to handle multimodal inputs. This strategy involves incorporating multimodal evidence directly into the model as part of the historical dialogue and question. Meanwhile, we leverage a cross-modal attention mechanism to capture the underlying connections between the evidence and the question, and the answer is generated through a decoding generation approach. We validate the model's effectiveness through extensive experiments, achieving outstanding performance on WebQA and MultimodelQA benchmark tests.
Multi-channel Attentive Graph Convolutional Network With Sentiment Fusion For Multimodal Sentiment Analysis
Jan 25, 2022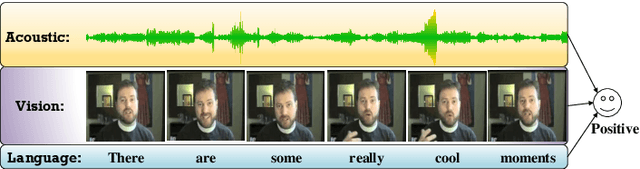
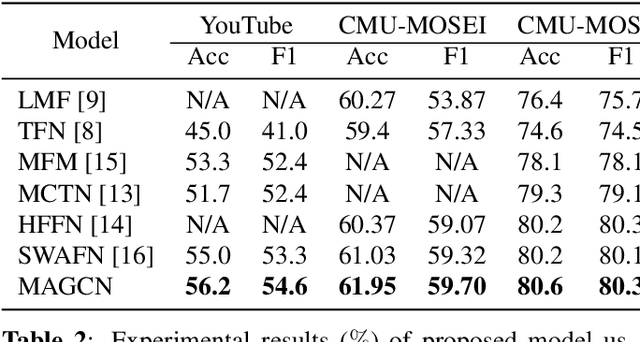
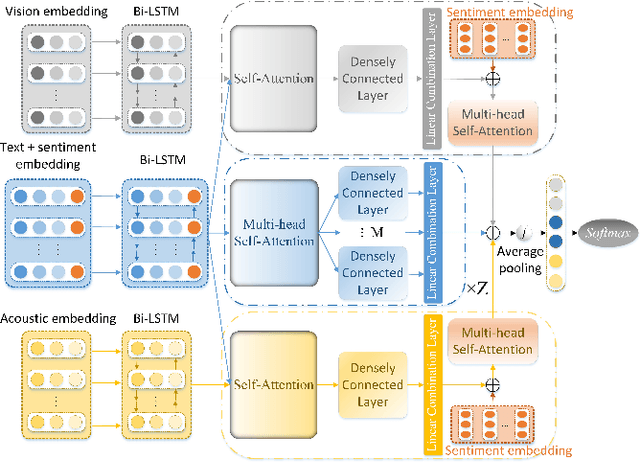
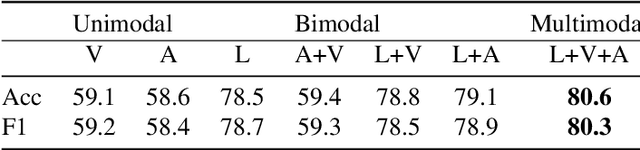
Nowadays, with the explosive growth of multimodal reviews on social media platforms, multimodal sentiment analysis has recently gained popularity because of its high relevance to these social media posts. Although most previous studies design various fusion frameworks for learning an interactive representation of multiple modalities, they fail to incorporate sentimental knowledge into inter-modality learning. This paper proposes a Multi-channel Attentive Graph Convolutional Network (MAGCN), consisting of two main components: cross-modality interactive learning and sentimental feature fusion. For cross-modality interactive learning, we exploit the self-attention mechanism combined with densely connected graph convolutional networks to learn inter-modality dynamics. For sentimental feature fusion, we utilize multi-head self-attention to merge sentimental knowledge into inter-modality feature representations. Extensive experiments are conducted on three widely-used datasets. The experimental results demonstrate that the proposed model achieves competitive performance on accuracy and F1 scores compared to several state-of-the-art approaches.
Cross-Domain Document Layout Analysis via Unsupervised Document Style Guide
Jan 24, 2022
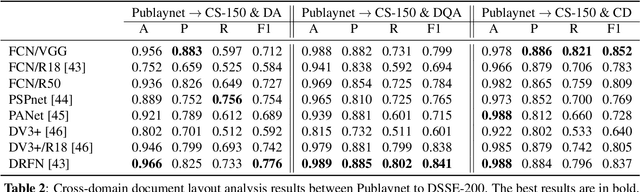
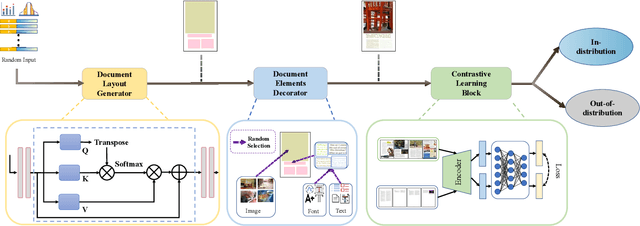
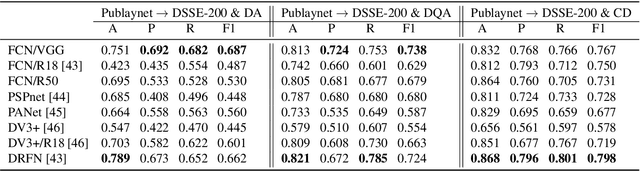
The document layout analysis (DLA) aims to decompose document images into high-level semantic areas (i.e., figures, tables, texts, and background). Creating a DLA framework with strong generalization capabilities is a challenge due to document objects are diversity in layout, size, aspect ratio, texture, etc. Many researchers devoted this challenge by synthesizing data to build large training sets. However, the synthetic training data has different styles and erratic quality. Besides, there is a large gap between the source data and the target data. In this paper, we propose an unsupervised cross-domain DLA framework based on document style guidance. We integrated the document quality assessment and the document cross-domain analysis into a unified framework. Our framework is composed of three components, Document Layout Generator (GLD), Document Elements Decorator(GED), and Document Style Discriminator(DSD). The GLD is used to document layout generates, the GED is used to document layout elements fill, and the DSD is used to document quality assessment and cross-domain guidance. First, we apply GLD to predict the positions of the generated document. Then, we design a novel algorithm based on aesthetic guidance to fill the document positions. Finally, we use contrastive learning to evaluate the quality assessment of the document. Besides, we design a new strategy to change the document quality assessment component into a document cross-domain style guide component. Our framework is an unsupervised document layout analysis framework. We have proved through numerous experiments that our proposed method has achieved remarkable performance.