 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFCoT-VL:Advancing Text-oriented Large Vision-Language Models with Efficient Visual Token Compression
Feb 22, 2025The rapid success of Vision Large Language Models (VLLMs) often depends on the high-resolution images with abundant visual tokens, which hinders training and deployment efficiency. Current training-free visual token compression methods exhibit serious performance degradation in tasks involving high-resolution, text-oriented image understanding and reasoning. In this paper, we propose an efficient visual token compression framework for text-oriented VLLMs in high-resolution scenarios. In particular, we employ a light-weight self-distillation pre-training stage to compress the visual tokens, requiring a limited numbers of image-text pairs and minimal learnable parameters. Afterwards, to mitigate potential performance degradation of token-compressed models, we construct a high-quality post-train stage. To validate the effectiveness of our method, we apply it to an advanced VLLMs, InternVL2. Experimental results show that our approach significantly reduces computational overhead while outperforming the baselines across a range of text-oriented benchmarks. We will release the models and code soon.
EMOVA: Empowering Language Models to See, Hear and Speak with Vivid Emotions
Sep 26, 2024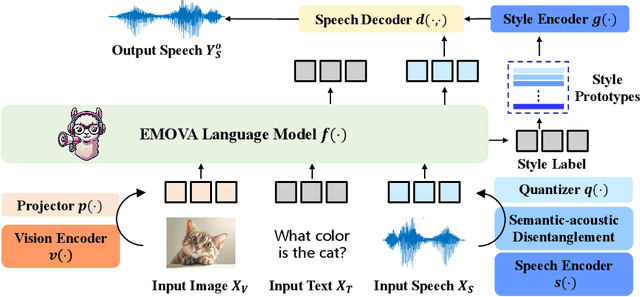
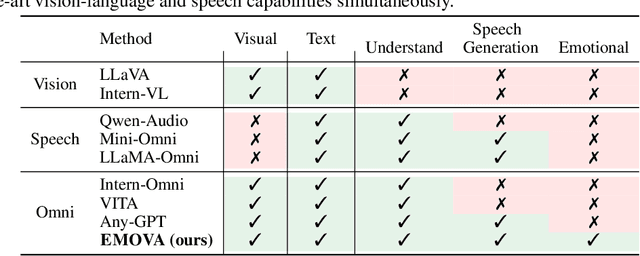
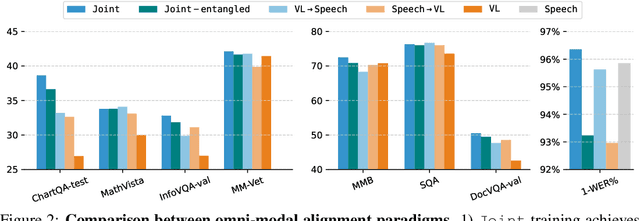

GPT-4o, an omni-modal model that enables vocal conversations with diverse emotions and tones, marks a milestone for omni-modal foundation models. However, empowering Large Language Models to perceive and generate images, texts, and speeches end-to-end with publicly available data remains challenging in the open-source community. Existing vision-language models rely on external tools for the speech processing, while speech-language models still suffer from limited or even without vision-understanding abilities. To address this gap, we propose EMOVA (EMotionally Omni-present Voice Assistant), to enable Large Language Models with end-to-end speech capabilities while maintaining the leading vision-language performance. With a semantic-acoustic disentangled speech tokenizer, we notice surprisingly that omni-modal alignment can further enhance vision-language and speech abilities compared with the corresponding bi-modal aligned counterparts. Moreover, a lightweight style module is proposed for flexible speech style controls (e.g., emotions and pitches). For the first time, EMOVA achieves state-of-the-art performance on both the vision-language and speech benchmarks, and meanwhile, supporting omni-modal spoken dialogue with vivid emotions.
DCQA: Document-Level Chart Question Answering towards Complex Reasoning and Common-Sense Understanding
Oct 29, 2023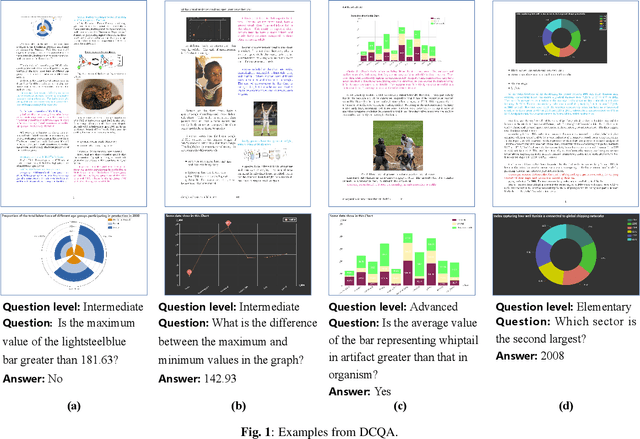
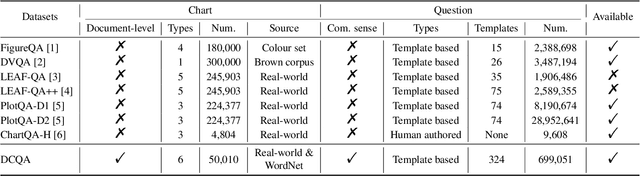
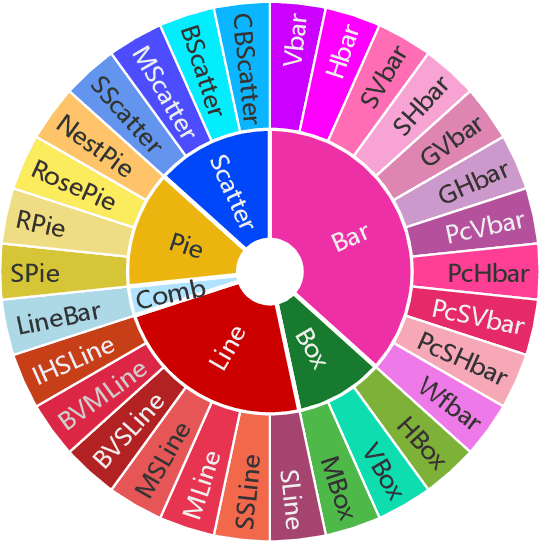

Visually-situated languages such as charts and plots are omnipresent in real-world documents. These graphical depictions are human-readable and are often analyzed in visually-rich documents to address a variety of questions that necessitate complex reasoning and common-sense responses. Despite the growing number of datasets that aim to answer questions over charts, most only address this task in isolation, without considering the broader context of document-level question answering. Moreover, such datasets lack adequate common-sense reasoning information in their questions. In this work, we introduce a novel task named document-level chart question answering (DCQA). The goal of this task is to conduct document-level question answering, extracting charts or plots in the document via document layout analysis (DLA) first and subsequently performing chart question answering (CQA). The newly developed benchmark dataset comprises 50,010 synthetic documents integrating charts in a wide range of styles (6 styles in contrast to 3 for PlotQA and ChartQA) and includes 699,051 questions that demand a high degree of reasoning ability and common-sense understanding. Besides, we present the development of a potent question-answer generation engine that employs table data, a rich color set, and basic question templates to produce a vast array of reasoning question-answer pairs automatically. Based on DCQA, we devise an OCR-free transformer for document-level chart-oriented understanding, capable of DLA and answering complex reasoning and common-sense questions over charts in an OCR-free manner. Our DCQA dataset is expected to foster research on understanding visualizations in documents, especially for scenarios that require complex reasoning for charts in the visually-rich document. We implement and evaluate a set of baselines, and our proposed method achieves comparable results.
Wukong-Reader: Multi-modal Pre-training for Fine-grained Visual Document Understanding
Dec 19, 2022



Unsupervised pre-training on millions of digital-born or scanned documents has shown promising advances in visual document understanding~(VDU). While various vision-language pre-training objectives are studied in existing solutions, the document textline, as an intrinsic granularity in VDU, has seldom been explored so far. A document textline usually contains words that are spatially and semantically correlated, which can be easily obtained from OCR engines. In this paper, we propose Wukong-Reader, trained with new pre-training objectives to leverage the structural knowledge nested in document textlines. We introduce textline-region contrastive learning to achieve fine-grained alignment between the visual regions and texts of document textlines. Furthermore, masked region modeling and textline-grid matching are also designed to enhance the visual and layout representations of textlines. Experiments show that our Wukong-Reader has superior performance on various VDU tasks such as information extraction. The fine-grained alignment over textlines also empowers Wukong-Reader with promising localization ability.