 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFCoT-VL:Advancing Text-oriented Large Vision-Language Models with Efficient Visual Token Compression
Feb 22, 2025The rapid success of Vision Large Language Models (VLLMs) often depends on the high-resolution images with abundant visual tokens, which hinders training and deployment efficiency. Current training-free visual token compression methods exhibit serious performance degradation in tasks involving high-resolution, text-oriented image understanding and reasoning. In this paper, we propose an efficient visual token compression framework for text-oriented VLLMs in high-resolution scenarios. In particular, we employ a light-weight self-distillation pre-training stage to compress the visual tokens, requiring a limited numbers of image-text pairs and minimal learnable parameters. Afterwards, to mitigate potential performance degradation of token-compressed models, we construct a high-quality post-train stage. To validate the effectiveness of our method, we apply it to an advanced VLLMs, InternVL2. Experimental results show that our approach significantly reduces computational overhead while outperforming the baselines across a range of text-oriented benchmarks. We will release the models and code soon.
Speckles-Training-Based Denoising Convolutional Neural Network Ghost Imaging
Apr 07, 2021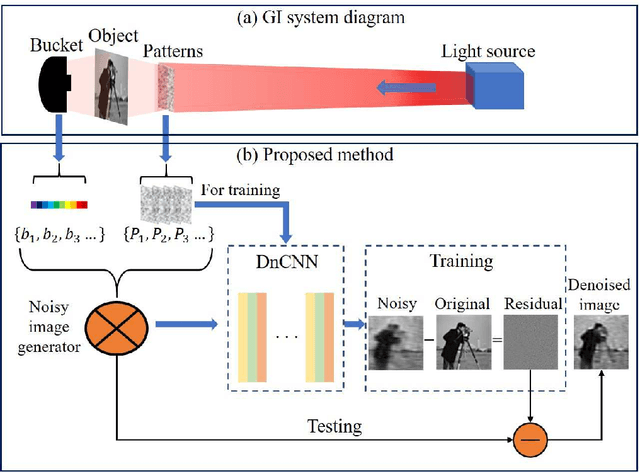
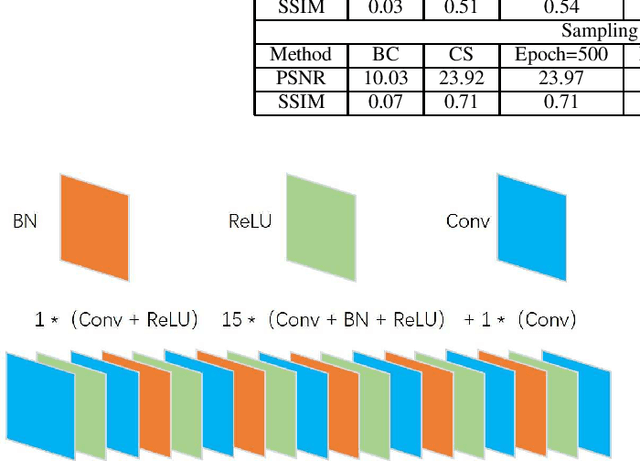

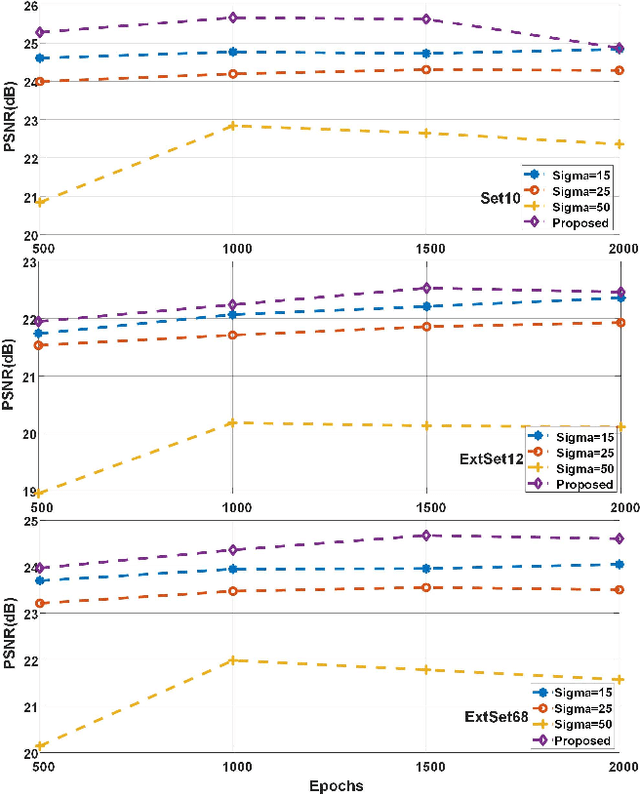
Ghost imaging (GI) has been paid attention gradually because of its lens-less imaging capability, turbulence-free imaging and high detection sensitivity. However, low image quality and slow imaging speed restrict the application process of GI. In this paper, we propose a improved GI method based on Denoising Convolutional Neural Networks (DnCNN). Inspired by the corresponding between input (noisy image) and output (residual image) in DnCNN, we construct the mapping between speckles sequence and the corresponding noise distribution in GI through training. Then, the same speckles sequence is employed to illuminate unknown targets, and a de-noising target image will be obtained. The proposed method can be regarded as a general method for GI. Under two sampling rates, extensive experiments are carried out to compare with traditional GI method (basic correlation and compressed sensing) and DnCNN method on three data sets. Moreover, we set up a physical GI experiment system to verify the proposed method. The results show that the proposed method achieves promising performance.
Generative-Adversarial-Networks-based Ghost Recognition
Mar 25, 2021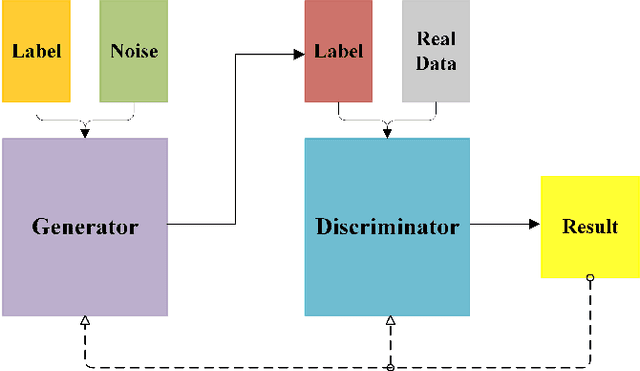
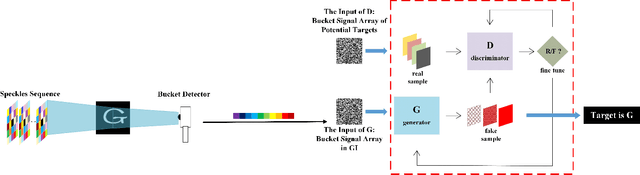
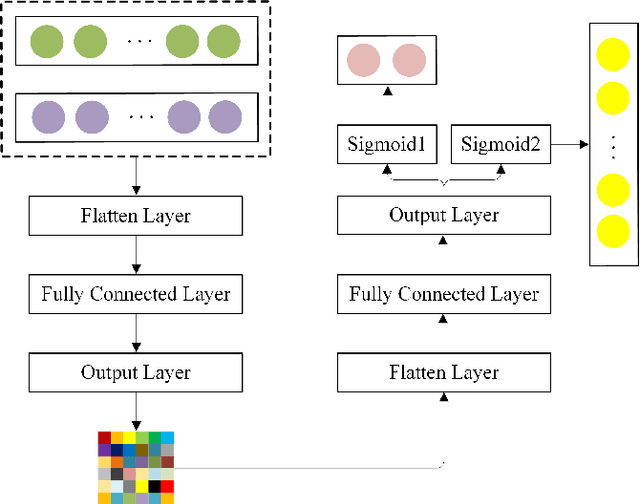

Nowadays, target recognition technique plays an important role in many fields. However, the existing image information based methods suffer from the influence of target image quality. In addition, some methods also need image reconstruction, which will bring additional time cost. In this paper, we propose a novel coincidence recognition method combining ghost imaging (GI) and generative adversarial networks (GAN). Based on the mechanism of GI, a set of random speckles sequence is employed to illuminate target, and a bucket detector without resolution is utilized to receive echo signal. The bucket signal sequence formed after continuous detections is constructed into a bucket signal array, which is regarded as the sample of GAN. Then, conditional GAN is used to map bucket signal array and target category. In practical application, the speckles sequence in training step is still employed to illuminate target, and the bucket signal array is input GAN for recognition. The proposed method can improve the problems caused by existing recognition methods that based on image information, and provide a certain turbulence-free ability. Extensive experiments are show that the proposed method achieves promising performance.