 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-GRPO: Stabilizing Multi-Agent Topology Learning via Group Relative Policy Optimization
Mar 03, 2026Optimizing communication topology is fundamental to the efficiency and effectiveness of Large Language Model (LLM)-based Multi-Agent Systems (MAS). While recent approaches utilize reinforcement learning to dynamically construct task-specific graphs, they typically rely on single-sample policy gradients with absolute rewards (e.g., binary correctness). This paradigm suffers from severe gradient variance and the credit assignment problem: simple queries yield non-informative positive rewards for suboptimal structures, while difficult queries often result in failures that provide no learning signal. To address these challenges, we propose Graph-GRPO, a novel topology optimization framework that integrates Group Relative Policy Optimization. Instead of evaluating a single topology in isolation, Graph-GRPO samples a group of diverse communication graphs for each query and computes the advantage of specific edges based on their relative performance within the group. By normalizing rewards across the sampled group, our method effectively mitigates the noise derived from task difficulty variance and enables fine-grained credit assignment. Extensive experiments on reasoning and code generation benchmarks demonstrate that Graph-GRPO significantly outperforms state-of-the-art baselines, achieving superior training stability and identifying critical communication pathways previously obscured by reward noise.
PromptCD: Test-Time Behavior Enhancement via Polarity-Prompt Contrastive Decoding
Feb 24, 2026Reliable AI systems require large language models (LLMs) to exhibit behaviors aligned with human preferences and values. However, most existing alignment approaches operate at training time and rely on additional high-quality data, incurring significant computational and annotation costs. While recent work has shown that contrastive decoding can leverage a model's internal distributions to improve specific capabilities, its applicability remains limited to narrow behavioral scopes and scenarios. In this work, we introduce Polarity-Prompt Contrastive Decoding (PromptCD), a test-time behavior control method that generalizes contrastive decoding to broader enhancement settings. PromptCD constructs paired positive and negative guiding prompts for a target behavior and contrasts model responses-specifically token-level probability distributions in LLMs and visual attention patterns in VLMs-to reinforce desirable outcomes. This formulation extends contrastive decoding to a wide range of enhancement objectives and is applicable to both LLMs and Vision-Language Models (VLMs) without additional training. For LLMs, experiments on the "3H" alignment objectives (helpfulness, honesty, and harmlessness) demonstrate consistent and substantial improvements, indicating that post-trained models can achieve meaningful self-enhancement purely at test time. For VLMs, we further analyze contrastive effects on visual attention, showing that PromptCD significantly improves VQA performance by reinforcing behavior-consistent visual grounding. Collectively, these results highlight PromptCD as a simple, general, and cost-efficient strategy for reliable behavior control across modalities.
AuTAgent: A Reinforcement Learning Framework for Tool-Augmented Audio Reasoning
Feb 14, 2026Large Audio Language Models (LALMs) excel at perception but struggle with complex reasoning requiring precise acoustic measurements. While external tools can extract fine-grained features like exact tempo or pitch, effective integration remains challenging: naively using all tools causes information overload, while prompt-based selection fails to assess context-dependent utility. To address this, we propose AuTAgent (Audio Tool Agent), a reinforcement learning framework that learns when and which tools to invoke. By employing a sparse-feedback training strategy with a novel Differential Reward mechanism, the agent learns to filter out irrelevant tools and invokes external assistance only when it yields a net performance gain over the base model. Experimental results confirm that AuTAgent complements the representation bottleneck of LALMs by providing verifiable acoustic evidence. It improves accuracy by 4.20% / 6.20% and 9.80% / 8.00% for open-source and closed-source backbones on the MMAU Test-mini and the MMAR benchmarks, respectively. In addition, further experiments demonstrate exceptional transferability. We highlight the complementary role of external tools in augmenting audio model reasoning.
CycleChart: A Unified Consistency-Based Learning Framework for Bidirectional Chart Understanding and Generation
Dec 22, 2025Current chart-specific tasks, such as chart question answering, chart parsing, and chart generation, are typically studied in isolation, preventing models from learning the shared semantics that link chart generation and interpretation. We introduce CycleChart, a consistency-based learning framework for bidirectional chart understanding and generation. CycleChart adopts a schema-centric formulation as a common interface across tasks. We construct a consistent multi-task dataset, where each chart sample includes aligned annotations for schema prediction, data parsing, and question answering. To learn cross-directional chart semantics, CycleChart introduces a generate-parse consistency objective: the model generates a chart schema from a table and a textual query, then learns to recover the schema and data from the generated chart, enforcing semantic alignment across directions. CycleChart achieves strong results on chart generation, chart parsing, and chart question answering, demonstrating improved cross-task generalization and marking a step toward more general chart understanding models.
ProTAL: A Drag-and-Link Video Programming Framework for Temporal Action Localization
May 23, 2025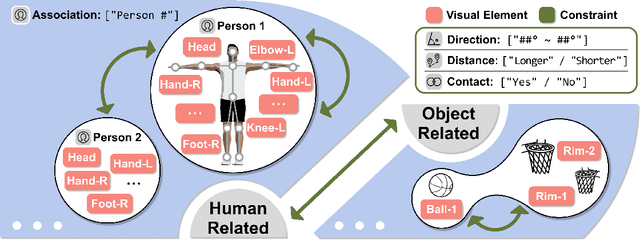
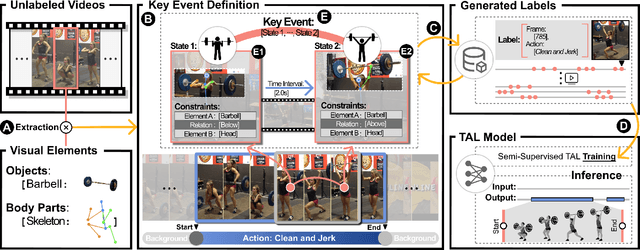
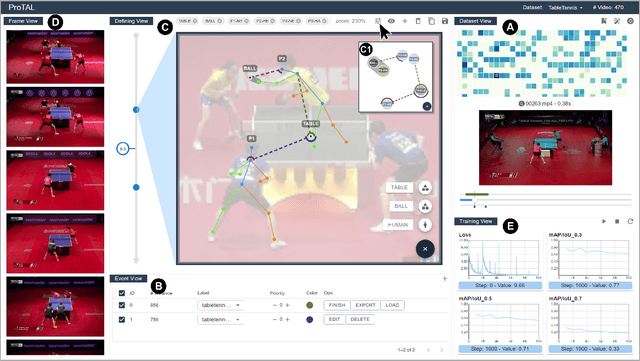
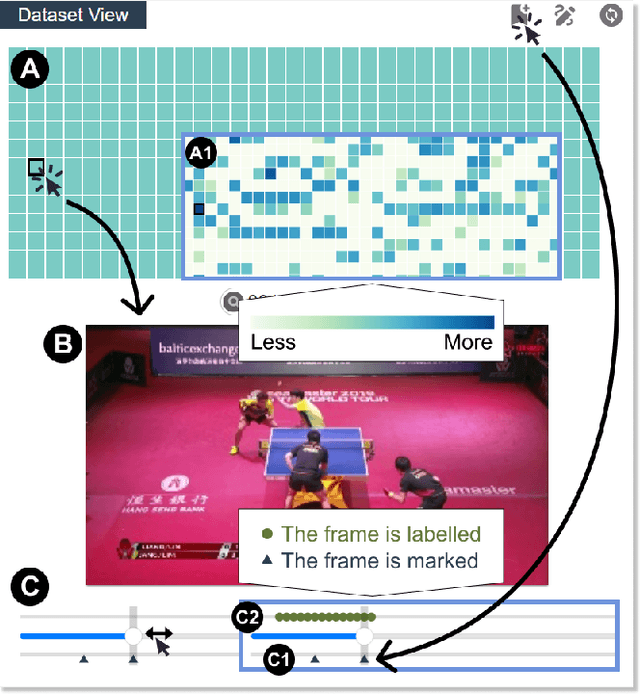
Temporal Action Localization (TAL) aims to detect the start and end timestamps of actions in a video. However, the training of TAL models requires a substantial amount of manually annotated data. Data programming is an efficient method to create training labels with a series of human-defined labeling functions. However, its application in TAL faces difficulties of defining complex actions in the context of temporal video frames. In this paper, we propose ProTAL, a drag-and-link video programming framework for TAL. ProTAL enables users to define \textbf{key events} by dragging nodes representing body parts and objects and linking them to constrain the relations (direction, distance, etc.). These definitions are used to generate action labels for large-scale unlabelled videos. A semi-supervised method is then employed to train TAL models with such labels. We demonstrate the effectiveness of ProTAL through a usage scenario and a user study, providing insights into designing video programming framework.
On the Problem of Best Arm Retention
Apr 16, 2025This paper presents a comprehensive study on the problem of Best Arm Retention (BAR), which has recently found applications in streaming algorithms for multi-armed bandits. In the BAR problem, the goal is to retain $m$ arms with the best arm included from $n$ after some trials, in stochastic multi-armed bandit settings. We first investigate pure exploration for the BAR problem under different criteria, and then minimize the regret with specific constraints, in the context of further exploration in streaming algorithms. - We begin by revisiting the lower bound for the $(\varepsilon,\delta)$-PAC algorithm for Best Arm Identification (BAI) and adapt the classical KL-divergence argument to derive optimal bounds for $(\varepsilon,\delta)$-PAC algorithms for BAR. - We further study another variant of the problem, called $r$-BAR, which requires the expected gap between the best arm and the optimal arm retained is less than $r$. We prove tight sample complexity for the problem. - We explore the regret minimization problem for $r$-BAR and develop algorithm beyond pure exploration. We conclude with a conjecture on the optimal regret in this setting.
On the query complexity of sampling from non-log-concave distributions
Feb 10, 2025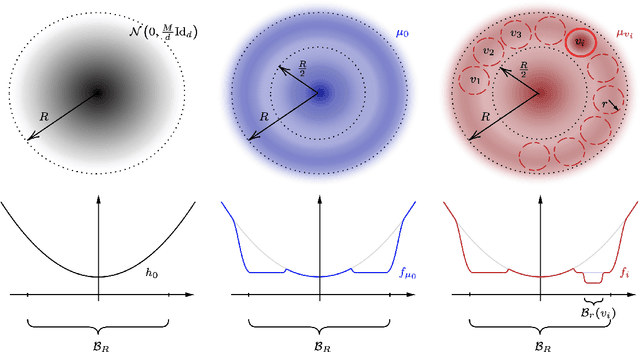

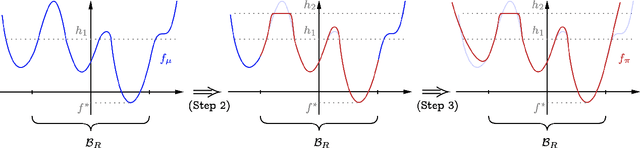
We study the problem of sampling from a $d$-dimensional distribution with density $p(x)\propto e^{-f(x)}$, which does not necessarily satisfy good isoperimetric conditions. Specifically, we show that for any $L,M$ satisfying $LM\ge d\ge 5$, $\epsilon\in \left\{0,\frac{1}{32}\right\}$, and any algorithm with query accesses to the value of $f(x)$ and $\nabla f(x)$, there exists an $L$-log-smooth distribution with second moment at most $M$ such that the algorithm requires $\left\{\frac{LM}{d\epsilon}\right\}^{\Omega(d)}$ queries to compute a sample whose distribution is within $\epsilon$ in total variation distance to the target distribution. We complement the lower bound with an algorithm requiring $\left\{\frac{LM}{d\epsilon}\right\}^{\mathcal O(d)}$ queries, thereby characterizing the tight (up to the constant in the exponent) query complexity for sampling from the family of non-log-concave distributions. Our results are in sharp contrast with the recent work of Huang et al. (COLT'24), where an algorithm with quasi-polynomial query complexity was proposed for sampling from a non-log-concave distribution when $M=\mathtt{poly}(d)$. Their algorithm works under the stronger condition that all distributions along the trajectory of the Ornstein-Uhlenbeck process, starting from the target distribution, are $\mathcal O(1)$-log-smooth. We investigate this condition and prove that it is strictly stronger than requiring the target distribution to be $\mathcal O(1)$-log-smooth. Additionally, we study this condition in the context of mixtures of Gaussians. Finally, we place our results within the broader theme of ``sampling versus optimization'', as studied in Ma et al. (PNAS'19). We show that for a wide range of parameters, sampling is strictly easier than optimization by a super-exponential factor in the dimension $d$.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Towards Automated Model Design on Recommender Systems
Nov 12, 2024The increasing popularity of deep learning models has created new opportunities for developing AI-based recommender systems. Designing recommender systems using deep neural networks requires careful architecture design, and further optimization demands extensive co-design efforts on jointly optimizing model architecture and hardware. Design automation, such as Automated Machine Learning (AutoML), is necessary to fully exploit the potential of recommender model design, including model choices and model-hardware co-design strategies. We introduce a novel paradigm that utilizes weight sharing to explore abundant solution spaces. Our paradigm creates a large supernet to search for optimal architectures and co-design strategies to address the challenges of data multi-modality and heterogeneity in the recommendation domain. From a model perspective, the supernet includes a variety of operators, dense connectivity, and dimension search options. From a co-design perspective, it encompasses versatile Processing-In-Memory (PIM) configurations to produce hardware-efficient models. Our solution space's scale, heterogeneity, and complexity pose several challenges, which we address by proposing various techniques for training and evaluating the supernet. Our crafted models show promising results on three Click-Through Rates (CTR) prediction benchmarks, outperforming both manually designed and AutoML-crafted models with state-of-the-art performance when focusing solely on architecture search. From a co-design perspective, we achieve 2x FLOPs efficiency, 1.8x energy efficiency, and 1.5x performance improvements in recommender models.
* Accepted in ACM Transactions on Recommender Systems. arXiv admin note: substantial text overlap with arXiv:2207.07187
FPPL: An Efficient and Non-IID Robust Federated Continual Learning Framework
Nov 04, 2024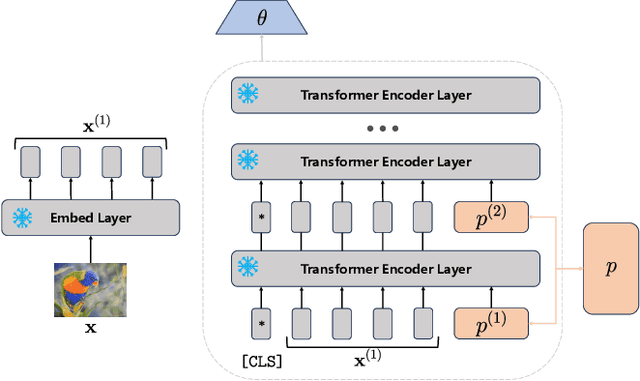
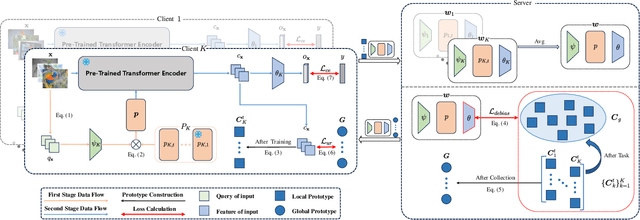
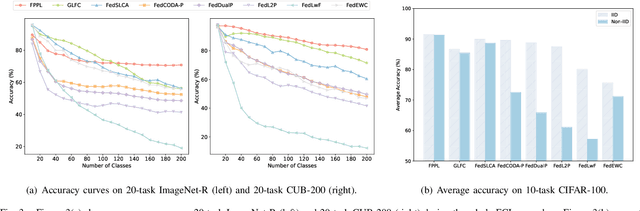
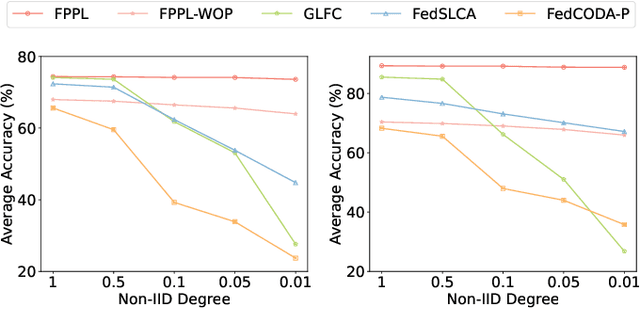
Federated continual learning (FCL) aims to learn from sequential data stream in the decentralized federated learning setting, while simultaneously mitigating the catastrophic forgetting issue in classical continual learning. Existing FCL methods usually employ typical rehearsal mechanisms, which could result in privacy violations or additional onerous storage and computational burdens. In this work, an efficient and non-IID robust federated continual learning framework, called Federated Prototype-Augmented Prompt Learning (FPPL), is proposed. The FPPL can collaboratively learn lightweight prompts augmented by prototypes without rehearsal. On the client side, a fusion function is employed to fully leverage the knowledge contained in task-specific prompts for alleviating catastrophic forgetting. Additionally, global prototypes aggregated from the server are used to obtain unified representation through contrastive learning, mitigating the impact of non-IID-derived data heterogeneity. On the server side, locally uploaded prototypes are utilized to perform debiasing on the classifier, further alleviating the performance degradation caused by both non-IID and catastrophic forgetting. Empirical evaluations demonstrate the effectiveness of FPPL, achieving notable performance with an efficient design while remaining robust to diverse non-IID degrees. Code is available at: https://github.com/ycheoo/FPPL.