 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the query complexity of sampling from non-log-concave distributions
Paper and Code
Feb 10, 2025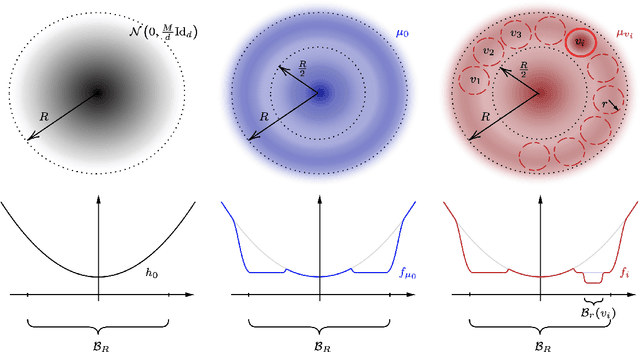

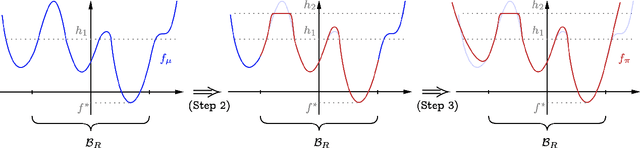
We study the problem of sampling from a $d$-dimensional distribution with density $p(x)\propto e^{-f(x)}$, which does not necessarily satisfy good isoperimetric conditions. Specifically, we show that for any $L,M$ satisfying $LM\ge d\ge 5$, $\epsilon\in \left\{0,\frac{1}{32}\right\}$, and any algorithm with query accesses to the value of $f(x)$ and $\nabla f(x)$, there exists an $L$-log-smooth distribution with second moment at most $M$ such that the algorithm requires $\left\{\frac{LM}{d\epsilon}\right\}^{\Omega(d)}$ queries to compute a sample whose distribution is within $\epsilon$ in total variation distance to the target distribution. We complement the lower bound with an algorithm requiring $\left\{\frac{LM}{d\epsilon}\right\}^{\mathcal O(d)}$ queries, thereby characterizing the tight (up to the constant in the exponent) query complexity for sampling from the family of non-log-concave distributions. Our results are in sharp contrast with the recent work of Huang et al. (COLT'24), where an algorithm with quasi-polynomial query complexity was proposed for sampling from a non-log-concave distribution when $M=\mathtt{poly}(d)$. Their algorithm works under the stronger condition that all distributions along the trajectory of the Ornstein-Uhlenbeck process, starting from the target distribution, are $\mathcal O(1)$-log-smooth. We investigate this condition and prove that it is strictly stronger than requiring the target distribution to be $\mathcal O(1)$-log-smooth. Additionally, we study this condition in the context of mixtures of Gaussians. Finally, we place our results within the broader theme of ``sampling versus optimization'', as studied in Ma et al. (PNAS'19). We show that for a wide range of parameters, sampling is strictly easier than optimization by a super-exponential factor in the dimension $d$.