 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRiskAtlas: Exposing Domain-Specific Risks in LLMs through Knowledge-Graph-Guided Harmful Prompt Generation
Jan 08, 2026Large language models (LLMs) are increasingly applied in specialized domains such as finance and healthcare, where they introduce unique safety risks. Domain-specific datasets of harmful prompts remain scarce and still largely rely on manual construction; public datasets mainly focus on explicit harmful prompts, which modern LLM defenses can often detect and refuse. In contrast, implicit harmful prompts-expressed through indirect domain knowledge-are harder to detect and better reflect real-world threats. We identify two challenges: transforming domain knowledge into actionable constraints and increasing the implicitness of generated harmful prompts. To address them, we propose an end-to-end framework that first performs knowledge-graph-guided harmful prompt generation to systematically produce domain-relevant prompts, and then applies dual-path obfuscation rewriting to convert explicit harmful prompts into implicit variants via direct and context-enhanced rewriting. This framework yields high-quality datasets combining strong domain relevance with implicitness, enabling more realistic red-teaming and advancing LLM safety research. We release our code and datasets at GitHub.
CycleChart: A Unified Consistency-Based Learning Framework for Bidirectional Chart Understanding and Generation
Dec 22, 2025Current chart-specific tasks, such as chart question answering, chart parsing, and chart generation, are typically studied in isolation, preventing models from learning the shared semantics that link chart generation and interpretation. We introduce CycleChart, a consistency-based learning framework for bidirectional chart understanding and generation. CycleChart adopts a schema-centric formulation as a common interface across tasks. We construct a consistent multi-task dataset, where each chart sample includes aligned annotations for schema prediction, data parsing, and question answering. To learn cross-directional chart semantics, CycleChart introduces a generate-parse consistency objective: the model generates a chart schema from a table and a textual query, then learns to recover the schema and data from the generated chart, enforcing semantic alignment across directions. CycleChart achieves strong results on chart generation, chart parsing, and chart question answering, demonstrating improved cross-task generalization and marking a step toward more general chart understanding models.
Linking Heterogeneous Data with Coordinated Agent Flows for Social Media Analysis
Oct 30, 2025Social media platforms generate massive volumes of heterogeneous data, capturing user behaviors, textual content, temporal dynamics, and network structures. Analyzing such data is crucial for understanding phenomena such as opinion dynamics, community formation, and information diffusion. However, discovering insights from this complex landscape is exploratory, conceptually challenging, and requires expertise in social media mining and visualization. Existing automated approaches, though increasingly leveraging large language models (LLMs), remain largely confined to structured tabular data and cannot adequately address the heterogeneity of social media analysis. We present SIA (Social Insight Agents), an LLM agent system that links heterogeneous multi-modal data -- including raw inputs (e.g., text, network, and behavioral data), intermediate outputs, mined analytical results, and visualization artifacts -- through coordinated agent flows. Guided by a bottom-up taxonomy that connects insight types with suitable mining and visualization techniques, SIA enables agents to plan and execute coherent analysis strategies. To ensure multi-modal integration, it incorporates a data coordinator that unifies tabular, textual, and network data into a consistent flow. Its interactive interface provides a transparent workflow where users can trace, validate, and refine the agent's reasoning, supporting both adaptability and trustworthiness. Through expert-centered case studies and quantitative evaluation, we show that SIA effectively discovers diverse and meaningful insights from social media while supporting human-agent collaboration in complex analytical tasks.
NeuroBreak: Unveil Internal Jailbreak Mechanisms in Large Language Models
Sep 04, 2025In deployment and application, large language models (LLMs) typically undergo safety alignment to prevent illegal and unethical outputs. However, the continuous advancement of jailbreak attack techniques, designed to bypass safety mechanisms with adversarial prompts, has placed increasing pressure on the security defenses of LLMs. Strengthening resistance to jailbreak attacks requires an in-depth understanding of the security mechanisms and vulnerabilities of LLMs. However, the vast number of parameters and complex structure of LLMs make analyzing security weaknesses from an internal perspective a challenging task. This paper presents NeuroBreak, a top-down jailbreak analysis system designed to analyze neuron-level safety mechanisms and mitigate vulnerabilities. We carefully design system requirements through collaboration with three experts in the field of AI security. The system provides a comprehensive analysis of various jailbreak attack methods. By incorporating layer-wise representation probing analysis, NeuroBreak offers a novel perspective on the model's decision-making process throughout its generation steps. Furthermore, the system supports the analysis of critical neurons from both semantic and functional perspectives, facilitating a deeper exploration of security mechanisms. We conduct quantitative evaluations and case studies to verify the effectiveness of our system, offering mechanistic insights for developing next-generation defense strategies against evolving jailbreak attacks.
ProTAL: A Drag-and-Link Video Programming Framework for Temporal Action Localization
May 23, 2025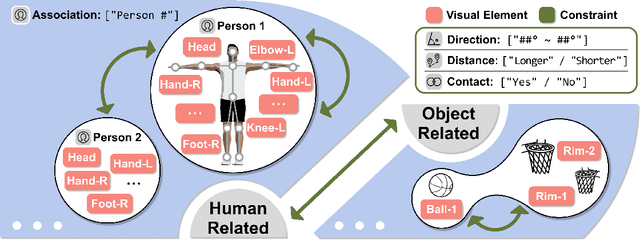
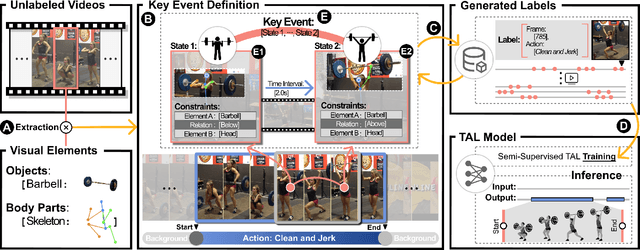
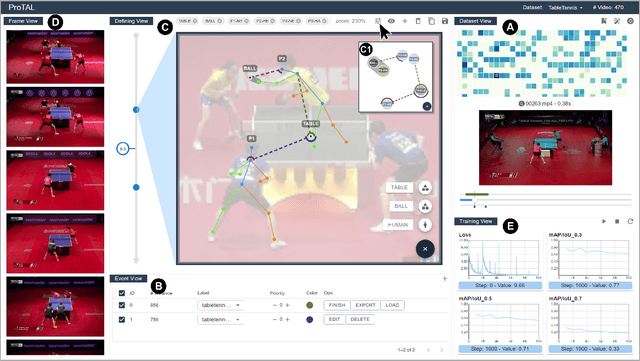
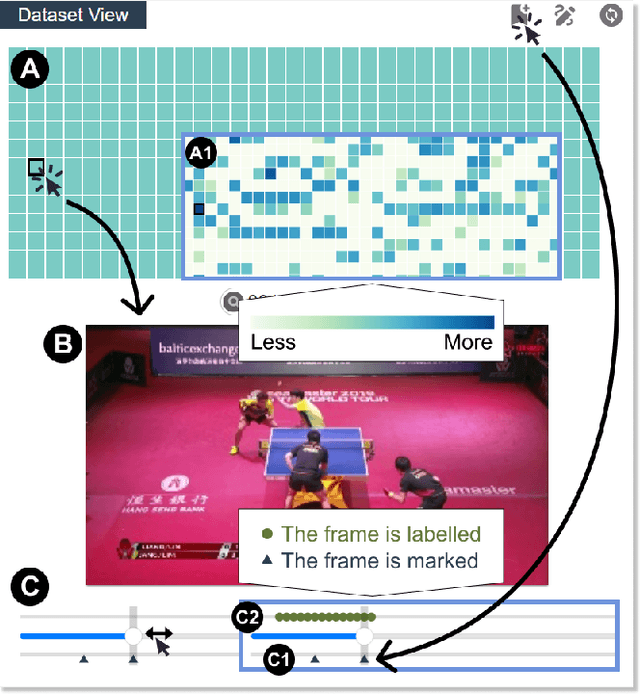
Temporal Action Localization (TAL) aims to detect the start and end timestamps of actions in a video. However, the training of TAL models requires a substantial amount of manually annotated data. Data programming is an efficient method to create training labels with a series of human-defined labeling functions. However, its application in TAL faces difficulties of defining complex actions in the context of temporal video frames. In this paper, we propose ProTAL, a drag-and-link video programming framework for TAL. ProTAL enables users to define \textbf{key events} by dragging nodes representing body parts and objects and linking them to constrain the relations (direction, distance, etc.). These definitions are used to generate action labels for large-scale unlabelled videos. A semi-supervised method is then employed to train TAL models with such labels. We demonstrate the effectiveness of ProTAL through a usage scenario and a user study, providing insights into designing video programming framework.
ReSpark: Leveraging Previous Data Reports as References to Generate New Reports with LLMs
Feb 04, 2025Creating data reports is time-consuming, as it requires iterative exploration and understanding of data, followed by summarizing the insights. While large language models (LLMs) are powerful tools for data processing and text generation, they often struggle to produce complete data reports that fully meet user expectations. One significant challenge is effectively communicating the entire analysis logic to LLMs. Moreover, determining a comprehensive analysis logic can be mentally taxing for users. To address these challenges, we propose ReSpark, an LLM-based method that leverages existing data reports as references for creating new ones. Given a data table, ReSpark searches for similar-topic reports, parses them into interdependent segments corresponding to analytical objectives, and executes them with new data. It identifies inconsistencies and customizes the objectives, data transformations, and textual descriptions. ReSpark allows users to review real-time outputs, insert new objectives, and modify report content. Its effectiveness was evaluated through comparative and user studies.
Navigating the Risks: A Survey of Security, Privacy, and Ethics Threats in LLM-Based Agents
Nov 14, 2024



With the continuous development of large language models (LLMs), transformer-based models have made groundbreaking advances in numerous natural language processing (NLP) tasks, leading to the emergence of a series of agents that use LLMs as their control hub. While LLMs have achieved success in various tasks, they face numerous security and privacy threats, which become even more severe in the agent scenarios. To enhance the reliability of LLM-based applications, a range of research has emerged to assess and mitigate these risks from different perspectives. To help researchers gain a comprehensive understanding of various risks, this survey collects and analyzes the different threats faced by these agents. To address the challenges posed by previous taxonomies in handling cross-module and cross-stage threats, we propose a novel taxonomy framework based on the sources and impacts. Additionally, we identify six key features of LLM-based agents, based on which we summarize the current research progress and analyze their limitations. Subsequently, we select four representative agents as case studies to analyze the risks they may face in practical use. Finally, based on the aforementioned analyses, we propose future research directions from the perspectives of data, methodology, and policy, respectively.
CATP: Context-Aware Trajectory Prediction with Competition Symbiosis
Jul 10, 2024



Contextual information is vital for accurate trajectory prediction. For instance, the intricate flying behavior of migratory birds hinges on their analysis of environmental cues such as wind direction and air pressure. However, the diverse and dynamic nature of contextual information renders it an arduous task for AI models to comprehend its impact on trajectories and consequently predict them accurately. To address this issue, we propose a ``manager-worker'' framework to unleash the full potential of contextual information and construct CATP model, an implementation of the framework for Context-Aware Trajectory Prediction. The framework comprises a manager model, several worker models, and a tailored training mechanism inspired by competition symbiosis in nature. Taking CATP as an example, each worker needs to compete against others for training data and develop an advantage in predicting specific moving patterns. The manager learns the workers' performance in different contexts and selects the best one in the given context to predict trajectories, enabling CATP as a whole to operate in a symbiotic manner. We conducted two comparative experiments and an ablation study to quantitatively evaluate the proposed framework and CATP model. The results showed that CATP could outperform SOTA models, and the framework could be generalized to different context-aware tasks.
ViSTec: Video Modeling for Sports Technique Recognition and Tactical Analysis
Feb 25, 2024The immense popularity of racket sports has fueled substantial demand in tactical analysis with broadcast videos. However, existing manual methods require laborious annotation, and recent attempts leveraging video perception models are limited to low-level annotations like ball trajectories, overlooking tactics that necessitate an understanding of stroke techniques. State-of-the-art action segmentation models also struggle with technique recognition due to frequent occlusions and motion-induced blurring in racket sports videos. To address these challenges, We propose ViSTec, a Video-based Sports Technique recognition model inspired by human cognition that synergizes sparse visual data with rich contextual insights. Our approach integrates a graph to explicitly model strategic knowledge in stroke sequences and enhance technique recognition with contextual inductive bias. A two-stage action perception model is jointly trained to align with the contextual knowledge in the graph. Experiments demonstrate that our method outperforms existing models by a significant margin. Case studies with experts from the Chinese national table tennis team validate our model's capacity to automate analysis for technical actions and tactical strategies. More details are available at: https://ViSTec2024.github.io/.
SUB-PLAY: Adversarial Policies against Partially Observed Multi-Agent Reinforcement Learning Systems
Feb 06, 2024Recent advances in multi-agent reinforcement learning (MARL) have opened up vast application prospects, including swarm control of drones, collaborative manipulation by robotic arms, and multi-target encirclement. However, potential security threats during the MARL deployment need more attention and thorough investigation. Recent researches reveal that an attacker can rapidly exploit the victim's vulnerabilities and generate adversarial policies, leading to the victim's failure in specific tasks. For example, reducing the winning rate of a superhuman-level Go AI to around 20%. They predominantly focus on two-player competitive environments, assuming attackers possess complete global state observation. In this study, we unveil, for the first time, the capability of attackers to generate adversarial policies even when restricted to partial observations of the victims in multi-agent competitive environments. Specifically, we propose a novel black-box attack (SUB-PLAY), which incorporates the concept of constructing multiple subgames to mitigate the impact of partial observability and suggests the sharing of transitions among subpolicies to improve the exploitative ability of attackers. Extensive evaluations demonstrate the effectiveness of SUB-PLAY under three typical partial observability limitations. Visualization results indicate that adversarial policies induce significantly different activations of the victims' policy networks. Furthermore, we evaluate three potential defenses aimed at exploring ways to mitigate security threats posed by adversarial policies, providing constructive recommendations for deploying MARL in competitive environments.