 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCME-CAD: Heterogeneous Collaborative Multi-Expert Reinforcement Learning for CAD Code Generation
Dec 29, 2025Computer-Aided Design (CAD) is essential in industrial design, but the complexity of traditional CAD modeling and workflows presents significant challenges for automating the generation of high-precision, editable CAD models. Existing methods that reconstruct 3D models from sketches often produce non-editable and approximate models that fall short of meeting the stringent requirements for precision and editability in industrial design. Moreover, the reliance on text or image-based inputs often requires significant manual annotation, limiting their scalability and applicability in industrial settings. To overcome these challenges, we propose the Heterogeneous Collaborative Multi-Expert Reinforcement Learning (CME-CAD) paradigm, a novel training paradigm for CAD code generation. Our approach integrates the complementary strengths of these models, facilitating collaborative learning and improving the model's ability to generate accurate, constraint-compatible, and fully editable CAD models. We introduce a two-stage training process: Multi-Expert Fine-Tuning (MEFT), and Multi-Expert Reinforcement Learning (MERL). Additionally, we present CADExpert, an open-source benchmark consisting of 17,299 instances, including orthographic projections with precise dimension annotations, expert-generated Chain-of-Thought (CoT) processes, executable CADQuery code, and rendered 3D models.
Quda: Natural Language Queries for Visual Data Analytics
May 13, 2020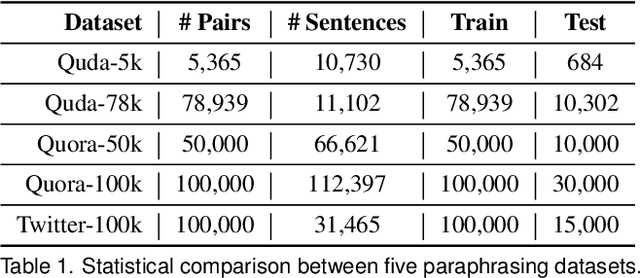
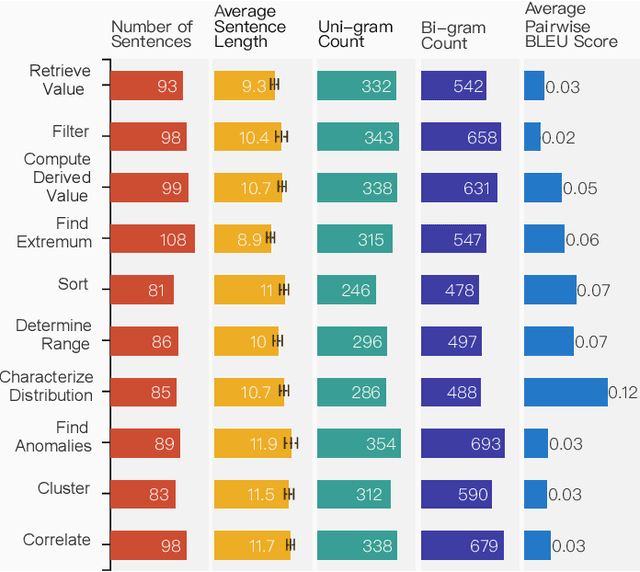
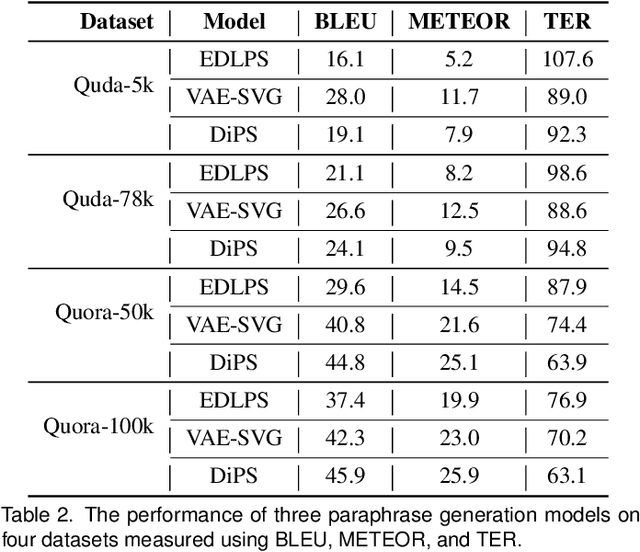
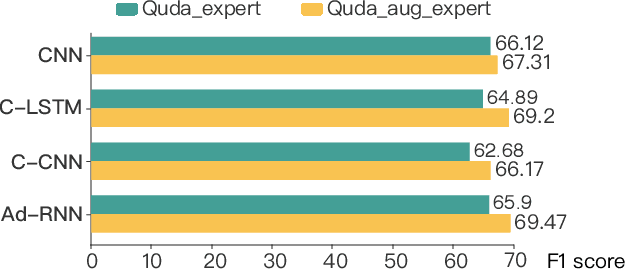
Visualization-oriented natural language interfaces (V-NLIs) have been explored and developed in recent years. One challenge faced by V-NLIs is in the formation of effective design decisions that usually requires a deep understanding of user queries. Learning-based approaches have shown potential in V-NLIs and reached state-of-the-art performance in various NLP tasks. However, because of the lack of sufficient training samples that cater to visual data analytics, cutting-edge techniques have rarely been employed to facilitate the development of V-NLIs. We present a new dataset, called Quda, to help V-NLIs understand free-form natural language. Our dataset contains 14;035 diverse user queries annotated with 10 low-level analytic tasks that assist in the deployment of state-of-the-art techniques for parsing complex human language. We achieve this goal by first gathering seed queries with data analysts who are target users of V-NLIs. Then we employ extensive crowd force for paraphrase generation and validation. We demonstrate the usefulness of Quda in building V-NLIs by creating a prototype that makes effective design decisions for free-form user queries. We also show that Quda can be beneficial for a wide range of applications in the visualization community by analyzing the design tasks described in academic publications.